




目录
专栏导读
🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手
🏳️🌈 个人博客主页:请点击——> 个人的博客主页 求收藏
🏳️🌈 Github主页:请点击——> Github主页 求Star⭐
🏳️🌈 知乎主页:请点击——> 知乎主页 求关注
🏳️🌈 CSDN博客主页:请点击——> CSDN的博客主页 求关注
👍 该系列文章专栏:请点击——>Python办公自动化专栏 求订阅
🕷 此外还有爬虫专栏:请点击——>Python爬虫基础专栏 求订阅
📕 此外还有python基础专栏:请点击——>Python基础学习专栏 求订阅
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
❤️ 欢迎各位佬关注! ❤️
前言
这篇博客将带你深入理解并上手一个基于 Flask + 智谱AI(GLM-4.5)的流式对话应用。我们将从项目结构、后端接口、前端渲染、流式通信、部署与安全等角度逐段拆解,最后给出可落地的扩展建议与常见问题排查清单。
项目简介
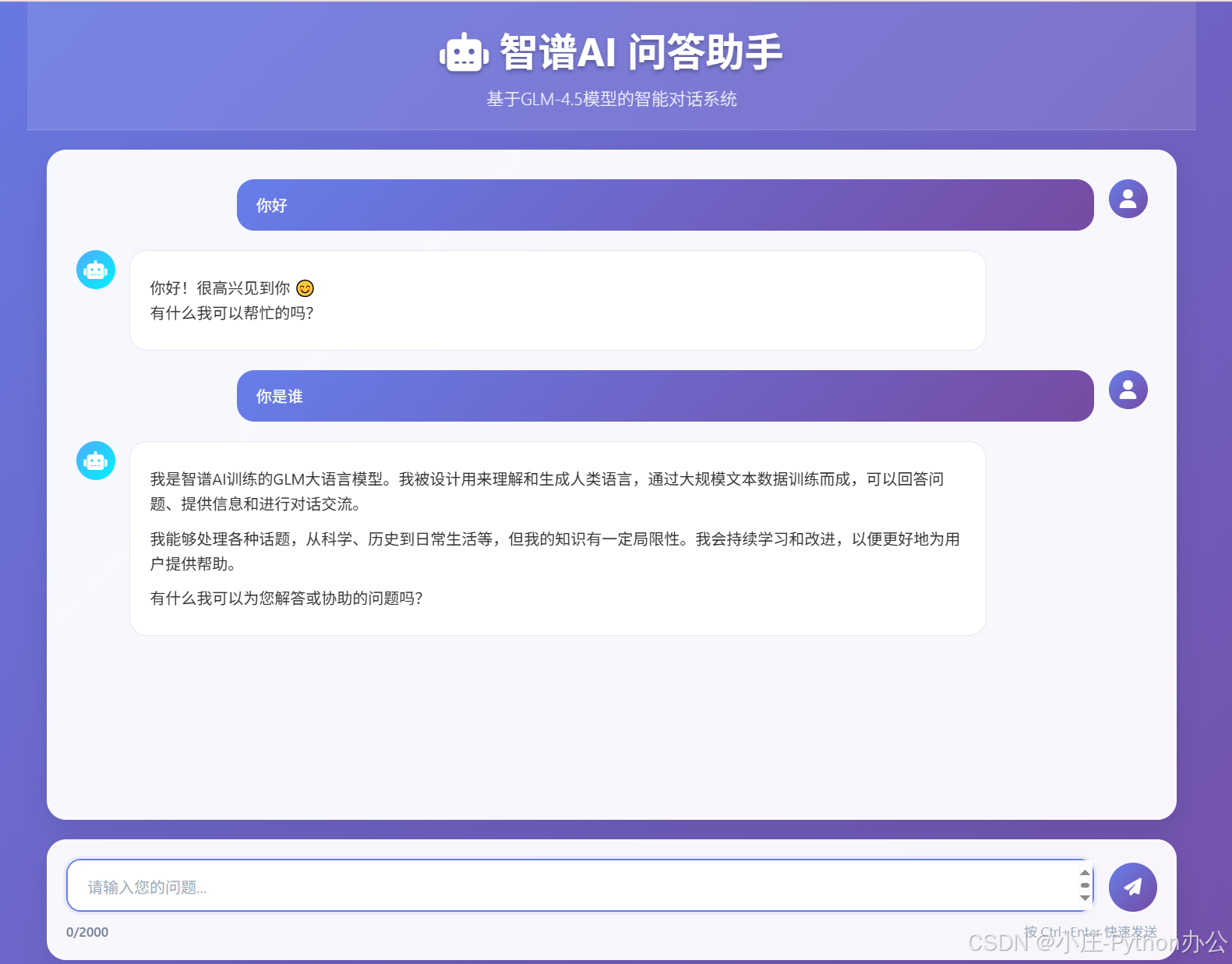
本项目实现了一个简洁但功能完备的「问答助手」:
- 支持 Markdown 渲染与代码高亮,适合技术解答与示例输出。
- 支持流式回复(SSE-like),边生成边显示,显著提升交互体验。
- 贴心的输入体验:自动增高、字符计数、快捷键发送(Ctrl+Enter)。
- 细致的用户反馈:加载动效、Toast 通知、错误提示。
在线上生产可进一步增强对话记忆、上下文管理与角色设定,后文提供演进路线参考。
技术栈概览
- 后端:
Flask、flask-cors、zhipuaiSDK、SSE(服务端推送) - 前端:原生
HTML/CSS/JS,marked(Markdown 渲染)、highlight.js(代码高亮)、Font Awesome(图标)
目录结构与职责
zhipu-AI-web-main/
├── app.py # Flask 应用入口与路由
├── requirements.txt # Python 依赖列表
├── README.md # 简要说明(可扩展)
├── static/
│ ├── css/
│ │ └── style.css # 页面样式,含布局/主题/动画
│ └── js/
│ └── script.js # 前端逻辑:消息处理、流式展示、交互体验
└── templates/
└── index.html # 主页面模板,引入第三方库与静态资源
核心文件说明:
app.py:提供首页与两类聊天接口(非流式/api/chat、流式/api/chat/stream)。index.html:页面骨架,加载样式与 JS,并初始化容器结构。script.js:与后端交互,处理流式数据、Markdown/代码渲染、输入与状态管理。
快速开始
- 安装依赖:
pip install -r requirements.txt
- 配置智谱 API Key:
-
注册地址:点我注册
-
在
app.py中的ZhipuAI(api_key="填自己的")处替换为你的真实 Key; -
更推荐使用环境变量或
.env文件,避免源码暴露:
import os
from zhipuai import ZhipuAI
client = ZhipuAI(api_key=os.getenv("ZHIPUAI_API_KEY"))
- 启动开发服务:
python app.py
- 浏览器访问:
- 打开
http://localhost:5000,即可体验问答助手。
后端详解(Flask + 智谱AI)
首页路由
@app.route('/')
def index():
return render_template('index.html')
非流式聊天接口:POST /api/chat
用于一次性返回完整答案,便于某些场景快速拿到结果。
@app.route('/api/chat', methods=['POST'])
def chat():
data = request.get_json()
user_message = data.get('message', '')
response = client.chat.completions.create(
model="glm-4.5",
messages=[{"role": "user", "content": user_message}],
stream=False,
max_tokens=4096,
temperature=0.7
)
reply = response.choices[0].message.content
return jsonify({'success': True, 'reply': reply, 'timestamp': time.time()})
参数要点:
model:当前使用glm-4.5。messages:对话消息数组,最简单的单轮只传用户消息;后文会介绍多轮与系统提示。temperature:越高越发散,越低越稳健;建议在 0.2–0.8 间调优。max_tokens:上限需结合业务与成本控制。
