







transfuse 医学分割
原论文地址:
https://doi.org/10.48550/arXiv.2102.08005
背景
卷积神经网络 (CNN) 在众多医学图像分割任务中取得了无与伦比的性能,例如多器官分割、肝脏病变分割、大脑 3D MRI 等,因为它被证明在构建分层结构方面非常强大通过端到端训练网络来实现特定于任务的特征表示。
尽管基于 CNN 的方法取得了巨大成功,但它在捕获全局上下文信息方面缺乏效率仍然是一个挑战。感知全局信息的机会等于效率的风险,因为现有工作通过生成非常大的感受野来获取全局信息,这需要连续下采样和堆叠卷积层直到足够深。这带来了几个缺点:
1)非常深的网络的训练受到特征重用递减问题的影响[23],其中低级特征被连续乘法洗掉;
2)随着空间分辨率逐渐降低,对密集预测任务(例如逐像素分割)至关重要的局部信息被丢弃;
3)用小型医学图像数据集训练参数重的深度网络往往不稳定且容易过拟合。
一些研究使用非局部自注意力机制来模拟全局上下文;然而,这些模块的计算复杂度通常随空间大小呈二次方增长,因此它们可能仅适用于低分辨率地图。
Transformer 最初用于对 NLP 任务中的序列到序列预测进行建模 [26],最近在计算机视觉界引起了极大的兴趣。 [7] 中提出了第一个基于自注意力的图像识别视觉转换器 (ViT),它在 ImageNet [6] 上获得了具有竞争力的结果,前提是在大型外部数据集上进行了预训练。 SETR [32] 在传统的基于编码器解码器的网络中用转换器替换了编码器,从而成功地在自然图像分割任务上实现了最先进的 (SOTA) 结果。虽然 Transformer 擅长对全局上下文进行建模,但它在捕获细粒度细节方面显示出局限性,尤其是对于医学图像。我们独立地发现,由于在建模局部信息时缺乏空间归纳偏差(也在 [4] 中报告),因此类似 SETR 的纯基于变压器的分割网络产生了不令人满意的性能。
为了享受这两者的好处,已经努力将 CNN 与 Transformer 相结合,例如 TransUnet [4],它首先利用 CNN 提取低级特征,然后通过 Transformer 对全局交互进行建模。结合跳跃连接,TransUnet 在 CT 多器官分割任务中创造了新的记录。然而,过去的工作主要集中在用 Transformer 层代替卷积或将两者按顺序堆叠。为了进一步释放 CNN 和 Transformer 在医学图像分割中的力量,在本文中,我们提出了一种不同的架构——TransFuse,它并行运行基于浅层 CNN 的编码器和基于变压器的分割网络,然后是我们提出的 BiFusion 模块,其中的特征来自两个分支的融合在一起共同做出预测。
TransFuse 具有以下几个优点:
(1) 可以有效捕获低级空间特征和高级语义上下文;
(2)它不需要很深的网络,这缓解了梯度消失和特征减少的重用问题;
(3)它大大提高了模型大小和推理速度的效率,不仅可以在云端部署,还可以在边缘部署。
据我们所知,TransFuse 是第一个合成 CNN 和 Transformer 的并行分支模型。实验证明了与其他竞争 SOTA 作品相比的优越性能。
网络简介
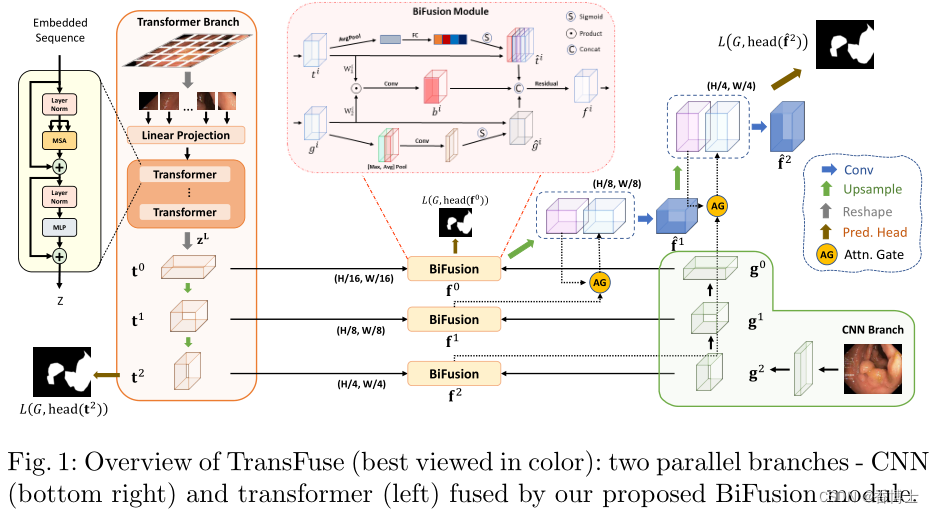
如图1所示,TransFuse由两个并行的分支组成,处理信息的方式不同:1)CNN分支,逐渐增加感受野并将特征从局部编码到全局; 2) Transformer 分支,从全局自注意力开始,最后恢复局部细节。从两个分支中提取的具有相同分辨率的特征被输入到我们提出的 BiFusion 模块中,其中应用自注意力和双线性 Hadamard 产品来选择性地融合信息。然后,结合多级融合特征图,使用门控跳跃连接[20]生成分割。
提出的并行分支方法的两个主要好处是:首先,通过利用 CNN 和 Transformer 的优点,我们认为 TransFuse 可以在不构建非常深的网络的情况下捕获全局信息,同时保持对低级上下文的敏感性;其次,我们提出的 BiFusion 模块可以在特征提取过程中同时利用 CNN 和 Transformer 的不同特性,从而使融合表示功能强大且紧凑。
transformer分支
Transformer 分支的设计遵循典型的编码器-解码器架构。具体来说,首先将输入图像 x ∈ RH×W ×3 均匀划分为 N = H S × W S 块,其中 S 通常设置为 16。然后将块展平并传递到输出维度为 D0 的线性嵌入层,得到原始嵌入序列 e ∈ RN×D0。为了利用空间先验,将相同维度的可学习位置嵌入添加到 e。生成的嵌入 z0 ∈ RN×D0 是 Transformer 编码器的输入,它包含 L 层多头自注意力 (MSA) 和多层感知器 (MLP)。我们强调作为 Transformer 的核心原理的自我注意 (SA) 机制通过在每一层全局聚合信息来更新每个嵌入补丁的状态:
















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









