







参考 廖雪峰-字符串和编码
https://blog.csdn.net/weixin_41789688/article/details/116787795
Unicode编码详解(一):Unicode简介及其分类
首先计算机内部只能识别数字,在底层就是0,1编码。比如:不论是数字100,还是字符 今天,在底层都是1010 1000 1010 这种形式的二进制代码
二进制:
二进制只有0,1两种状态,所以只需要一个二进制位(也就是一个比特位)就可以表示二进制数。
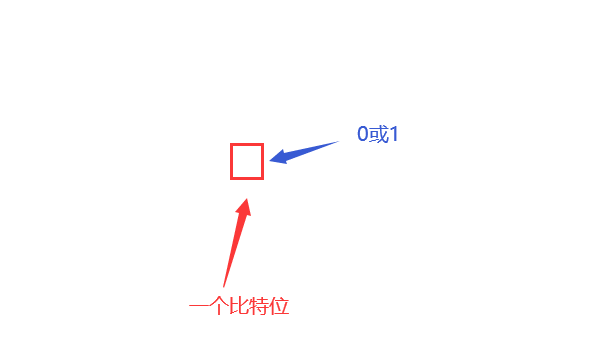
八进制:
八进制有八种状态:0,1,2,3,4,5,6,7
八种状态需要三个比特位才能表示 000–111
所以一个八进制数占了三个比特,比如 7 表示出来就是三个比特位111才能表示
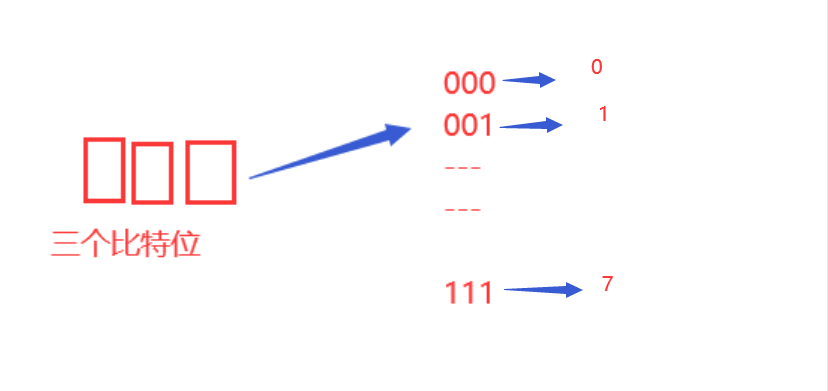
十六进制:
十六进制有16种状态: 0-9,A-F
十六中状态可以用四个比特位表示 0000-1111。
所以一个十六进制数,对应着4个比特位。
假设汉字一共只有16种,我们让每一个汉字对应着一个数字(0-15),用十六进制表示就是
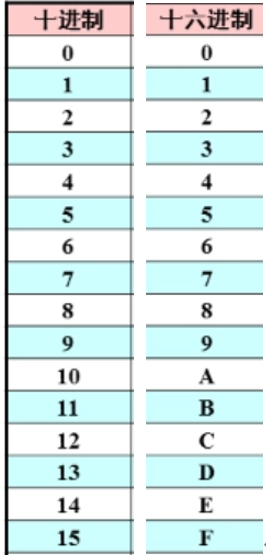
这些十六进制数,在计算机内可以用比特位来表示出来,所以这样中文的文本就可以在计算机中表示了。
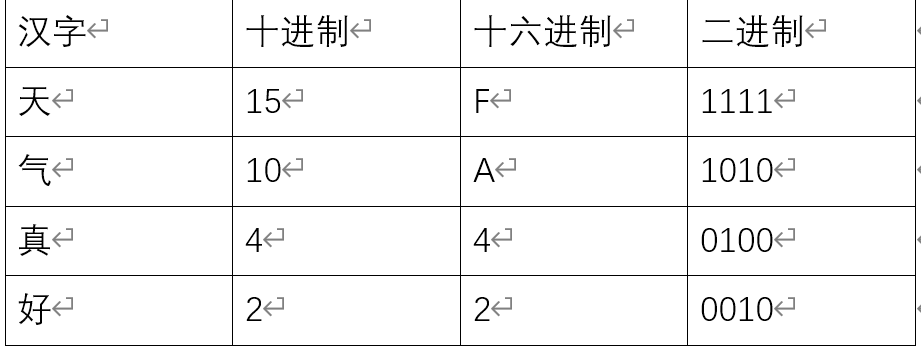
所以 天气真好 在计算机中就表示成了 1111 1010 0100 0010
基于这种想法,由于计算机是美国人发明的,所以他们也想让计算机可以表示出他们的语言。对于英语来说,26个大写字母,26个小写字母,10个数字,加上其他的一些符号,他们一共就127个字符,所以他们建立了一个对应关系:
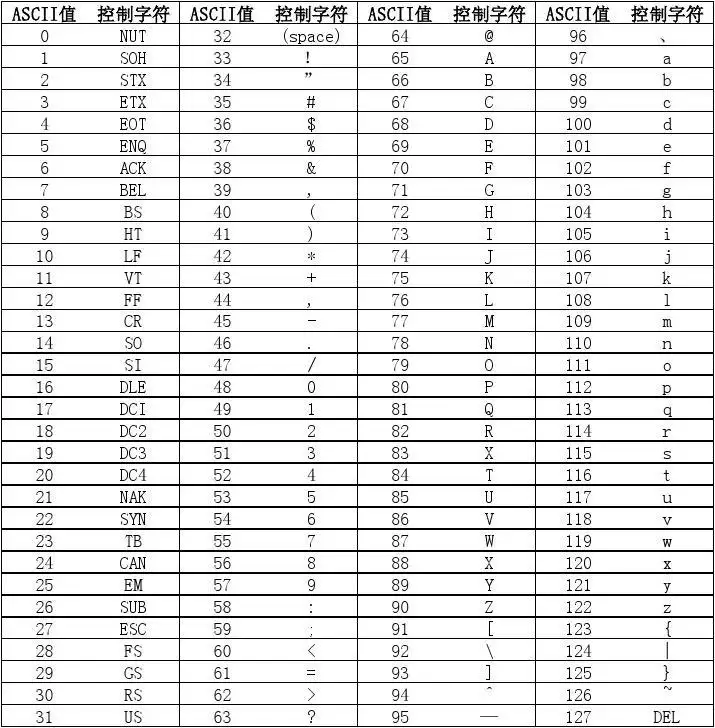
这就是ascii码表,一共128个字符,使用一个字节(xxxx xxxx)就可以完全表示这些字符。一个字节能表示的最大的整数就是255(二进制11111111=十进制255),就是255种状态,表示128种状态肯定是够了。
