







Flow Model
无监督,生成模型
动机
- 拟合连续分布
- 给出 x x x可以计算 p ( x ) p(x) p(x)
- 从拟合到的分布中采样得到接近于真实的 x x x
- 学习到latent representation
方法概要
离散分布由于取值往往是有限个,所以总能在得到每个取值的logits之后做softmax保证得到的概率恒正且和为1(满足分布的条件),但是连续分布无限个取值不能做softmax,所以将其映射到z上并使z满足一个设计好的先验分布(感觉有点像连续版本的softmax),同样用极大似然的方法估计参数。

在做极大似然的时候,需要注意我们最后目标是
p
(
x
)
p(x)
p(x),但是我们模型得到的是
p
(
z
)
p(z)
p(z),所以存在一个
p
(
x
)
p(x)
p(x)和
p
(
z
)
p(z)
p(z)之间的转换
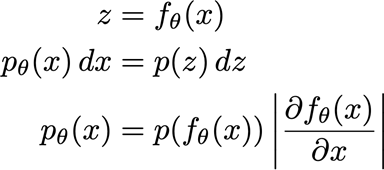

换元的f要求可微且可逆
可逆给出一个intuition的解释
∫
−
∞
+
∞
p
(
z
)
d
z
=
∫
−
∞
+
∞
p
(
x
)
d
x
∫
−
∞
+
∞
p
(
f
(
x
)
)
d
f
(
x
)
=
∫
−
∞
+
∞
p
(
x
)
d
x
∫
−
∞
+
∞
p
(
f
(
x
)
f
′
(
x
)
d
x
=
∫
−
∞
+
∞
p
(
x
)
d
x
p
(
f
(
x
)
)
f
′
(
x
)
=
p
(
x
)
\int_{-\infty}^{+\infty}p(z)dz = \int_{-\infty}^{+\infty}p(x)dx\\ \int_{-\infty}^{+\infty}p(f(x))df(x) = \int_{-\infty}^{+\infty}p(x)dx\\ \int_{-\infty}^{+\infty}p(f(x)f'(x)dx = \int_{-\infty}^{+\infty}p(x)dx\\ p(f(x))f'(x)=p(x)
∫−∞+∞p(z)dz=∫−∞+∞p(x)dx∫−∞+∞p(f(x))df(x)=∫−∞+∞p(x)dx∫−∞+∞p(f(x)f′(x)dx=∫−∞+∞p(x)dxp(f(x))f′(x)=p(x)由于概率恒正,所以需要
f
′
(
x
)
>
0
f'(x)>0
f′(x)>0恒成立,也就需要
f
f
f可逆
由于使用概率分布的CDF巨有可逆可微的性质,而且导数恰为PDF方便计算,所以通常用CDF作为
f
f
f
1-D

从一个连续分布中采样,红色表示随机变量
x
x
x的取值,粉色表示该值取到的次数(注意这里的柱状图表示在一定范围内的采样数之和,不然没法画图,取到多次像0.124231这样的离散值的概率很小),黄色表示经过
f
f
f映射后
z
z
z的取值,粉黄图表示的就是将训练集的
x
x
x映射到
z
z
z后的分布情况。映射函数
f
f
f通常为混合高斯或混合logistics的CDF。

2-D



类似Autoregressive Model的做法,不过离散版AR中MLP的
f
(
x
<
i
)
f(x_{< i})
f(x<i)得到的是概率,而这里得到的是用于计算CDF的对应分布的参数,所以2-D版本的ARFlow需要有的参数有
- 用于x1-CDF的5个logits,locs,scales
- 一个用于生成
f
(
;
x
1
)
f(;x_1)
f(;x1)的MLP(in:1(
x
1
x_1
x1),out:3(logits,locs,scales)*5(5个Gaussian))

之后 x 1 , x 2 x_1,x_2 x1,x2根据自己分布的参数分别得到 z 1 , z 2 z_1,z_2 z1,z2,并且同时通过log_prob()得到 f ′ f' f′