流式聊天接口:POST /api/chat/stream
用于「边生成边显示」,显著提升用户体验。核心思路:
- 后端通过生成器
yield逐段输出text/event-stream。 - 前端读取响应流,按行解析
data: { ... }的 JSON,拼接展示。
@app.route('/api/chat/stream', methods=['POST'])
def chat_stream():
data = request.get_json()
user_message = data.get('message', '')
def generate():
response = client.chat.completions.create(
model="glm-4.5",
messages=[{"role": "user", "content": user_message}],
stream=True,
max_tokens=4096,
temperature=0.7
)
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
yield f"data: {json.dumps({'content': content, 'done': False})}\n\n"
yield f"data: {json.dumps({'content': '', 'done': True})}\n\n"
return Response(generate(), mimetype='text/event-stream', headers={
'Cache-Control': 'no-cache', 'Connection': 'keep-alive',
'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Headers': 'Content-Type'
})
注意:text/event-stream 与 yield 双结合,才能保证浏览器不断收到数据片段。上游 SDK 返回的 chunk 结构中,实际内容通常在 choices[0].delta.content。
前端详解(渲染与交互)
页面骨架与资源引入
index.html 引入了 marked 与 highlight.js,用于把 AI 文本中的 Markdown 转成 HTML 并做代码高亮:
<script src="https://cdn.jsdelivr.net/npm/marked@9.1.6/marked.min.js"></script>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.9.0/styles/github-dark.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/11.9.0/highlight.min.js"></script>
发送消息与流式读取
在 script.js 中,点击发送或 Ctrl+Enter 会触发 handleSendMessage(),随后通过 fetch 发起 POST 请求并以「ReadableStream」读取响应体:
const response = await fetch('/api/chat/stream', {
method: 'POST', headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '', fullContent = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split('\n');
buffer = lines.pop();
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
if (data.content) {
fullContent += data.content;
contentElement.innerHTML = marked.parse(fullContent);
processCodeBlocks(contentElement);
}
}
}
}
提示:文件注释写了“使用 EventSource 进行流式通信”,但当前实现是 fetch + ReadableStream。如果希望更换为 EventSource,后端也需调整输出格式与跨域策略;二者在易用性与控制粒度上各有取舍。
Markdown 渲染与代码高亮
初始化 marked 时启用 breaks/gfm,并把高亮委托给 highlight.js:
marked.setOptions({
highlight: (code, lang) => {
if (lang && hljs.getLanguage(lang)) {
return hljs.highlight(code, { language: lang }).value;
}
return hljs.highlightAuto(code).value;
