







本文创建自己的OCR,实现无限次图片识别,没一个字废话
第 1 步、下载安装 Tesseract,官方链接:点我
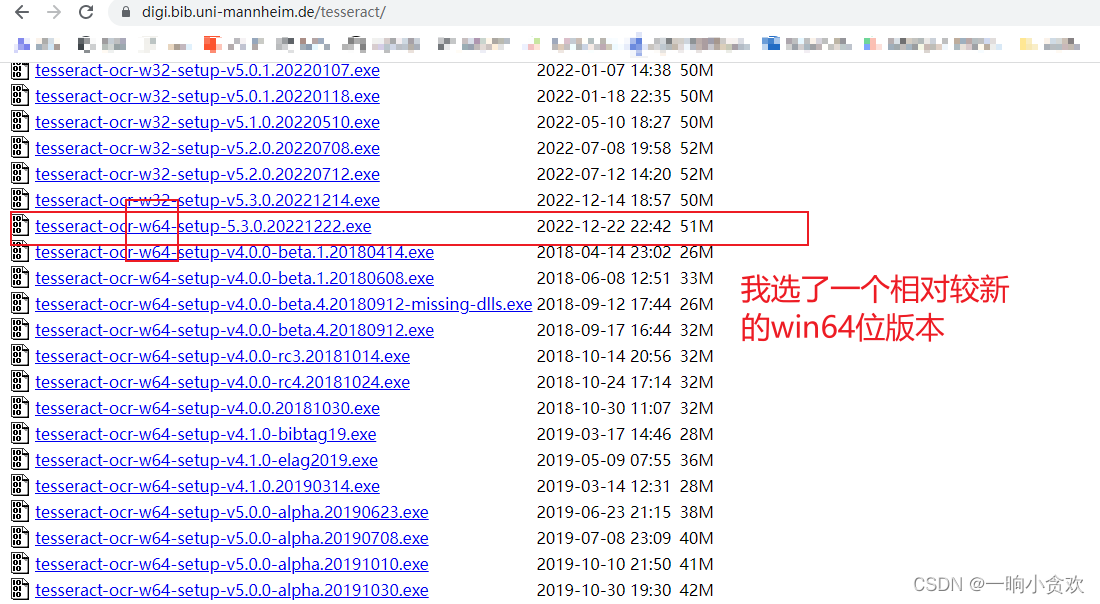


第 2 步准备添加环境变量

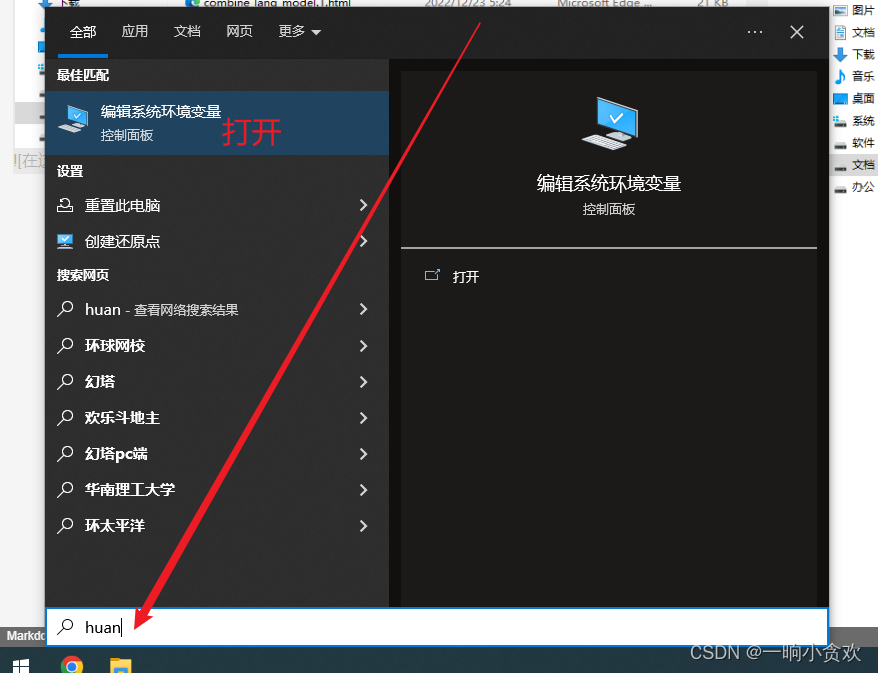
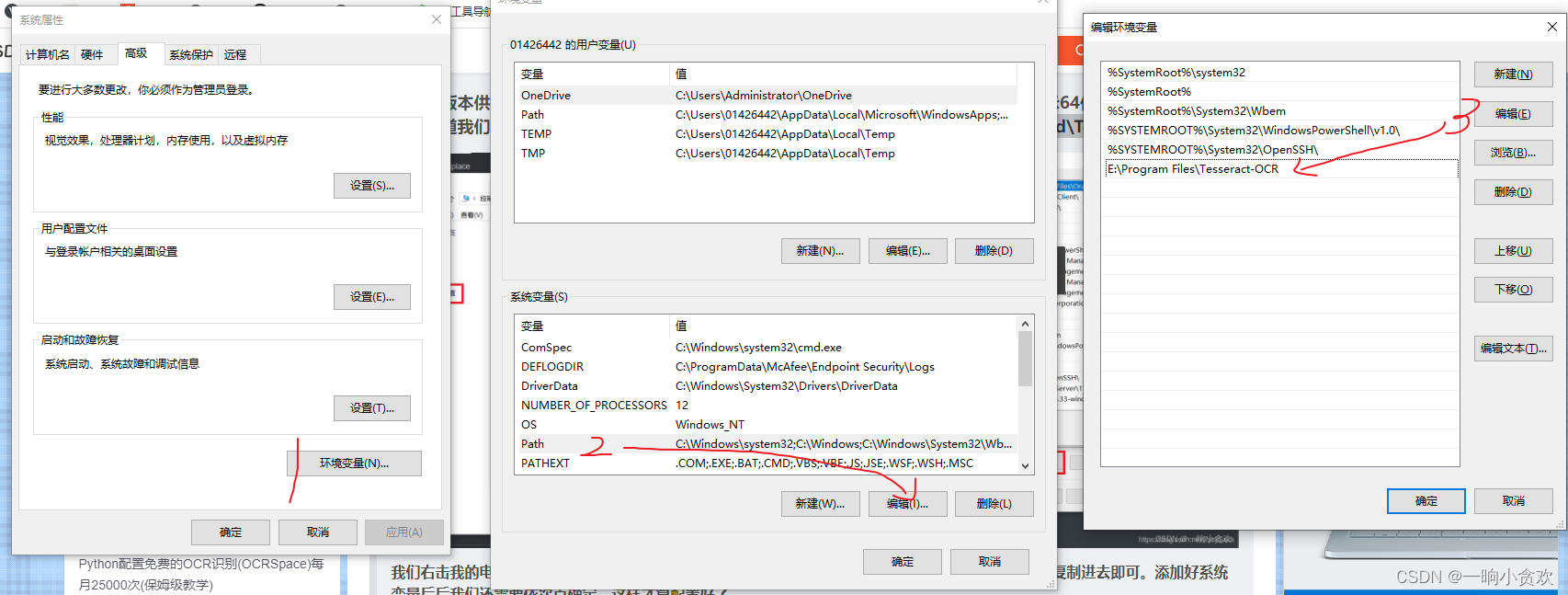
