






AdaRNN: Adaptive Learning and Forecasting for Time Series(CIKM 2021)

Summary
作者认为时序数据的统计特性随时间而变化,导致分布也随时间而变化。也就是不同时间段可能分布不同。这种情况叫做分布漂移(Distribution Shift)。作者针对时间序列分布的动态变化特性,提出了时间序列的时序协方差漂移问题(Temporal Covariate Shift, TCS)。为此提出了AdaRNN,主要包含两个模块,TDC(Temporal Distribution Characterization)用来分割时间序列,尽可能让分割出来的分布差异大。TDM(Temporal Distribution Matching)则是减少时间序列中的分布不匹配,学习一种基于RNN的自适应时间序列预测模型。
Problem Statement
时间序列的非平稳特性意味着数据分布随时间而变化,如下图
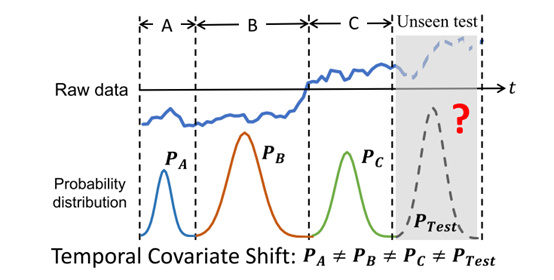
可以看到随时间变化数据的分布也在不断变化,同时由于测试集部分的分布是不可见的这使得模型效果更差。分布在发生变化但是条件分布P(y|x)通常认为是不变的。例如在股票预测中,市场波动是很自然的(P(x)),但经济规律却没有改变(P(y|x))。为此作者给出定义:
时序协方差漂移,给定一个时间序列 D \mathcal{D} D,假设它被分为了K个时段, D = { D 1 , ⋯ , D K } \mathcal{D}=\left\{\mathcal{D}_{1}, \cdots, \mathcal{D}_{K}\right\} D={D1,⋯,DK}, D k = { x i , y i } i = n k + 1 n k + 1 \mathcal{D}_{k}=\left\{\mathbf{x}_{i}, \mathbf{y}_{i}\right\}_{i=n_{k}+1}^{n_{k+1}} Dk={xi,yi}i=nk+1nk+1 。时序协方差漂移表示在一个时间片段里数据据有相同的数据分布,但是在不同的时间片段里,数据分布不同,但是具有相同的条件分布,即 P D i ( x ) ≠ P D j ( x ) P_{\mathcal{D}_{i}}(\mathbf{x}) \neq P_{\mathcal{D}_{j}}(\mathbf{x}) PDi(x)=PDj(x) 和 P D i ( y ∣ x ) = P D j ( y ∣ x ) P_{\mathcal{D}_{i}}(y \mid \mathbf{x})=P_{\mathcal{D}_{j}}(y \mid \mathbf{x}) PDi(y∣x)=PDj(y∣x)。