},
breaks: true,
gfm: true,
});
同时,processCodeBlocks 会为每个代码块添加复制按钮与交互态,优化开发者阅读体验。
交互细节与状态管理
- 输入框自动增高:防止长文本挤压。
- 字符计数:
0/2000,接近上限时颜色渐变提醒。 - 加载遮罩:AI计算时屏蔽重复请求,首个内容到达即关闭。
- Toast 通知:错误或成功信息轻量提示。
- 滚动管理:新内容到达自动滚动到底部。
- 错误兜底:失败时显示“抱歉,我遇到了一些问题,请稍后再试。”
- 网络感知:
online/offline事件监听,离线提示与恢复。
安全与防护建议
- 不要在源码中硬编码 API Key,改用环境变量或密钥管理服务。
- Markdown 渲染存在潜在 XSS 风险,建议引入
DOMPurify做 HTML 过滤:
<script src="https://cdn.jsdelivr.net/npm/dompurify@3.0.6/dist/purify.min.js"></script>
const unsafeHtml = marked.parse(fullContent);
const safeHtml = DOMPurify.sanitize(unsafeHtml, { USE_PROFILES: { html: true } });
contentElement.innerHTML = safeHtml;
- 上线时收紧 CORS,避免
'*'任意来源;仅允许你的前端域名。 - 增加速率限制(Rate Limit)与鉴权,防止被恶意滥用。
部署建议(生产环境)
- Windows 可选
waitress部署;Linux 习惯用gunicorn + gevent:
pip install waitress
python -m waitress --listen=0.0.0.0:5000 app:app
- 反向代理(Nginx)需开启对
text/event-stream的支持,关闭缓冲:
location /api/chat/stream {
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_buffering off; # 关键:关闭缓冲
chunked_transfer_encoding on;
proxy_read_timeout 3600;
proxy_pass http://127.0.0.1:5000;
}
- 关闭
debug=True,并启用更严格的错误日志与监控。
进阶演进路线
- 多轮对话与上下文:后端维护
messages历史,按需截断与压缩。 - 系统提示与角色设定:在
messages增加system角色,提高输出一致性。 - 模型参数调优:
temperature/top_p/max_tokens结合场景深度测试。 - 会话持久化:落库(如 Redis/PostgreSQL),支持刷新与多端同步。
- 富文本输出:图片、表格、图表(需结合安全白名单与防护)。
- 前端组件化:拆分消息气泡、输入区、状态层,便于复用。
示例:带系统提示与历史的请求结构(伪码)
messages = [
{"role": "system", "content": "你是严谨、友好的中文技术助手。"},
*history_messages, # 最近若干轮,按 token 预算裁剪
{"role": "user", "content": user_message},
]
response = client.chat.completions.create(
model="glm-4.5",
messages=messages,
stream=True,
temperature=0.5,
max_tokens=1024,
)
常见问题排查(FAQ)
- 500 错误:检查 API Key 是否有效、模型名是否正确、网络是否可达。
- CORS 报错:生产环境请限定允许来源,不要使用通配
*。 - 流式中断:确认反向代理未开启缓冲;浏览器控制台查看网络与 JS 错误。
- 高亮失败:确保引入了对应语言包或走自动高亮;注意代码块语法标注。
- 文本被截断:适度提高
max_tokens或在前端明确提示“内容较长已截断”。
结语
本文从零搭建并深入解析了一个「智谱AI 问答助手」的完整实现,兼顾交互体验、工程架构与上线部署的核心要点。你可以直接在此基础上快速迭代出更贴合业务的产品:加上下文、做差异化 Prompt、完善安全与监控、逐步走向生产级稳定性。欢迎在此项目上继续打造你的 AI 应用!
结尾
希望对初学者有帮助;致力于办公自动化的小小程序员一枚
希望能得到大家的【❤️一个免费关注❤️】感谢!
求个 🤞 关注 🤞 +❤️ 喜欢 ❤️ +👍 收藏 👍
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏



















 3340
3340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