添加好后,点击确定
第 3 步,下载语言包,默认不持支中文,中文包下载:点我
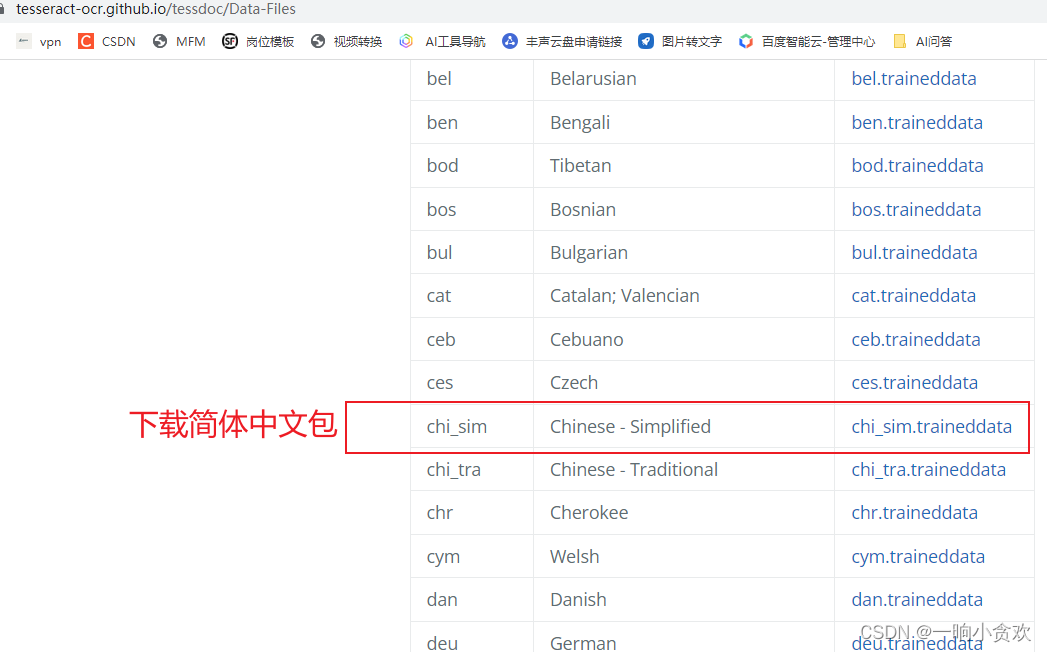
下载成功

下载慢的,或者下载不了的,能不能关注+收藏+点赞,然后我就会给你
重要的一步:
下载完成后我们需要将文件内chi_sim.traineddata放到Tesseract的路径下的tessdata目录下
