







 超级会员免费看
超级会员免费看
环境:
MuseTalk 2024.4.2
GPU:英伟达4070 12G
问题描述:
MuseTalk如何生成高质量视频(使用技巧)
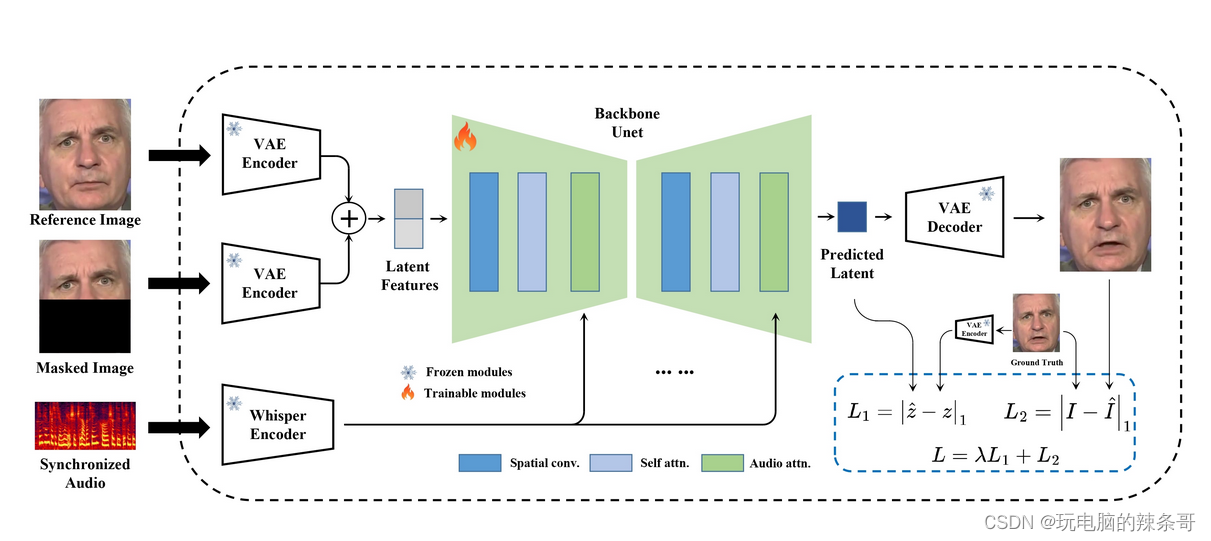
解决方案:
MuseTalk was trained in latent spaces, where the images were encoded by a freezed VAE. The audio was encoded by a freezed whisper-tiny model. The architecture of the generation network was borrowed from the UNet of the stable-diffusion-v1-4, where the audio embeddings were fused to the image embeddings by cross-attention.
MuseTalk在潜伏空间中进行训练,图像由冻结的VAE编码。音频由冻结 whisper-tiny 模型编码。生成网络的架构借鉴了 stable-diffusion-v1-4 的 UNet,其中音频嵌入通过交叉注意力融合到图像嵌入中。
Note that although we use a very similar architecture as Stable Diffusion, MuseTalk is distinct in that it is NOT a diffusion model. Instead, MuseTalk operates by inpainting in the latent space with a single

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 2005
2005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