因此为了学习到一个好的预测模型,去学习在不同分段中共有的知识是非常重要的。
问题定义:给定一个n个片段时间序列,表示为 D = { x i , y i } i = 1 n \mathcal{D}=\left\{\mathbf{x}_{i}, \mathbf{y}_{i}\right\}_{i=1}^{n} D={xi,yi}i=1n,其中 x i = { x i 1 , ⋯ , x i m i } ∈ R p × m i \mathbf{x}_{i}=\left\{x_{i}^{1}, \cdots, x_{i}^{m_{i}}\right\} \in \mathbb{R}^{p \times m_{i}} xi={xi1,⋯,ximi}∈Rp×mi表示含有p个特征时序都为 m i m_i mi的历史数据, y i = ( y i 1 , . . . , y i c ) ∈ R c y_i=(y_i^1, ..., y_i^c) \in \mathbb{R}^c yi=(yi1,...,yic)∈Rc表示标签。假设存在一个K,将时间序列划分为K段使得同一段有相同的数据分布,不同段具有不同的数据分布。学习一个预测模型 M : x i → y i \mathcal{M}: \mathrm{x}_{i} \rightarrow \mathrm{y}_{i} M:xi→yi,预测未来r步。作者希望可以通过在训练集中各个不同分布的数据中学习到,不同分布中不变的知识,以此来在未知分布测试集中得到一个良好的表现。
Method(s)
框架图,如下,可以分为两部分,第一部分是TDC用于描述分布的信息,具体的就是将训练数据划分为分布差距最大的K段。第二部分是TDM用于匹配发现的周期的分布来构建时间序列预测模型,也就是想办法学习一个具有时序不变性的模型(学习一个适用于各个分布的模型)。
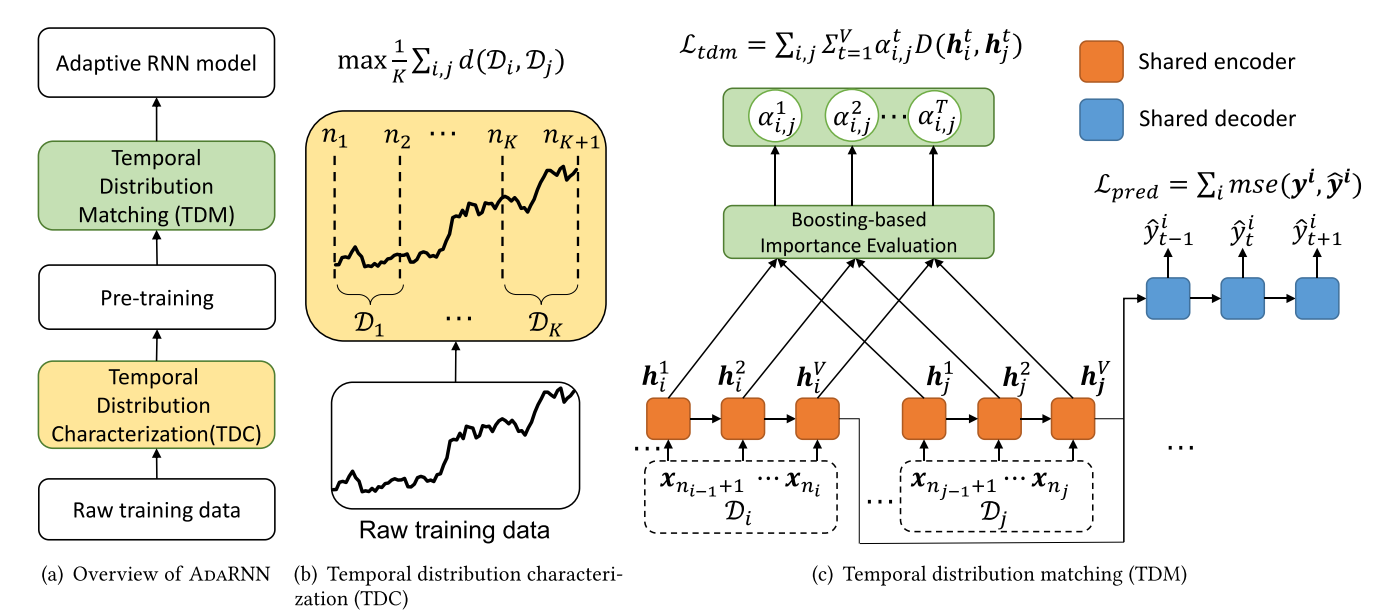
TDC
为了最大限度学习到时序协方差漂移中的共享知识,寻找彼此最不相似的时段,让跨时段的分布最多样化(由于对测试数据没有先验信息,训练时看不到这些信息,所以在最坏的情况下训练一个模型更合理)。TDC通过求解一个优化问题来实现TS拆分的目标,其目标可以表示为:
max
0
<
K
≤
K
0
max
n
1
,
⋯
,
n
K
1
K
∑
1
≤
i
≠
j
≤
K
d
(
D
i
,
D
j
)
s.t.