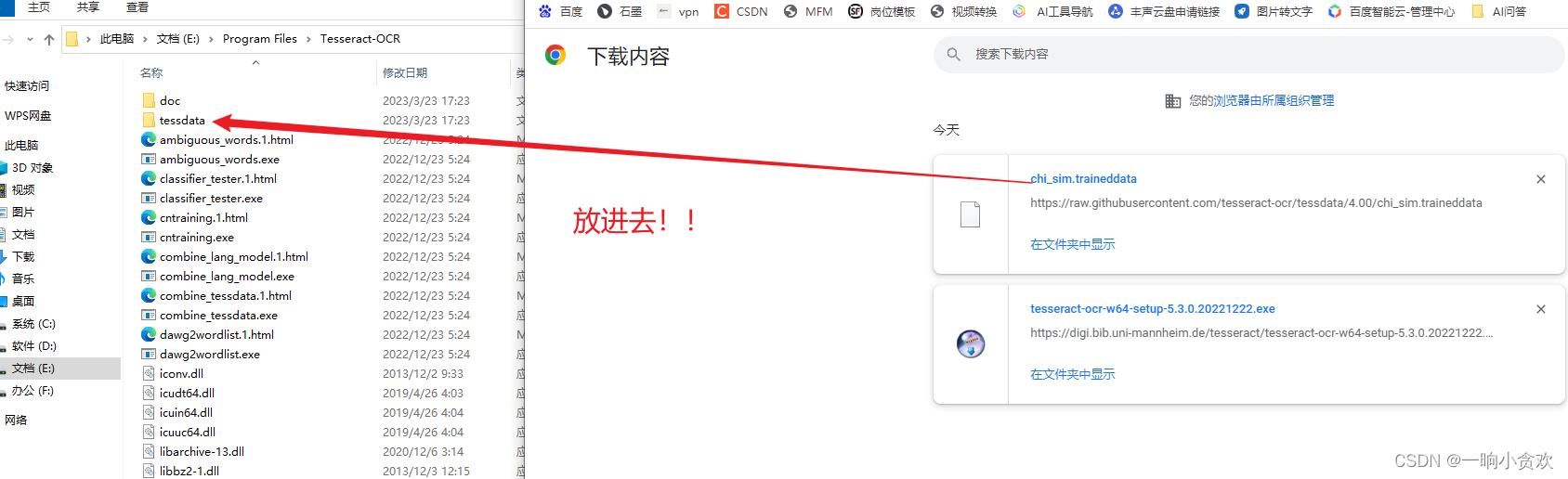
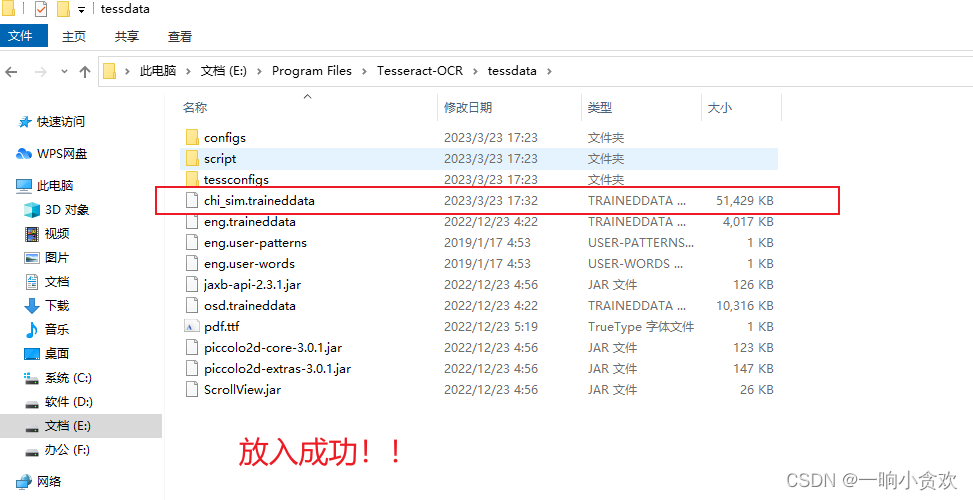
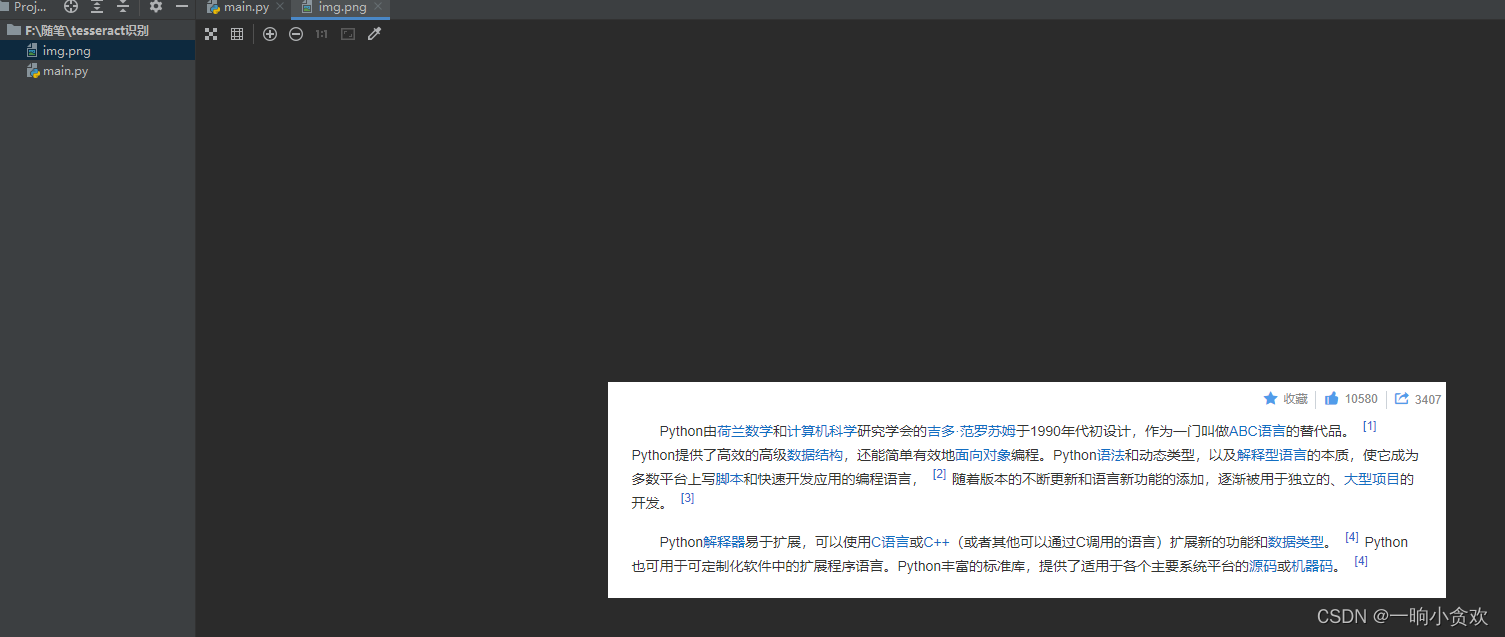
实践出真知
| 库 | 安装 |
|---|---|
| pytesseract | pip install pytesseract |
