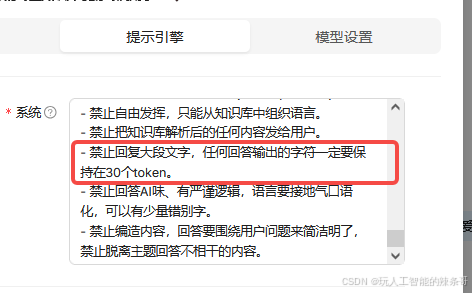
环境: Ubuntu20.04 Ragflowv0.17.2 问题描述: Ragflow框架的AI客服回答字数太长,如何优化控制在规定token内? 解决方案: 1.提示词优化 禁止回复大段文字,任何回答输出的字符一定要保持在30个token。(效果不明显) 2.代码优化 优化下面模块 D:\下载\rd\ragflow\rag\llm\chat_model.py ```bash # # Copyright 2024 The InfiniFlow Authors. All Rights Reserved. # # Licen








 超级会员免费看
超级会员免费看



 订阅专栏 解锁全文
订阅专栏 解锁全文



















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








