







好久不见,这里依旧是代班的工人~

可能不是很想。。。emmm。。。没关系。。。
最近越学越发觉自己懂得好少。。。
但是最近又好忙好忙。。。
不过如今你们看到了这篇文章,说明我还是挺过来了!鼓掌~
(虽然不知道能不能挺过下周)
那么,趁着我还活着,这次还是带来基础算法的知识
秉持着大神来回顾,小白来学习的原则
让我们开始这期的学习吧!
目录
01.减治法
02.分治法
03.变治法

01
减 治 法
decrease-and-conquer method
普卢塔克说,萨特斯为了告诉他的士兵坚忍和智慧比蛮力更重要的道理,把两匹马带到他们面前,然后让两个人拔光马的尾毛。一个人是魁梧的大力士,他用力地拔了又拔,但一点效果也没有;另一个人是一个精美的、长相矫捷的裁缝,他微笑着,每次拔掉一根毛,很快就把尾巴拔得光秃秃的。
——E. Cobham Brewer,《惯用语和寓言词典》,1898
减治法(decrease-and-conquer method)
减治法采取划分后选择计算的思想,利用一个问题和同样较小规模的问题之间的某种关系进行划分。我们先确立这种关系,然后既可以从顶至下,也可以从底至上地来运用该关系,将大问题分解成小问题来解决,像是层层嵌套。在实际解决的过程中只针对部分子问题进行求解。
减治法有3种主要的变种:
1.减去一个常量 (decrease by a constant)
2.减去一个常数因子(decrease by a constant factor)
3.减去的规模是可变的(variable size decrease)
1.减去一个常量 (decrease by a constant)
在减常量变种中,我们每次从问题规模中减去一个规模相同的常量。(一般来说,这个常量等于一)
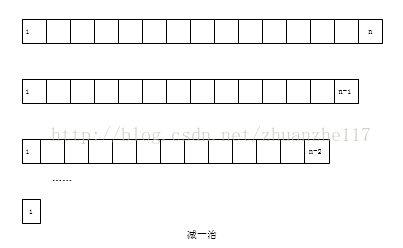
(CSDN盗图,别介意~)
函数f(n) = a^n的求解过程就是一个栗子:

在这里,虽然算法的时间复杂度和蛮力法一致,但是体现的思想却不一样。
其他的栗子还有:
深度优先、广度优先查找,拓扑排序等。这里对拓扑排序稍加介绍。
拓扑排序是指:对一个有向无环图G进行排序,将G中所有顶点排成一个一维线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前(起点在终点之前)。
运用减治法思想的步骤:
1.在有向图中选一个没有前驱的顶点,输出;
2.删除所有和它有关的边;
3.重复上述两步,直至所有顶点输出。
(每次我们只减去常量1,因此当有多个点没有前驱时,只需要随意挑选一个点输出)
比如这样一个图:
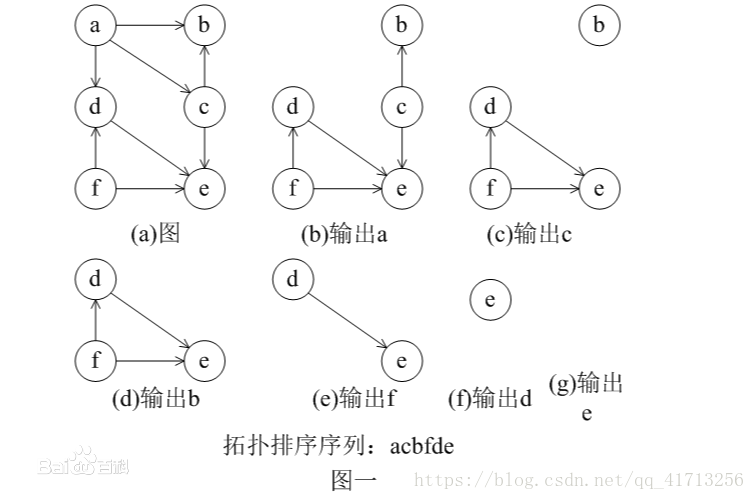
再比如这样一个图(其实是同一个图啦):
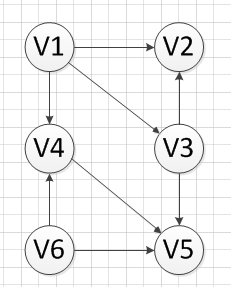
我们最终会得到这样的序列:
v6—>v1—>v4—>v3—>v5—>v2;
当然,类似这样的序列也是正确的:
v1—>v6—>v4—>v3—>v5—>v2;
v1—>v3—>v6—>v4—>v5—>v2。。。
这里是要强调选择的随机性。这完全由代码决定。
没什么大问题,下面就到了激动人心的代码环节:
//拓扑排序:寻找图中入度为0的顶点作为即将遍历的顶点,遍历完后,将此顶点从图中删除 #include using namespace std; int adjMatrix[105][105];//参数adjMatrix:邻接矩阵 int source [105]; // 参数source:给出图的每个顶点的入度值 int n,m; //给出图的顶点、边个数 void getSourceSort( ){
int count = 0; //用于计算当前遍历的顶点个数 bool judge = true; while(judge) {
for(int i = 1;i <= n;i++) {
if(source[i] == 0) //当第i个顶点入度为0时,遍历该顶点 { count++; if (count "; if(count==n)cout< source[i] = -1; //代表第i个顶点已被遍历 for(int j = 1;j <= n;j++) //寻找第i个顶点的出度顶点 {
if(adjMatrix[i][j] == 1) source[j] -= 1; //第j个顶点的入度减1 } } } if(count == n) judge = false; } } //返回给出图每个顶点的入度值 void getSource( ){
for(int i = 1;i <= n;i++) //若邻接矩阵中第i列含有k个1,则在该列的节点的入度为k,即source[i] = k { int count = 0; for(int j = 1;j <= n;j++) {
if(adjMatrix[j][i] == 1) count++; } source[i] = count; } } int main(){
int a,b; cin>>n>>m; for(int i = 1;i <= n;i++) //初始化邻接矩阵 for(int j = 1;j <= n;j++) adjMatrix[i][j] =0; for(int i = 1;i <= m;i++) {
cin>>a>>b; adjMatrix[a][b] = 1; } getSource(); getSourceSort( ); return 0;}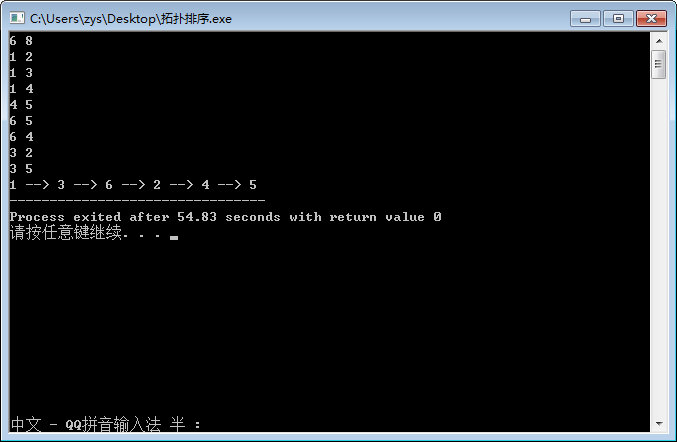
2.减去一个常数因子(decrease by a constant factor)
减去常数因子实际上就是把规模除以一个常数。(在多数情况下,这个常数因子是二)
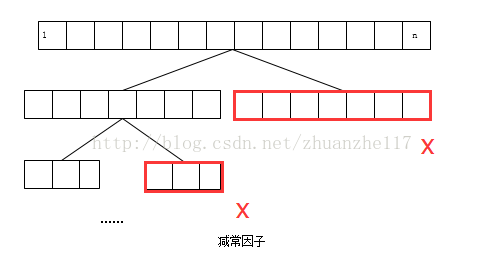
继续以计算f(n)=a^n为栗:
 这里的时间复杂度为O (log n),就比蛮力法优化多了。
这里的时间复杂度为O (log n),就比蛮力法优化多了。
对分查找,假币问题都可以用这种思想。我们以假币问题为例:
有n枚银币,其中有1枚是假的,假币重量偏重、偏轻未知,输入银币的重量,求假币的位置。
我们先取出一枚银币作为对照,再将银币分为两半称重,每次称重对比,再从有问题的一堆中继续称重查找。这样,每次我们都减去了常量因子2。
当然,银币总数是奇偶时需要不同的处理方式,在银币数量为偶数时,由于不知道假币偏轻或偏重,我们需要选择一个compare进行对照。
同时,我们还可以把银币分为三堆考虑,进一步优化时间复杂度。(作为代价,代码要考虑总数mode3余1、2、0的情况,同时要比较三堆,会稍稍复杂一些)
Codding time:
//三分法求八枚银币问题#include using namespace std;int coin[105],num;int sum(int left, int right){
int sum = 0; for (int i = left; i <= right; i++) sum += coin[i]; return sum;}int findfake(int left, int right){
int n=right-left+1; int p1=(right+left)/3; int p2=p1*2; int sign = n % 3; if (sign == 0) {
int fake = 0; int A, B, C; A = sum(left,p1); B = sum(p1+1,p2); C = sum(p2+1,right); if (n == 3) {
if (A  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