然后就可以通过极大似然估计优化参数
N-D
当输入输出的维度变高时,需要设计好 f f f满足:
- 可逆
- 便于计算Jacobian行列式
1.ARFlow


跟2-D的ARFlow类似,使用PixelCNN的Mask方法得到
f
(
;
x
<
i
)
f(;x_{<i})
f(;x<i),得到的是CDF分布的参数,所以高维ARFlow模型的参数只有一个Masked PixelCNN(in:H x W,out:H x W x n_comp*3(logits,locs,scales))

得到H x W个分布的参数后计算CDF得到z,并通过PDF得到Jacobian的行列式

2.RealNVP
当
x
x
x和
z
z
z都是高维时,计算
p
(
x
)
p(x)
p(x)的方法推广为
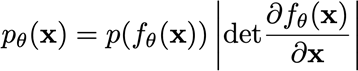
具体原因,因为1-D是用面积元推导出来的,
p
(
x
)
d
x
=
p
(
z
)
d
z
p(x)dx=p(z)dz
p(x)dx=p(z)dz,而N-D则对应的体积元,行列式的几何意义就是空间的拉伸程度。
当维度很高时,出现两个问题:
- 如何保证 f f f可逆
- 如何高效计算行列式
使用affine flow
z
=
A
−
1
(
x
−
b
)
,
x
=
A
z
+
b
z=A^{-1}(x-b),x=Az+b
z=A−1(x−b),x=Az+b
每个flow固定一半x,并且通过固定的一半x生成A和b,并对另一半x做affine
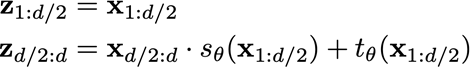
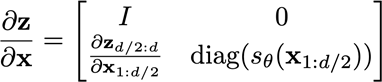
生成A的时候使用元素级的方法,保证A为对角阵,这样将两半z合并后对原来的x求Jacobian得到的是一个三角阵,左上块因为固定的x,所以求导为单位矩阵,因此可以很容易的计算得到整个的Jacobian行列式为
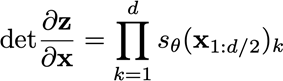
如何选择哪一半固定,哪一半做Affine对结果影响很大,文章给出了棋盘式和channel式两种。棋盘式就是像国际象棋的棋盘中黑白的颜色区分;channel式就是沿着channel分。

