







常用的损失函数如torch.nn.MSELoss()、torch.nn.L1Loss()计算的是两幅图像间像素位置一一对应的像素级的损失函数。对于一种极端情况:两幅完全一样的图像但对应的像素位置错开一个像素的距离,像素级损失函数计算出来的效果往往比较大,但人眼观察两幅图像几乎没有差距。
感知损失函数是一种能理解图像语义信息的损失函数,它利用一个Vgg网络提取出图像的特征信息,并利用这些特征信息做loss,能够有效解决上述像素级损失函数的问题。以下是感知损失的pytorch实现代码:
定义感知损失
# Loss functions
class PerceptualLoss():
def contentFunc(self):
conv_3_3_layer = 14
cnn = models.vgg19(pretrained=True).features
cnn = cnn.cuda()
model = nn.Sequential()
model = model.cuda()
for i,layer in enumerate(list(cnn)):
model.add_module(str(i),layer)
if i == conv_3_3_layer:
break
return model
def __init__(self, loss):
self.criterion = loss
self.contentFunc = self.contentFunc()
def get_loss(self, fakeIm, realIm):
f_fake = self.contentFunc.forward(fakeIm)
f_real = self.contentFunc.forward(realIm)
f_real_no_grad = f_real.detach()
loss = self.criterion(f_fake, f_real_no_grad)
return loss
感知损失需要嵌套mse loss
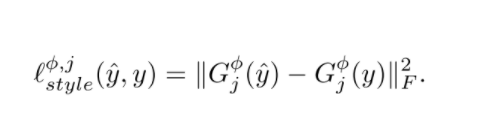
content_loss = PerceptualLoss(torch.nn.MSELoss())
loss_PerceptualLoss = content_loss.get_loss( fake_B, real_B)
loss_G = loss_GAN + lambda_A * loss_pixel + lambda_B * loss_lambda #














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









