







 本文探讨了大模型评测的重要性,介绍了OpenCompass的开源特性与评测方法,包括客观评价(如困惑度评测和生成式评测)和主观评价(依赖人类主观感受)。同时,文章涵盖了多模态评测工具的应用,旨在全面评估大模型的性能和适用性。
本文探讨了大模型评测的重要性,介绍了OpenCompass的开源特性与评测方法,包括客观评价(如困惑度评测和生成式评测)和主观评价(依赖人类主观感受)。同时,文章涵盖了多模态评测工具的应用,旨在全面评估大模型的性能和适用性。
一.笔记
1.为什么进行大模型评测
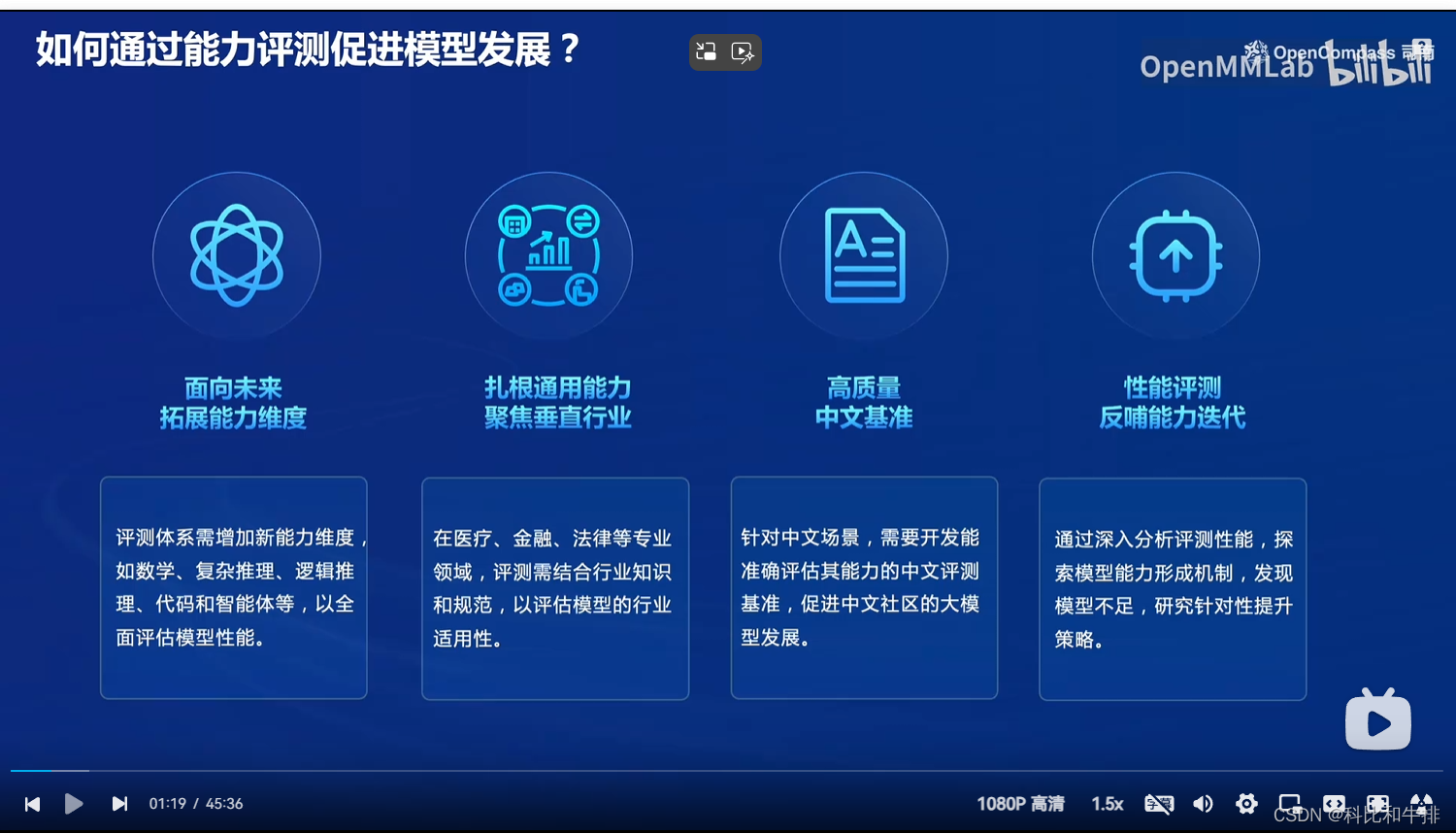
通过评测来推动大模型的发展,通过各个维度的评测来检验大模型在不同方面的优缺点,在垂直领域来评测模型的适用性和专业性
2.大模型评测面临的挑战

3.什么是OpenCompass

OpenCompass中文名称司南,主要特点有:开源可复现、全面的能力维度、丰富的模型支持、分布式高效评测、多样化评测范式、灵活化拓展

4.opencompass的评测方法
客观评价
针对目标:具有标准答案的客观问题。可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。
由于大语言模型输出自由度较高,在评测阶段,我们需要对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响,才能对模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