汉语中有那么多个汉字,算上各种繁体字,大概几万个吧,这些字符仅仅使用一个字节是不够的。比如两个字节可以表示的最大整数是65535。
但是现在这么多国家都在使用计算机,不同国家字符不同,所以不同的国家又自己制定了自己需要的一张表。
假如说现在用两个字节(0—65535)来表示这些字符。除去一些通用的字符(数字,符号之类的),然后不同的国家需要不同的字符对应关系,比如:
在汉语中, 21234 —> 编
日语中,21234 —> xx(反正是其他的字符)
那么同样的一段编码,在不同的计算机中,解码出的语言就完全不一样了,这样肯定是不行的。
Unicode
因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
可以简单理解为Unicode字符集是一个非常大的表,包括了全世界的字符,它给出了一个统一的规定,比如,哪个字符用哪个数表示,全球统一,这样就不存在乱码了。
Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF(十六进制),有110多万,每个字符都有一个唯一的Unicode编号,这个编号一般写成16进制,在前面加上U+。例如:“马”的Unicode是U+9A6C。
实际上每个字符都有一个10进制的整数来对应,这样方便我们人类来看,然后在Unicode字符集中,我们又给了它们另一个编号,这个编号是从0x000000 到 0x10FFFF(十六进制),所以每个字符对应一个10进制整数,同时也对应一个Unicode编号:U+xxxxxx形式
下面这里U+4E24,可以看出形式U+xxxxxx不是这种,我的理解是,这些字符是常用字符,位于第0个平面。前面两位直接省略了:
Unicode编码详解(一):Unicode简介及其分类
这个博文写得很详细
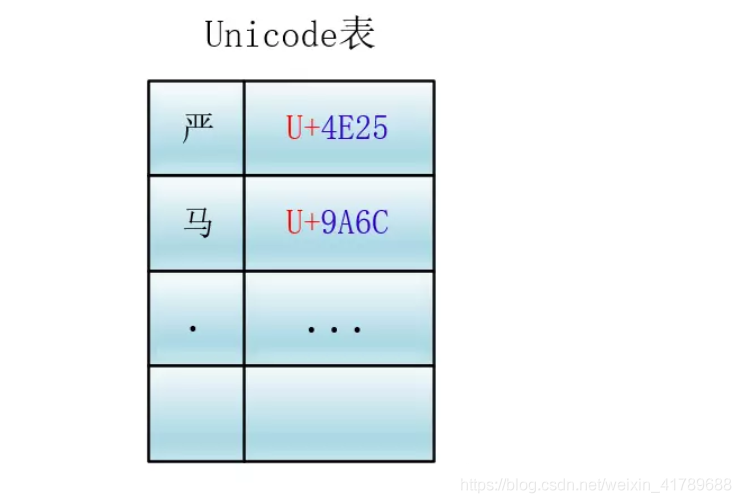
Unicode本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
既然是十六进制,编号范围从 0x000000 到 0x10FFFF(十六进制),那么直接用这些编号对应的二进制存储也是可以的。
但是问题就是,这里有6个十六进制位,也就是24个比特位(3个字节),编码方式是比较简单,但是浪费空间啊,比如有个字符:

