







如果你现在了解了神经网络的工作原理,已经构建了一个猫狗分类器。尝试了一个半体面的字符级 RNN。
pip install tensorflow离建造终结者只有一步之遥了,对吧?错误的。
机器学习模因

深度学习的一个非常重要的部分是找到正确的超参数,这些是模型无法学习的数字。
在本文中,我将带您了解在通往 Kaggle 排行榜第一名的道路上会遇到的一些最常见(也是最重要)的超参数。此外,我还将向您展示一些强大的算法,可以帮助您明智地选择超参数。
深度学习中的超参数
超参数可以被认为是模型的调整旋钮。
如果您将 AV 接收器设置为立体声,那么带有低音炮的精美 7.1 杜比全景声家庭影院系统会产生超出人耳可听范围的低音。
打开立体声放大器

类似地,如果您的超参数关闭,则具有一万亿个参数的 inception_v3 甚至无法让您通过 MNIST。
所以现在,在我们进入如何拨入正确的设置之前,让我们先看看要调整的旋钮。
学习率
可以说是最重要的超参数,即学习率,粗略地说,它控制着你的神经网络“学习”的速度。
那么我们为什么不把它放大并在快车道上过上生活呢?

没那么简单。请记住,在深度学习中,我们的目标是最小化损失函数。如果学习率太高,我们的损失将开始到处跳跃并且永远不会收敛。

如果学习率太小,模型将需要很长时间才能收敛,如上图所示。
Momentum
由于本文侧重于超参数优化,因此我不会解释动量的整个概念。但简而言之,动量常数可以被认为是滚下损失函数表面的球的质量。
球越重,下落得越快。但是如果它太重,它可能会卡住或超过目标。

Dropout
如果您在这里感觉到一个主题,我现在将引导您阅读Amar Budhiraja的关于辍学的文章。

但作为快速复习,dropout 是 Geoff Hinton 提出的一种正则化技术,它随机将神经网络中的激活值设置为 0,概率为p. 这有助于防止神经网络过度拟合(记忆)数据而不是学习数据。
p是一个超参数。
架构——层数、每层神经元等。
另一个(相当近期的)想法是使神经网络本身的架构成为超参数。
尽管我们通常不会让机器弄清楚我们模型的架构(否则 AI 研究人员会失去工作),但一些新技术(如神经架构搜索)已经实现了这一想法,并取得了不同程度的成功。
如果您听说过AutoML,那么 Google 基本上就是这样做的:将所有内容设为超参数,然后在问题上投入 10 亿个 TPU,让它自行解决。
但是对于我们中的绝大多数只想在黑色星期五促销后拼凑起来的预算机器对猫和狗进行分类的人来说,现在是时候找出如何使这些深度学习模型真正起作用的时候了。
超参数优化算法
网格搜索
这是获得良好超参数的最简单方法。这实际上只是蛮力。
算法:从一组给定的超参数中尝试一堆超参数,看看哪个效果最好。
优点:对于五年级学生来说实施起来很容易。可以很容易地并行化。
缺点:正如您可能猜到的那样,它的计算成本非常高(就像所有蛮力方法一样)。
我应该使用它吗:可能不会。网格搜索非常低效。即使您想保持简单,最好还是使用随机搜索。
随机搜索
这一切都在名称中 - 随机搜索。随机。
算法:从某个超参数空间上的均匀分布中尝试一堆随机超参数,看看哪种效果最好。
优点:可以很容易地并行化。就像网格搜索一样简单,但性能要好一些,如下图所示:

缺点:虽然它提供了比网格搜索更好的性能,但它仍然是计算密集型的。
我应该使用它:如果微不足道的并行化和简单性是最重要的,那就去吧。但是,如果您能节省时间和精力,使用贝叶斯优化将获得丰厚的回报。
贝叶斯优化
与我们目前看到的其他方法不同,贝叶斯优化使用算法先前迭代的知识。通过网格搜索和随机搜索,每个超参数猜测都是独立的。但是使用贝叶斯方法,每次我们选择并尝试不同的超参数时,都会朝着完美迈进。

贝叶斯超参数调整背后的想法很长而且细节丰富。所以为了避免太多的兔子洞,我会在这里给你要点。但是一定要阅读一般的高斯过程和贝叶斯优化,如果这是你感兴趣的事情。
请记住,我们使用这些超参数调整算法的原因是单独评估多个超参数选择是不可行的。例如,假设我们想手动找到一个好的学习率。这将涉及设置学习率、训练模型、评估模型、选择不同的学习率、再次从头开始训练模型、重新评估模型,然后循环继续。
问题是,“训练你的模型”可能需要几天时间(取决于问题的复杂性)才能完成。因此,在会议的论文提交截止日期到来之前,您只能尝试一些学习率。你知道吗,你甚至还没有开始玩这种势头。哎呀。

算法:贝叶斯方法试图建立一个函数(更准确地说,在可能的函数的概率分布),其估计有多好你的模型可能是超参数的必然选择。通过使用这个近似函数(在文献中称为代理函数),您不必经过多次设置、训练、评估循环,因为您只需将超参数优化到代理函数即可。
举个例子,假设我们想要最小化这个函数(把它想象成模型损失函数的代理):