import pytesseract
from PIL import Image
img = Image.open("img.png")
string = pytesseract.image_to_string(img, lang='chi_sim')
print(string)
print("----------------------------------------------------------------")
# print(path+img)
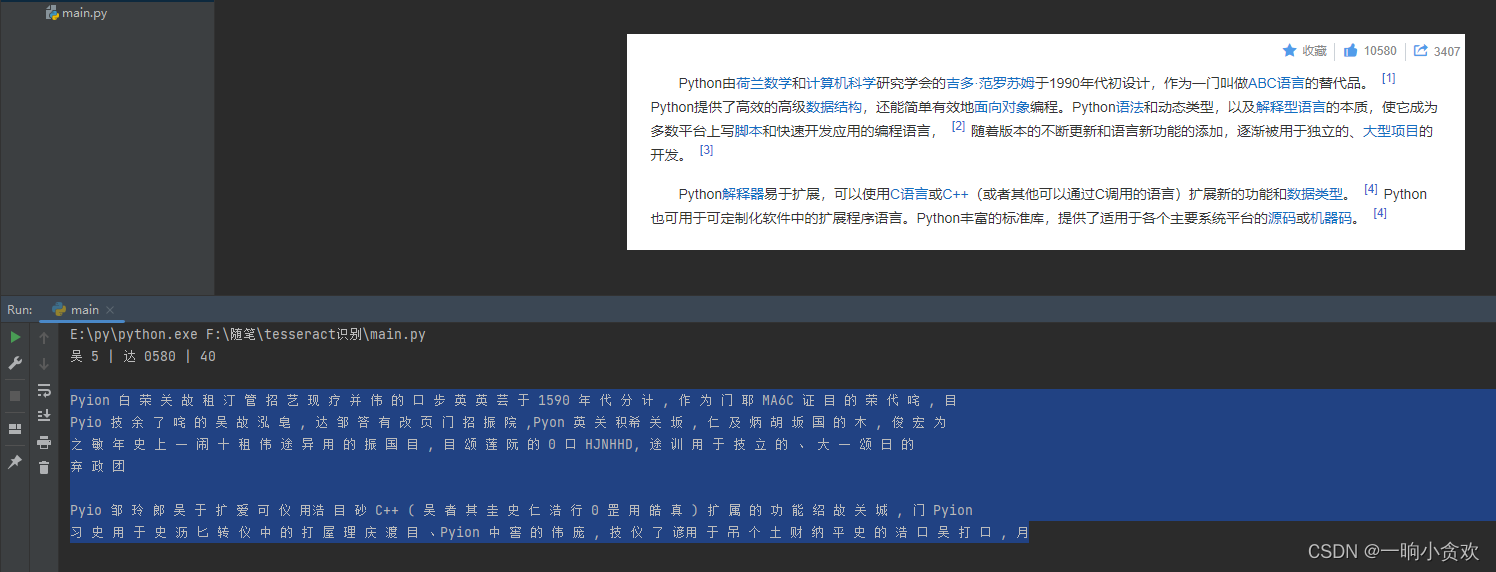
识别效果:“一坨屎”,垃圾















 2592
2592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