棋盘式类似pixelCNN中的Mask方式,做一个0-1mask;channel直接沿着channel分割两份,因为affine是element-wise,MLP输出2*C x H x W,2代表
g
θ
g_\theta
gθ得到的scale和shift
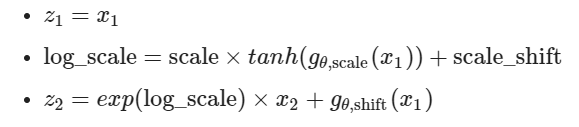
整体结构如下,做固定x的和做affinex的是交换的,不然到最后有一边的x是一点没变的。
class WeightNormConv2d(nn.Module):
def __init__(self, in_dim, out_dim, kernel_size, stride=1, padding=0,
bias=True):
super(WeightNormConv2d, self).__init__()
self.conv = nn.utils.weight_norm(
nn.Conv2d(in_dim, out_dim, kernel_size,
stride=stride, padding=padding, bias=bias))
def forward(self, x):
return self.conv(x)
# 取消了affine和running_mean/std的BN
class ActNorm(nn.Module):
def __init__(self, n_channels):
super(ActNorm, self).__init__()
self.log_scale = nn.Parameter(torch.zeros(1, n_channels, 1, 1), requires_grad=True)
self.shift = nn.Parameter(torch.zeros(1, n_channels, 1, 1), requires_grad=True)
self.n_channels = n_channels
self.initialized = False
def forward(self, x, reverse=False):
if reverse:
return (x - self.shift) * torch.exp(-self.log_scale), self.log_scale
else:
if not self.initialized:
self.shift.data = -torch.mean(x, dim=[0, 2, 3], keepdim=True)
self.log_scale.data = - torch.log(
torch.std(x.permute(1, 0, 2, 3).reshape(self.n_channels, -1), dim=1).reshape(1, self.n_channels, 1,
1))
self.initialized = True
result = x * torch.exp(self.log_scale) + self.shift
return x * torch.exp(self.log_scale) + self.shift, self.log_scale
class ResnetBlock(nn.Module):
def __init__(self, dim):
super(ResnetBlock, self).__init__()
self.block = nn.Sequential(
WeightNormConv2d(dim, dim, (1, 1), stride=1, padding=0),
nn.ReLU(),
WeightNormConv2d(dim, dim, (3, 3), stride=1, padding=1),
nn.ReLU(),
WeightNormConv2d(dim, dim, (1, 1), stride=1, padding=0))
def forward(self, x):
return x + self.block(x)
# 用于从x生成s,t的MLP
class SimpleResnet(nn.Module):
def __init__(self, in_channels=3, out_channels=6, n_filters=128, n_blocks=8):
super(SimpleResnet, self).__init__()
layers = [WeightNormConv2d(in_channels, n_filters, (3, 3), stride=1, padding=1),
nn.ReLU()]
for _ in range(n_blocks):
layers.append(ResnetBlock(n_filters))
layers.append(nn.ReLU())
layers.append(WeightNormConv2d(n_filters, out_channels, (3, 3), stride=1, padding=1))
self.resnet = nn.Sequential(*layers)
def forward(self, x):
return self.resnet(x)
# 棋盘式
class AffineCheckerboardTransform(nn.Module):
def __init__(self, type=1.0):
super(AffineCheckerboardTransform, self).__init__()
self.mask = self.build_mask(type=type)
self.scale = nn.Parameter(torch.zeros(1), requires_grad=True)
self.scale_shift = nn.Parameter(torch.zeros(1), requires_grad=True)
self.resnet = SimpleResnet()
def build_mask(self, type=1.0):
# if type == 1.0, the top left corner will be 1.0
# if type == 0.0, the top left corner will be 0.0
mask = np.arange(32).reshape(-1, 1) + np.arange(32)
# 取模得到0-1mask
mask = np.mod(type + mask, 2)
mask = mask.reshape(-1, 1, 32, 32)
return torch.tensor(mask.astype('float32')).to(device)
def forward(self, x, reverse=False):
# returns transform(x), log_det
batch_size, n_channels, _, _ = x.shape
mask = self.mask.repeat(batch_size, 1, 1, 1)
x_ = x * mask
log_s, t = self.resnet(x_).split(n_channels, dim=1)
log_s = self.scale * torch.tanh(log_s) + self.scale_shift
t = t * (1.0 - mask)
log_s = log_s * (1.0 - mask)
if reverse: # inverting the transformation
x = (x - t) * torch.exp(-log_s)
else:
x = x * torch.exp(log_s) + t
return x, log_s
# channel式
class AffineChannelTransform(nn.Module):
def __init__(self, modify_top):
super(AffineChannelTransform, self).__init__()
self.modify_top = modify_top
self.scale = nn.Parameter(torch.zeros(1), requires_grad=True)
self.scale_shift = nn.Parameter(torch.zeros(1), requires_grad=True)
