






Authors:
Introduction:

该文章研究的是人类物体交互检测的方法,之前的基于transformer的方法只是将整个图像输入进去得到人体、物体和交互动作的识别的结果,或者是只将人体物体的检测用一个transformer检测,而交互动作用另一个transformer检测。这样的不足在于缺少了人体、物体和活动间关系信息的挖掘。本文采用三个transformer提取三方面信息,并加入了三者关系学习模块。将该问题变成多任务学习的的形式来解决。

Motivation:
为什么要用transformer来做?因为目前transformer网络已经被证明能够在目标检测领域表现较好。但已有的方法仅限于将人与物体的上下文传播到交互上下文,还是存在缺失三者交互信息的学习,需要改进。
Contribution:
-
提出了多路复用关系嵌入模块(multiplex relation embedding module)用于HOI检测。该模块利用HOI实例中的一元、二元和三元关系生成上下文信息。
-
提出了关注力融合模块(attentive fusion module),有效地传播上下文信息以进行上下文交换。这个模块有助于在HOI检测中将必要的上下文信息传递给相应的任务。
-
设计了一个三分支架构(three-branch architecture),用于学习更具区分性的特征,以应对子任务,即人体检测、物体检测和交互分类。
-
提出的方法名为MUREN(Multiplex Relation Embedding Network),在HICO-DET和V-COCO数据集的基准测试中优于现有的方法,取得了更好的性能表现
Problem Definition:

问题的输入是图片,输出是要得到人体和物体的检测框位置,以及物体的类别和动作类别。
Method :

1. 图片encoding :采用CNN提取图片特征、加入位置特征,输入到encoder中得到图片的特征向量。
2. 三层transformer decoder:每层都加入一个自学习的任务token Q,根据Q进行多次的decoder,得到F
3. 关系信息提取MURE:三类F输入到MURE中进行关系信息学习
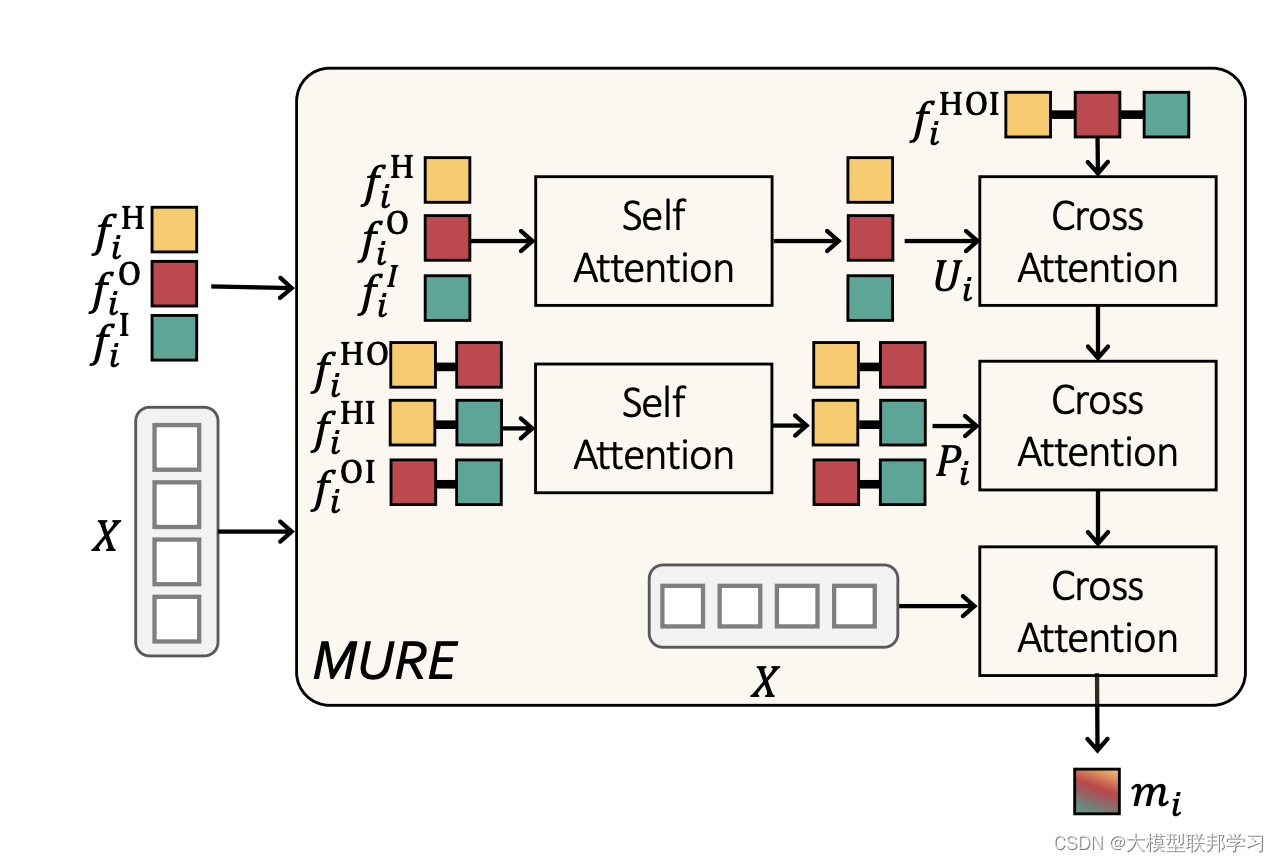