实际上a对应的十六进制0x000061对应的二进制完全不需要那么多位来表示
110 0001 就可以表示了,前面那么多字节就浪费了。
然后就有了变长编码:
针对不同范围的码点,不同范围意思是每个字符对应的整数编号,或者说Unicode编号(U+xxxxxx),不同区间内使用不同长度的字节。
使用不同长度的字节序列来表示 utf-8就是一种变长编码。
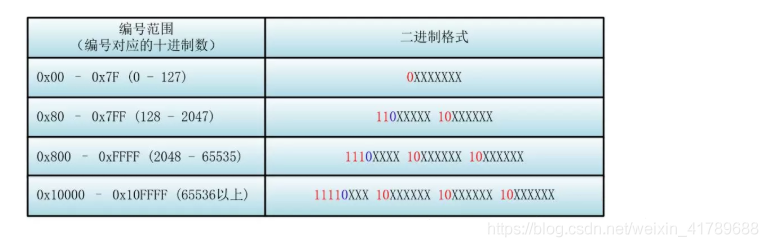
UTF-8使用1~4字节为每个字符编码:
- 一个US-ASCIl字符只需1字节编码(Unicode范围由U+0000~U+007F)。
- 带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等字母则需要2字节编码(Unicode范围由U+0080~U+07FF)。
- 其他语言的字符(包括中日韩文字、东南亚文字、中东文字等)包含了大部分常用字,使用3字节编码。
- 其他极少使用的语言字符使用4字节编码。
还有很多细节没有看,先简单了解一下。
Unicode字符集可以简写为UCS(Unicode Character Set)。就是一个字符集,一个大表格,有一个对应关系。
UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。就是怎么把这些字符对应的十六进制编码,按照哪种格式编码。
python中的字符串
再结合廖雪峰的例子,仔细理解一下:
首先,
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
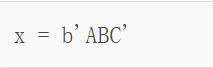
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示:
由于在utf-8编码格式中,中文字符用3个字节编码,所以'今天天气真好'一共使用了18个字节。

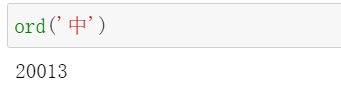
如果我们想知道某一个字符在Unicode字符集中,对应的那个10进制整数是多少,我们可以使用ord()函数。
比如看一个中文字符 中:

python中输出对应的Unicode整数编号
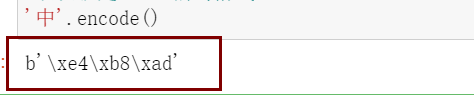
使用str.encode()方法把它按照utf-8编码格式编码:

可以看到和我们在Unicode官网查到的一样。
同时还可以发现:
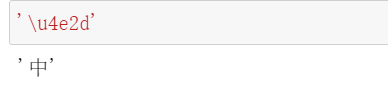
‘\u4e2d’也对对应着'中',原来‘\u4e2d’是他的utf-16的编码形式。
其实十六进制4e2d对应的二进制是0100 1110 0010 1101 对应的整数是
20013,也就是他的整数编号
实际上在对’中‘进行utf-8编码是,就是先拿到他的整数编号20013,对应的二进制是
100 1110 0010 1101 ,根据编码规则,20013,在下面这个范围内,所以使用3个字节编码,编码有部分固定格式。
首先拿出20013对应的二进制100 1110 0010 1101,从最后以为开始,从右往左,把数字填到1110xxxx 10xxxxxx 10xxxxxx 中的x


没填满的补0
就变成了11100100 10111000 10101101 对应的十六进制为

也就是:
同时使用str.decode()将字节流解码成字符串
















 1510
1510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









