









calibration_curve
运行完得出的分类结果是不是满足独立同分布,分类概率prob,可以用最大似然假设?那么概率校准calibration_curve,用Isotonic regression,得出calibration_curve的好坏,用交叉熵检验,和方差,及使用朴素贝叶斯方法
交叉熵检验,logistics回归
对数损失, 即对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是在概率估计上定义的.它常用于(multi-nominal, 多项)逻辑斯谛回归和神经网络,以及一些期望极大算法的变体. 可用于评估分类器的概率输出.
Isotonic regression–保序回归
概率校准 calibration_curve(更新)
对数损失函数(Logarithmic Loss Function)的原理和 Python 实现
一文搞懂熵(Entropy),交叉熵(Cross-Entropy)

贝叶斯


机器学习—— 朴素贝叶斯分类器
朴素贝叶斯Naive Bayes:
“属性条件独立性假设”(attribute conditional independence assumption)
Dnb = argmax p(Dj) ∏p(hi|Dj) = argmax [ log P(Dj) + ∑ log p(hi|Dj) ]
i Dj i
对于极大后验假设MAP,p(Dj)穷举所有可能,使用全概率公式,p(Dj)为缩放因子,可忽略不计
k
hMAP = argmax p(h|D) = p(h=hi)p(D|h = hi) / ∑ p(h=hi)p(D|h=hi)
h∈H i
hMAP = argmax p(D|h)p(h) / p(D) = argmax p(D|h)p(h)
h∈H h∈H
当MAP满足独立性条件时,为朴素贝叶斯Naive Bayes
p(h1, h2, h3…hi|Dj) = ∏p(hi|Dj)
i
对于极大似然假设,满足“完全不知道假设,或者知道所有的假设发生概率相同”,即满足知道p(h(Xi)),或者p(h(Xi))对于不同Xi服从的分布独立同分布即得到p(h(Xi))服从均匀分布
hML= argmax p(D|h)
h∈H



对于每一个Xi,属于一个正态分布,对于整个离散数据集,每个Xi满足独立同分布,它们整体的均值的均值为u,均值的方差为σ,满足
即对于每一个噪声点,属于一个正态分布,对于整个噪声离散数据集,每个噪声点满足独立同分布,它们整体的均值的均值为0,均值的方差为σ,满足N(0,σ2)
符合中心极限定理的假设:

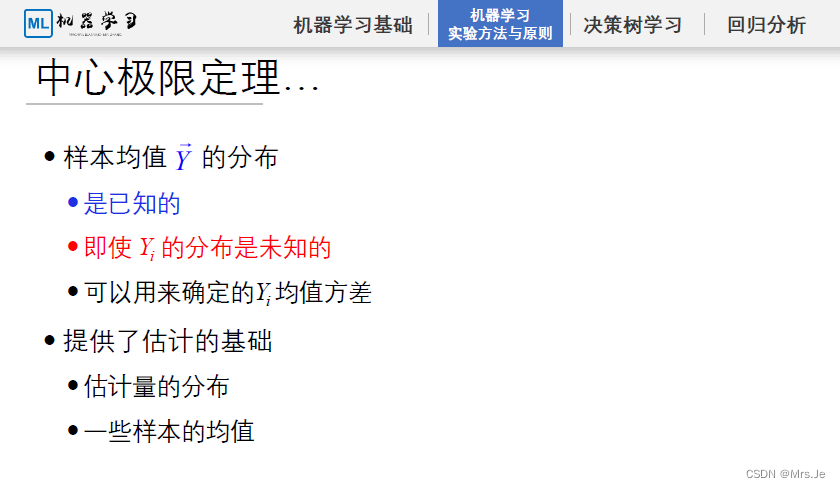
那么对于样本,或者由样本特征工程构造的特征X1,X2…Xn,如果X1的分布与X2的分布与Xn的分布之间相互独立且相同(满足独立同分布条件),则p(h(Xi))服从均匀分布,即满足“完全不知道假设,或者知道所有的假设发生概率相同”,即满足最大似然假设,那么可以通过此方法构建样本
对于0、1分类:
从朴素贝叶斯定理来说,
一个人有没有患有特定癌症:
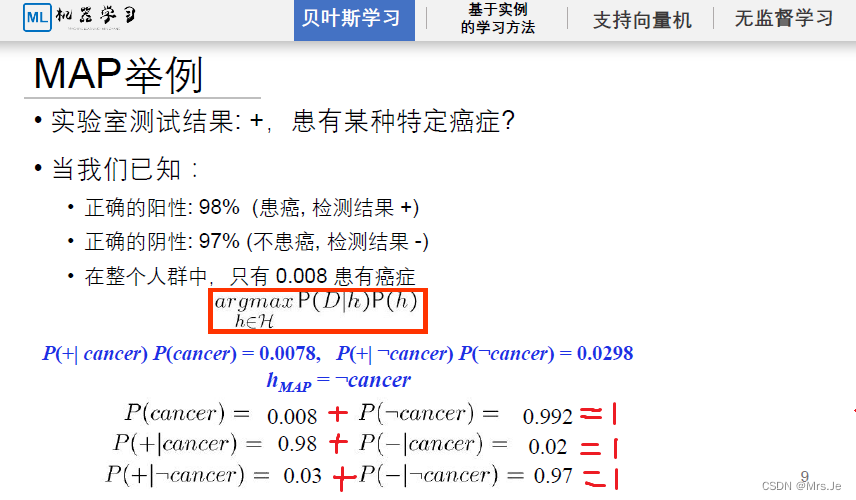
同时,一个人有没有患癌症还受到其他因子影响,如是否饮食不健康,家族是否有遗传因素,遗传因素有几种,是否抽烟,等等,这些因子与实验结果为正或者负,共同推出一个人是否患有癌症;
“判别式模型” (discriminative models)
判别式模型直接学习决策函数Y=f(x)或者条件概率 P(Y|X),不能反映训练数据本身的特性,但它寻找不同类别之间的最优分裂面,反映的是异类数据之间的差异,直接面对预测往往学习准确度更高。
判别式模型:要确定一个羊是山羊还是绵羊,用判别式模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
“生成式模型” (generative models)
生成式模型学习的是联合概率密度分布 P(X,Y),可以从统计的角度表示分布的情况,能够反映同类数据本身的相似度,它不关心到底划分不同类的边界在哪里。生成式模型的学习收敛速度更快,当样本容量增加时,学习到的模型可以更快的收敛到真实模型,当存在隐变量时,依旧可以用生成式模型,此时判别式方法就不行了。
生成式模型:是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,再放到绵羊模型中看概率是多少,哪个大就是哪个。
联系:判断依据都是条件概率P(y|x),但是生成式模型先计算了联合概率,再由贝叶斯公式计算得到条件概率。因此,生成式模型可以体现更多数据本身的分布信息,其普适性更广。
https://zhuanlan.zhihu.com/p/74586507
https://blog.csdn.net/weixin_42615847/article/details/127603081
https://qn1-next.xuetangonline.com/16551827061432.zip?attname=机器学习课件最终版PDF合集%20%203.zip















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