三类信息进行多次attention结果得到最终M 。
4. 基于关系信息得到最终预测结果

M作为每类任务的补充信息

结果通过全连接得到
5. 训练任务

多任务学习
Experiments
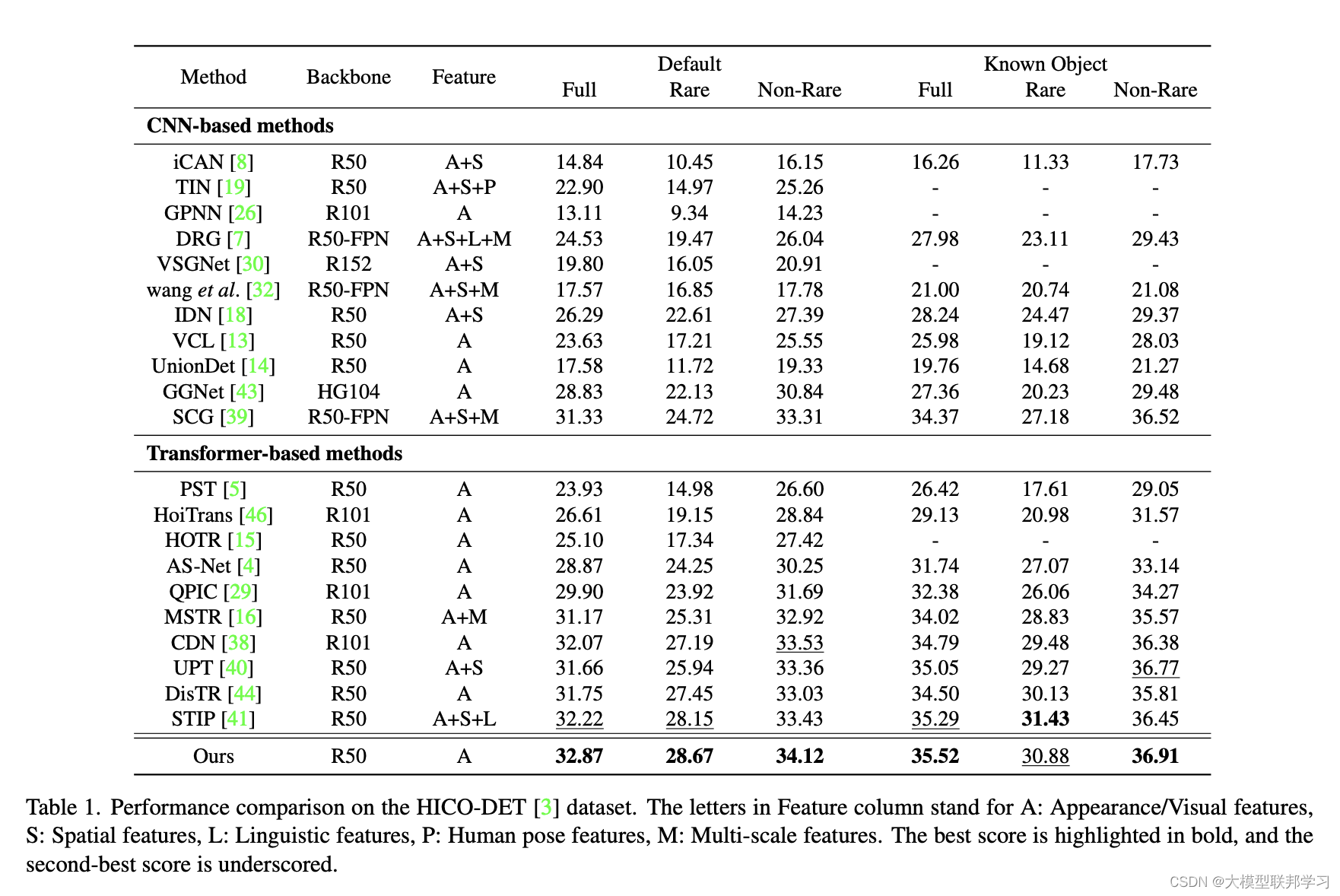
数据集:HICO-DET :80种物体,117种交互,600种HOI。每种HOI至少10个样本
V-COCO:80种物体,29种交互。
指标: AP 物体检测准确读指标,通过计算每种HOI的AP来反应HOI的效果
实验结果:超过所有baseline