∀
i
,
Δ
1
<
∣
D
i
∣
<
Δ
2
;
∑
i
∣
D
i
∣
=
n
\begin{gathered} \max _{0<K \leq K_{0}} \max _{n_{1}, \cdots, n_{K}} \frac{1}{K} \sum_{1 \leq i \neq j \leq K} d\left(\mathcal{D}_{i}, \mathcal{D}_{j}\right) \\ \text { s.t. } \forall i, \Delta_{1}<\left|\mathcal{D}_{i}\right|<\Delta_{2} ; \sum_{i}\left|\mathcal{D}_{i}\right|=n \end{gathered}
0<K≤K0maxn1,⋯,nKmaxK11≤i=j≤K∑d(Di,Dj) s.t. ∀i,Δ1<∣Di∣<Δ2;i∑∣Di∣=n
d表示分布之间的距离度量(作者使用cosine距离,MMD,对抗距离), Δ 1 \Delta_{1} Δ1, Δ 2 \Delta_{2} Δ2, K 0 K_0 K0是预定义的参数来避免无效的解,上述优化问题可以用动态规划算法 (Dynamic Programming)进行高效求解。为了追求效率最后作者使用贪心算法求解,大致就是一个一个时段分隔点往里加,保证加每一个分隔点是都是最优的。
TDM
TDM模块通过匹配的分布的方式学习不同时段共有的知识。该模块的预测loss定义为
L
pred
(
θ
)
=
1
K
∑
j
=
1
K
1
∣
D
j
∣
∑
i
=
1
∣
D
j
∣
ℓ
(
y
i
j
,
M
(
x
i
j
;
θ
)
)
\mathcal{L}_{\text {pred }}(\theta)=\frac{1}{K} \sum_{j=1}^{K} \frac{1}{\left|\mathcal{D}_{j}\right|} \sum_{i=1}^{\left|\mathcal{D}_{j}\right|} \ell\left(\mathrm{y}_{i}^{j}, \mathcal{M}\left(\mathrm{x}_{i}^{j} ; \theta\right)\right)
Lpred (θ)=K1j=1∑K∣Dj∣1i=1∑∣Dj∣ℓ(yij,M(xij;θ))
ℓ(·, ·)就表示MSE,这部分就是非常常见的预测和真实结果之间的差距得到的loss。