self.resnet = SimpleResnet(in_channels=6, out_channels=12)
def forward(self, x, reverse=False):
n_channels = x.shape[1]
if self.modify_top:
on, off = x.split(n_channels // 2, dim=1)
else:
off, on = x.split(n_channels // 2, dim=1)
log_s, t = self.resnet(off).split(n_channels // 2, dim=1)
log_s = self.scale * torch.tanh(log_s) + self.scale_shift
if reverse: # inverting the transformation
on = (on - t) * torch.exp(-log_s)
else:
on = on * torch.exp(log_s) + t
if self.modify_top:
return torch.cat([on, off], dim=1), torch.cat([log_s, torch.zeros_like(log_s)], dim=1)
else:
return torch.cat([off, on], dim=1), torch.cat([torch.zeros_like(log_s), log_s], dim=1)
class RealNVP(nn.Module):
def __init__(self):
super(RealNVP, self).__init__()
self.prior = torch.distributions.Normal(torch.tensor(0.).to(device), torch.tensor(1.).to(device))
# 固定的和affine的一直在改变
self.checker_transforms1 = nn.ModuleList([
AffineCheckerboardTransform(1.0),
ActNorm(3),
AffineCheckerboardTransform(0.0),
ActNorm(3),
AffineCheckerboardTransform(1.0),
ActNorm(3),
AffineCheckerboardTransform(0.0)
])
self.channel_transforms = nn.ModuleList([
AffineChannelTransform(True),
ActNorm(12),
AffineChannelTransform(False),
ActNorm(12),
AffineChannelTransform(True),
])
self.checker_transforms2 = nn.ModuleList([
AffineCheckerboardTransform(1.0),
ActNorm(3),
AffineCheckerboardTransform(0.0),
ActNorm(3),
AffineCheckerboardTransform(1.0)
])
# 拓宽channel好进行channel式的flow
def squeeze(self, x):
# C x H x W -> 4C x H/2 x W/2
[B, C, H, W] = list(x.size())
x = x.reshape(B, C, H // 2, 2, W // 2, 2)
x = x.permute(0, 1, 3, 5, 2, 4)
x = x.reshape(B, C * 4, H // 2, W // 2)
return x
def undo_squeeze(self, x):
# 4C x H/2 x W/2 -> C x H x W
[B, C, H, W] = list(x.size())
x = x.reshape(B, C // 4, 2, 2, H, W)
x = x.permute(0, 1, 4, 2, 5, 3)
x = x.reshape(B, C // 4, H * 2, W * 2)
return x
def g(self, z):
# z -> x (inverse of f)
x = z
for op in reversed(self.checker_transforms2):
x, _ = op.forward(x, reverse=True)
x = self.squeeze(x)
for op in reversed(self.channel_transforms):
x, _ = op.forward(x, reverse=True)
x = self.undo_squeeze(x)
for op in reversed(self.checker_transforms1):
x, _ = op.forward(x, reverse=True)
return x
def f(self, x):
# maps x -> z, and returns the log determinant (not reduced)
z, log_det = x, torch.zeros_like(x)
for op in self.checker_transforms1:
z, delta_log_det = op.forward(z)
log_det += delta_log_det
z, log_det = self.squeeze(z), self.squeeze(log_det)
for op in self.channel_transforms:
z, delta_log_det = op.forward(z)
log_det += delta_log_det
z, log_det = self.undo_squeeze(z), self.undo_squeeze(log_det)
for op in self.checker_transforms2:
z, delta_log_det = op.forward(z)
log_det += delta_log_det
return z, log_det
def log_prob(self, x):
z, log_det = self.f(x)
return torch.sum(log_det, [1, 2, 3]) + torch.sum(self.prior.log_prob(z), [1, 2, 3])
def sample(self, num_samples):
z = self.prior.sample([num_samples, 3, 32, 32])
return self.g(z)
Dequantization
谈的比较浅,意思就是像图像这样的离散数据
{
0
,
1
,
2...255
}
\{0,1,2...255\}
{0,1,2...255},如果用连续的方法去拟合会造成性能下降,所以对原始数据添加一个噪音会提高拟合离散数据的性能。

其他一些点
- 利用Pytorch的Distribution库计算GMM模型,B个数据,C个component,可以通过B x C的均值和方差初始化出来B*C个Normal,每个数据的每个component的
π
\pi
π通过B x C个logits做softmax(dim=1)得到,然后Normal*
π
\pi
π并sum(dim=1)得到B个GMM。通过这种component分开计算的方式,可以利用pytorch自带的cdf、log_prob等方法。

- ARFlow计算概率时使用GMM的CDF,如果想要sample时,需要计算GMM的CDF的逆函数。这里使用的方法是,令最后得到的z服从Uniform(0,1)。原来的sample就变成了从均匀分布中采样一个数,然后按CDF求逆得到对应的x。这个过程就跟从GMM中采样得到一个数是一样的,就不用就算GMM的CDF的逆了。而从GMM中采样,可以先根据logits采样,选择以哪个component作为center,然后从选择到的Gaussian采样得到最后的x。















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









