







Day2:

OpenAI 的 12 天计划进入了第 2 天。凌晨两点,我们迎来了一个开发者和研究者更感兴趣的产品:Reinforcement Fine-Tuning,即强化微调。
参与发布的四人组是 OpenAI 研究副总裁 Mark Chen、OpenAI 技术员 John Allard 和 Julie Wang、Berkeley Lab 的环境基因组学和系统生物学研究者 Justin Reese。
正如小型发布会上所说,RFT也许正式代表o1时代下将更多的人或模型更平滑而自然的带入到rl×llm所创造的复杂推理空间中来,为什么这么说呢?
首先我们先来看看这句话:“强化微调不仅会教模型模仿其输入,更是会让其学会在特定领域以新的方式进行推理。” 那么,都是FT,怎么做到“授人以鱼”和“授人以渔”的区别呢?
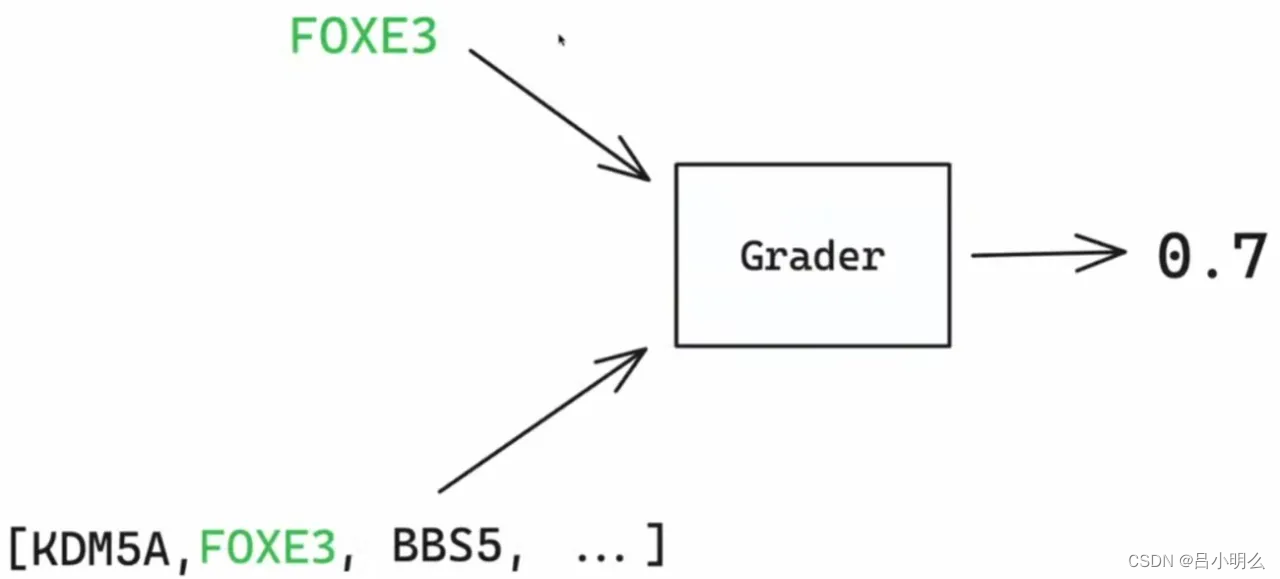
我想关键的重点在于“任务监督信号”,即那个“Grader”上,让我想想,从哪里说起呢?(我这个像不像o1或其他test-time Model的套路,哈哈,装下~)
好吧,还是要回到今年年初自己写的长篇技术文章「融合RL与LLM思想,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









