







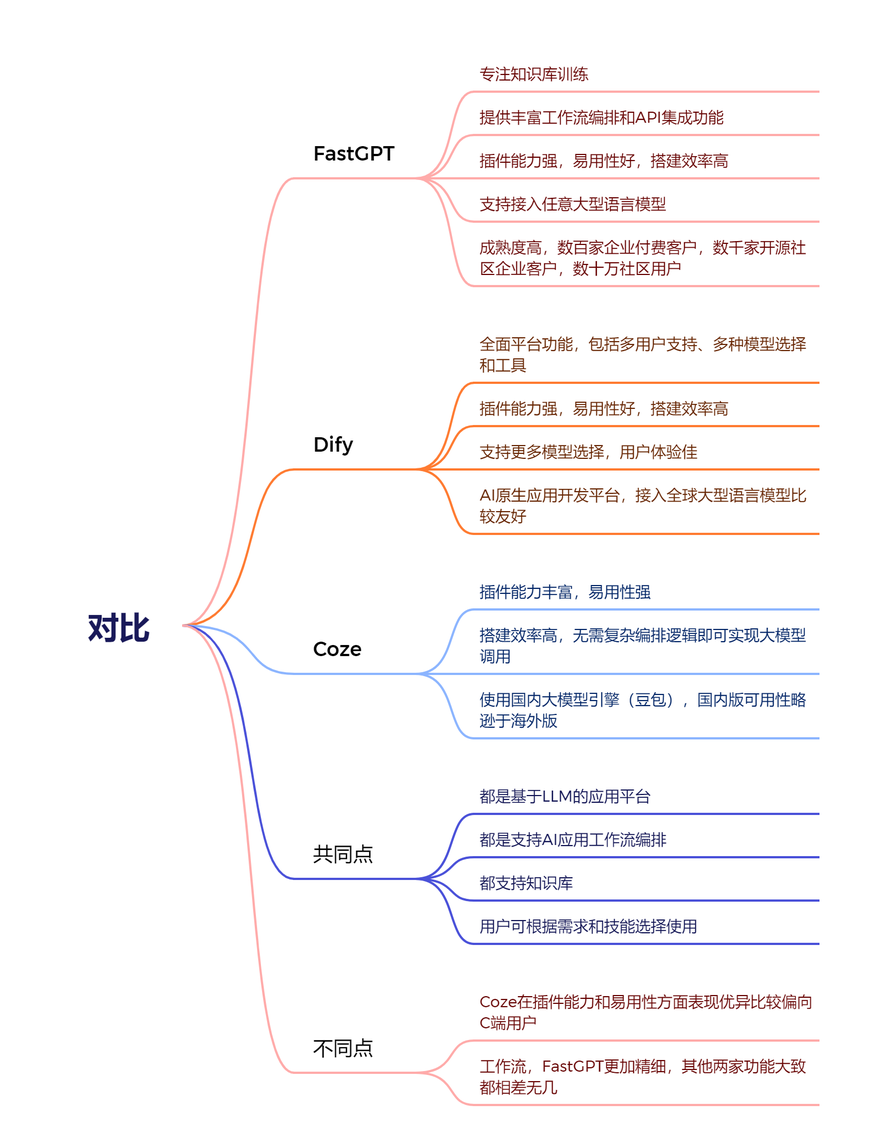
目录
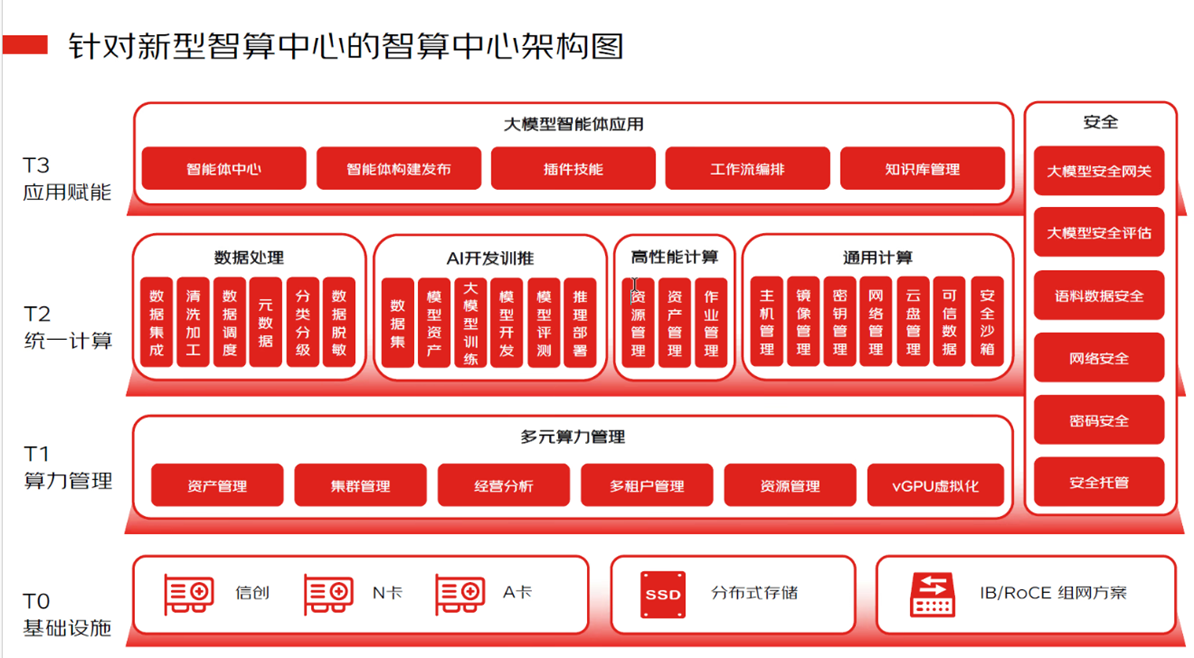
LLM智算平台架构图:
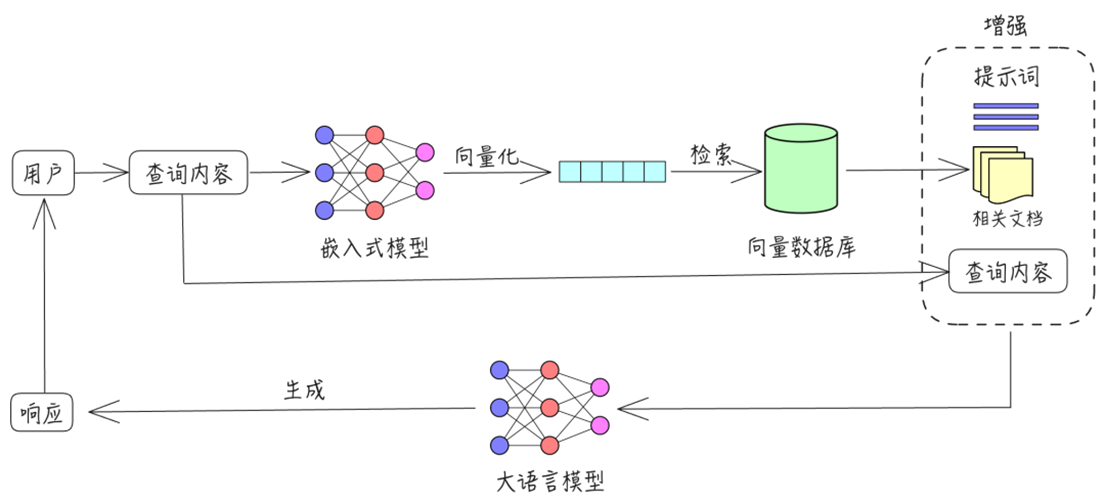
大模型问答流程图:
智能体(Agent):

智能体(AI Agent),又称“人工智能代理”,是一种模仿人类智能行为的智能化系统,它就像是拥有丰富经验和知识的“智慧大脑”,能够感知所处的环境,并依据感知结果,自主地进行规划、决策,进而采取行动以达成特定目标。简单来说,智能体能够根据外部输入做出决策,并通过与环境的互动,不断优化自身行为。