如果只最小化上述loss,模型只能学习到每一个时段的预测知识,不能减少分布差异,学习到共同知识。而目前域自适应方法的分布匹配都常常用在表征结果中,所以作者在将分布匹配用到了RNN模型的最后输入中。使用
H
=
{
h
t
}
t
=
1
V
∈
R
V
×
q
\mathbf{H}=\left\{\mathbf{h}^{t}\right\}_{t=1}^{V} \in \mathbb{R}^{V \times q}
H={ht}t=1V∈RV×q表示RNN的V个隐藏状态,特征维度是q。时段之间的在最后隐藏状态的分布匹配可以被表示为:
L
d
m
(
D
i
,
D
j
;
θ
)
=
d
(
h
i
V
,
h
j
V
;
θ
)
\mathcal{L}_{d m}\left(\mathcal{D}_{i}, \mathcal{D}_{j} ; \theta\right)=d\left(\mathbf{h}_{i}^{V}, \mathbf{h}_{j}^{V} ; \theta\right)
Ldm(Di,Dj;θ)=d(hiV,hjV;θ)
但是这个只用到了RNN输出中最后一个隐藏状态,所以作者又构造了一种考虑V个隐藏状态的分布匹配。并提出一个重要性向量
α
\alpha
α(利用到了一种基于Boosting,这部分没有细看)来学习V个隐藏状态的重要性。最后分布匹配loss可以被表示为
L
t
d
m
(
D
i
,
D
j
;
θ
)
=
∑
t
=
1
V
α
i
,
j
t
d
(
h
i
t
,
h
j
t
;
θ
)
\mathcal{L}_{t d m}\left(\mathcal{D}_{i}, \mathcal{D}_{j} ; \theta\right)=\sum_{t=1}^{V} \alpha_{i, j}^{t} d\left(\mathbf{h}_{i}^{t}, \mathbf{h}_{j}^{t} ; \theta\right)
Ltdm(Di,Dj;θ)=t=1∑Vαi,jtd(hit,hjt;θ)
最后将两种loss结合如下
L
(
θ
,
α
)
=
L
p
r
e
d
(
θ
)
+
λ
2
K
(
K
−
1
)
∑
i
,
j
i
≠
j
L
t
d
m
(
D
i
,
D
j
;
θ
,
α
)