代理函数来自一种称为高斯过程的东西(注意:还有其他方法可以模拟代理函数,但我将使用高斯过程)。就像,我提到过,我不会做任何数学繁重的推导,但这里所有关于贝叶斯和高斯的讨论归结为:
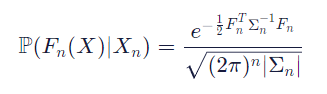
左侧告诉您涉及概率分布(考虑到花哨的外观的存在) \mathbb{P}磷)。查看括号内,我们可以看到它是一个概率分布Fn(X),这是一些任意函数。为什么?因为请记住,我们正在定义所有可能函数的概率分布,而不仅仅是一个特定的函数。从本质上讲,左侧表示将超参数映射到模型指标(如验证准确率、对数似然、测试错误率等)的真实函数的概率为Fn ( X ),给定一些样本数据 Xn 等于右边的任何东西。
现在我们有了要优化的函数,我们对其进行优化。
在我们开始优化过程之前,高斯过程如下所示:

使用您最喜欢的优化器选择(专业人士喜欢最大化预期改进),但不知何故,只需遵循符号(或梯度),然后在不知不觉中,您最终会达到局部最小值。
经过几次迭代,高斯过程在逼近目标函数方面变得更好:

无论您使用哪种方法,您现在都已找到 代理函数的 argmin 。令人惊讶的是,那些最小化代理函数的参数是(估计)最优超参数!好极了。
最终结果应如下所示:

使用这些“最佳”超参数在您的神经网络上进行训练,您应该会看到一些改进。但是您也可以使用这些新信息一次又一次地重做整个贝叶斯优化过程。随意运行贝叶斯循环,无论你想要多少次,但要小心。你实际上是在计算东西。您知道,这些 AWS 积分不是免费提供的。还是他们……
**优点:**贝叶斯优化比网格搜索和随机搜索提供更好的结果。
**缺点:**并行化并不容易。
**我应该使用它:**在大多数情况下,是的!唯一的例外是如果
- 您是深度学习专家,不需要微不足道的近似算法的帮助。
- 您可以访问大量计算资源,并且可以大规模并行化网格搜索和随机搜索。
- 如果你是一个常客/反贝叶斯统计书呆子。
寻找良好学习率的另一种方法
到目前为止,在我们所见的所有方法中,都有一个基本主题:使机器学习工程师的工作自动化。这是伟大的一切; 直到您的老板得知此事并决定用 4 张 RTX Titan 卡代替您。呵呵。猜猜你应该坚持手动搜索。

但是不要绝望,在让研究人员做得更少同时获得更多报酬的领域中,有一些积极的研究。其中一个非常有效的想法是学习率范围测试,据我所知,它首先出现在Leslie Smith的一篇论文中。
该论文实际上是关于一种随时间调度(改变)学习率的方法。LR(学习率)范围测试是笔者随手丢在一边的金块。
当您使用学习率从最小值到最大值变化的学习率计划时,例如循环学习率或带热重启的随机梯度下降,作者建议在每次迭代后线性增加学习率,从小到大大值(例如1e-7to 1e-1),评估每次迭代的损失,并在对数刻度上针对学习率绘制损失(或测试错误或准确性)。你的情节应该是这样的:

正如图中标记的那样,然后您将使用设置学习率计划在最小和最大学习率之间反弹,这是通过查看图并尝试观察梯度最陡的区域来找到的。
这是我们 Colab笔记本中的示例 LR 范围测试图(在 CIFAR10 上训练的 DenseNet):

根据经验,如果您没有做任何花哨的学习率计划,只需将您的恒定学习率设置为低于图中最小值的数量级。在这种情况下,大约是1e-2.
这种方法最酷的部分,除了它工作得非常好并且节省了你用其他算法找到好的超参数所需的时间、精力和计算之外,它几乎不需要额外的计算。
虽然其他算法,即网格搜索、随机搜索和贝叶斯优化,要求您运行与训练良好神经网络目标相切的整个项目,但 LR 范围测试只是执行一个简单的、常规的训练循环,并保持在此过程中跟踪一些变量。
以下是使用最佳学习率时可以预期的收敛速度类型(来自笔记本中的示例):

LR 范围测试已由fast.ai团队实现,您绝对应该查看他们的库以轻松实现 LR 范围测试(他们称之为学习率查找器)以及许多其他算法。
结论
在本文中,我们讨论了超参数以及一些优化它们的方法。但这一切意味着什么?
随着我们越来越努力地使 AI 技术大众化,自动超参数调整可能是朝着正确方向迈出的一步。它允许像你我这样的普通人在没有数学博士学位的情况下构建令人惊叹的深度学习应用程序。
虽然您可能会争辩说,让模型渴望计算能力,但最好的模型还是掌握在那些负担得起所述计算能力的人手中,AWS 和 Nanonets 等云服务有助于使对强大机器的访问民主化,从而使深度学习更容易获得。
但更根本的是,我们实际上在这里使用数学来解决更多数学问题。这很有趣,不仅因为它听起来多么元,还因为它很容易被误解。

从打孔卡和跟踪表的时代到我们优化功能优化功能优化功能的时代,我们当然已经走了很长一段路。但是我们离制造可以自己“思考”的机器还差得很远。
这并不令人沮丧,至少不是,因为如果人类可以用这么少的东西做这么多,想象一下未来会怎样,当我们的愿景变成我们可以真正看到的东西时。
所以我们坐在一张带软垫的网椅上,盯着空白的终端屏幕,每一次按键都给我们一种sudo超能力,可以把磁盘擦干净。
所以我们坐在那里,我们整天坐在那里,因为下一个重大突破可能就在pip install咫尺之遥。
















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