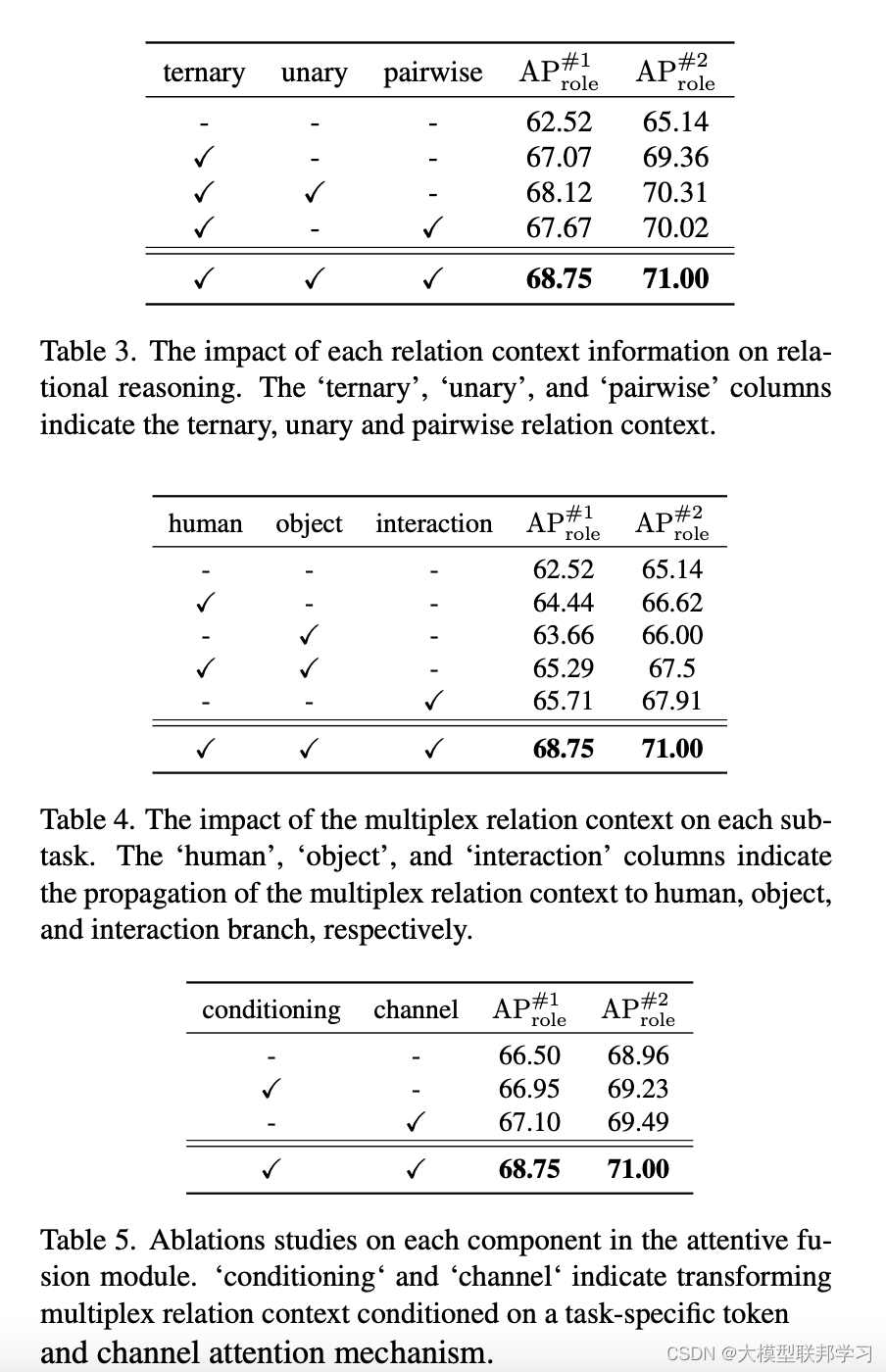
消融实验:














 3491
3491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