\mathcal{L}(\theta, \boldsymbol{\alpha})=\mathcal{L}_{p r e d}(\theta)+\lambda \frac{2}{K(K-1)} \sum_{i, j}^{i \neq j} \mathcal{L}_{t d m}\left(\mathcal{D}_{i}, \mathcal{D}_{j} ; \theta, \boldsymbol{\alpha}\right)
L(θ,α)=Lpred(θ)+λK(K−1)2i,j∑i=jLtdm(Di,Dj;θ,α)
注意第二项将计算训练集中所有分布之间的距离平均值,在计算分布之间的距离时,对于一个分布,作者使用mini-batch来执行RNN的操作,然后将所有隐藏特征组合,然后计算分布之间的距离。
最后训练整个过程如下

Evaluation
实验设置:RNN模型使用GRU。在四个数据集上进行实验,

对比了四类方法,如下:
传统的时序模型:ARIMA,GRU
最新的时序模型:LSTNet,STRIPE
没有mask操作的transformer
域自适应方法的变体:MMD-RNN,DANN-RNN
UCI时序分类问题结果,作者效果最好:

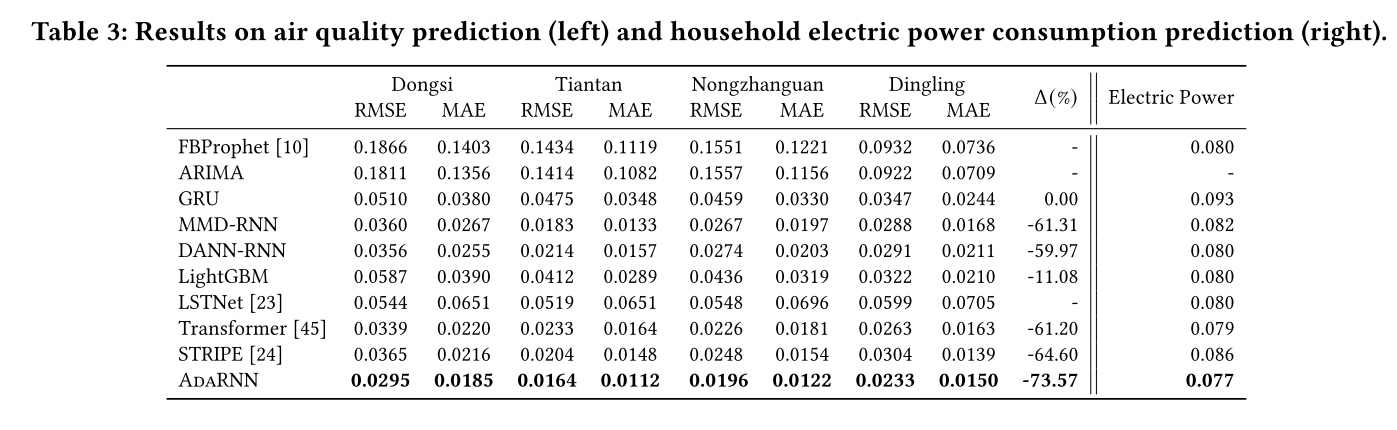
空气质量预测和电力预测(RMSE)
股票预测

消融实验
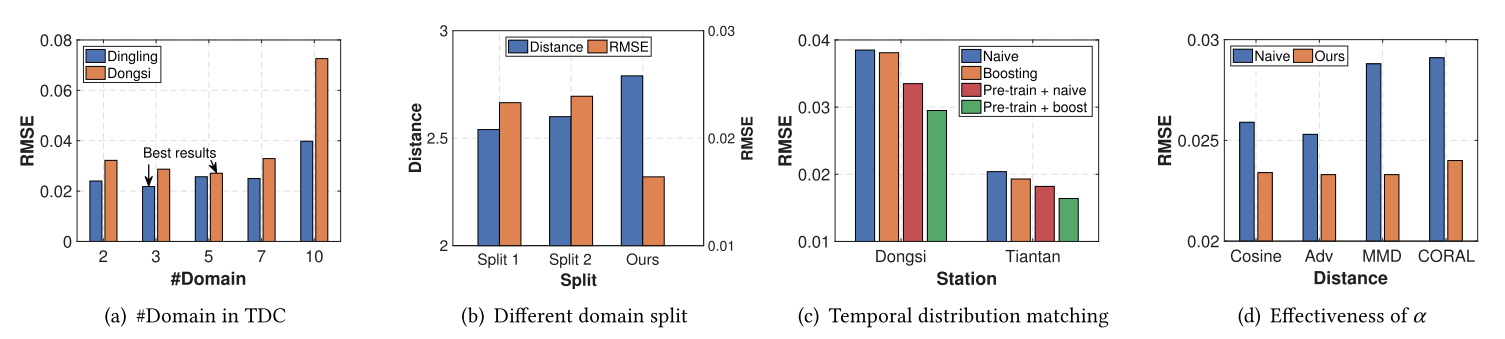
对于时序相似性量化部分
K不同取值时的效果如图a。随着K值的增加,模型性能先变好再逐渐变差。
不同划分策略效果如图b,划分1表示随机划分,划分2表示按最相似性进行划分。发布距离越大时RMSE性能越好。
对于时序分布匹配部分
算法的变种及效果如图c,重要性 α \alpha α的效果评估如图d。
收敛性和复杂度分析实验如下
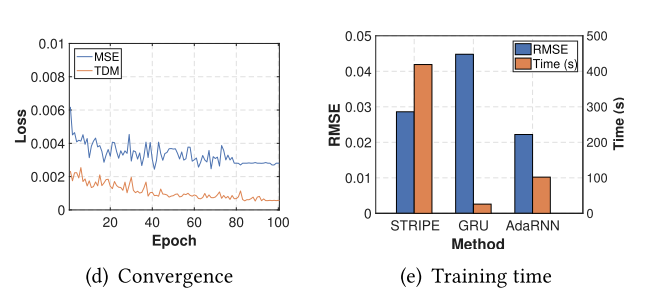
除这些外还有度量分布距离指标的实验,多步预测效果实验。
最后还有一个预测效果对比图
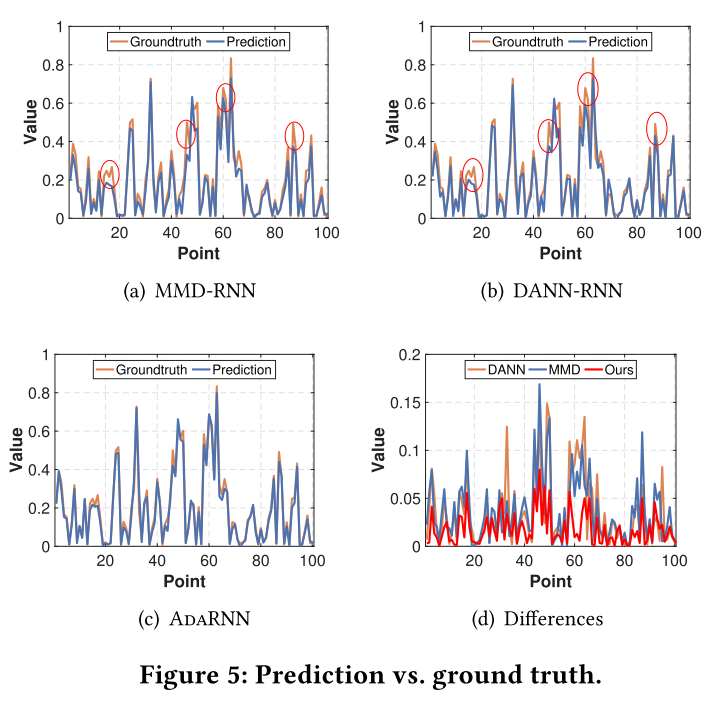
另外作者的这个基于迁移学习的方法也是可以用于transformer的,效果如下

Notes
非常有意思的一篇论文,作者发现时序预测中与迁移学习中类似的东西,并把迁移学习的方法结合到时序预测里。感觉他第一部分分割时序比较重要,然后部分则主要是加了一个让嵌入得到的表示分布相同的loss函数。代码code















 3264
3264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