智能体本身既不是单纯的软件也不是硬件,而是一个更为宽泛的概念,它们可以是软件程序、机器人或其他形式的系统,具备一定的自主性和智能性。
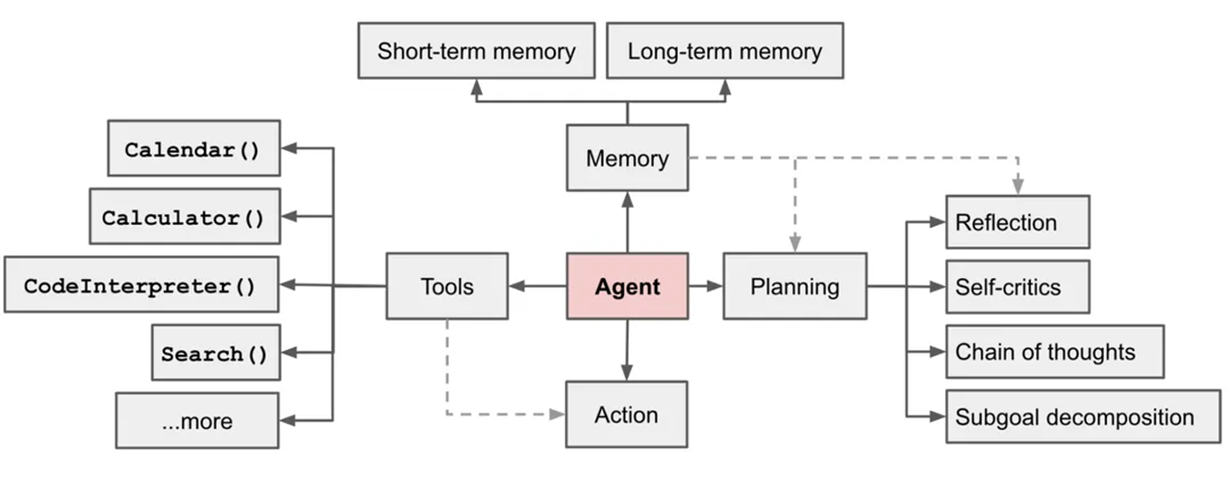
LLM:接受输入、思考、输出
人类:LLM(接受输入、思考、输出)+记忆+工具+规划
主流的智能体产品,
OpenAI的智能体——Operator
OpenAI的智能体产品——Deep Research
字节跳动的Coze(扣子)
文心智能体平台AgentBuilder
中国的创业公司Monica发布的全球首款通用Agent,manus

提示词的组成:
提示词通常由以下几个部分组成:
角色(Role):设定模型扮演的角色。例如,“作为一名专业医生,解释以下症状”。
指令或任务(Instruction/Task):明确告诉模型要完成的任务。例如,“生成一段描述夏季景色的文字”。
问题(Question):需要回答的问题。例如,“地球上最高的山峰是什么?”。
上下文(Context):提供必要的背景信息或相关细节,使模型更好地理解任务。例如,“在描述历史事件时,请考虑时间线和主要人物”。
示例(Example):给出具体的示例,帮助模型理解预期的输出格式或内容。“例如,描述一只猫时,可以这样写,‘这只猫有一身柔软的黑色毛发,眼睛如同绿宝石一般明亮。’”。
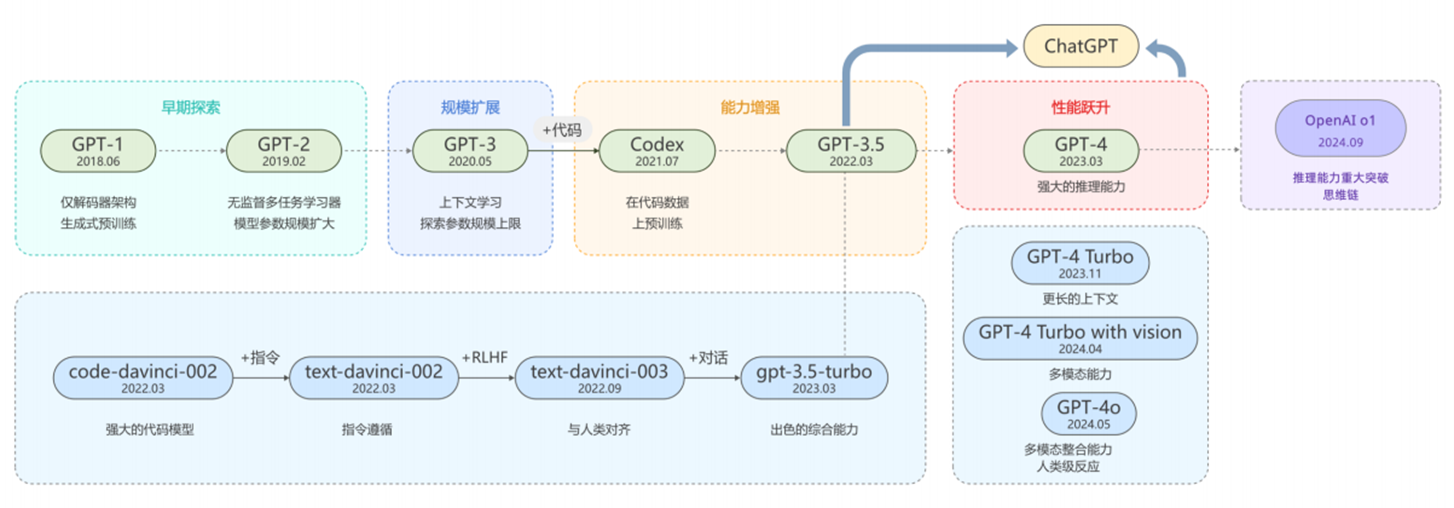
GPT成长史:
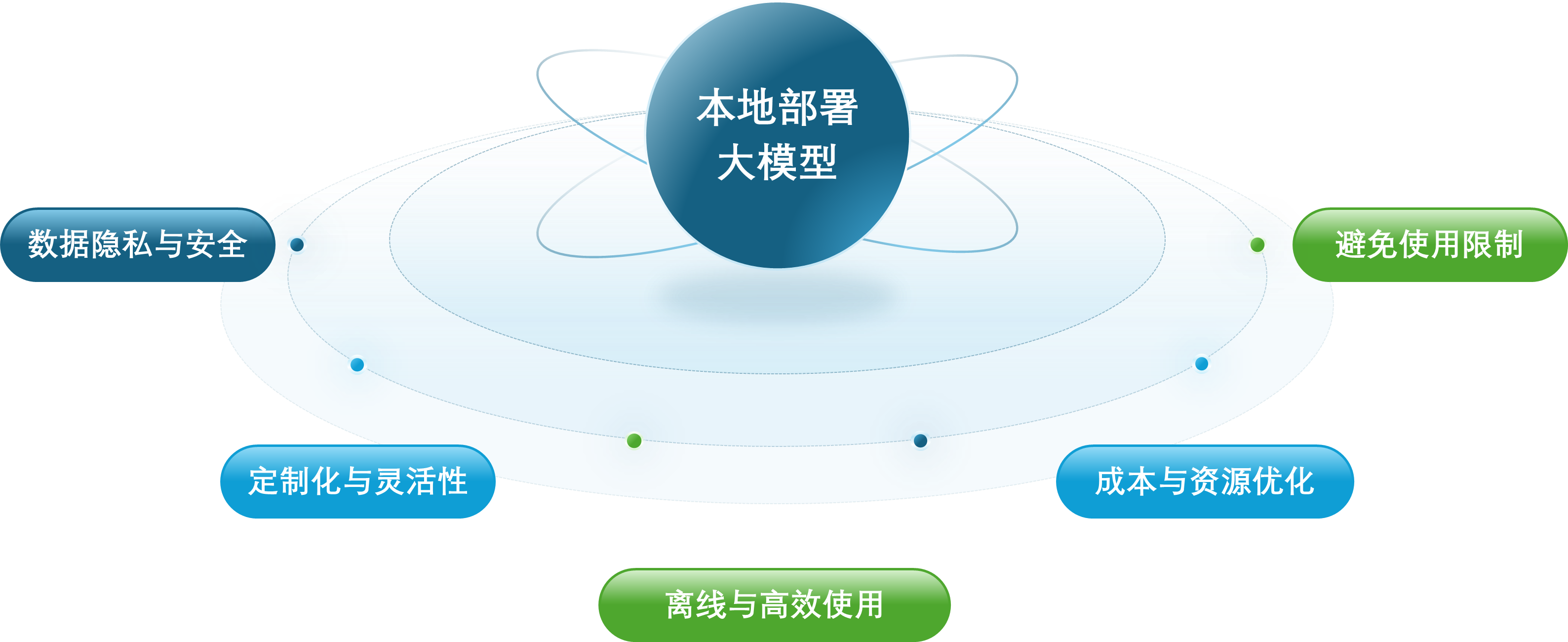
为什么需要本地部署大模型:
规模化部署 vLLM 的难点:
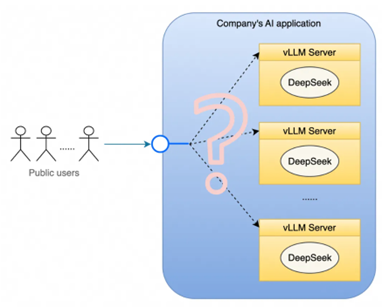
大规模参数量:LLM 之所以被称为“大”语言模型,很大程度上是因为其拥有极其庞大的参数规模,导致模型的体积通常可达数十至数百 GB。这种巨大的模型体积在服务启动时带来了模型文件下载、GPU 加载漫长的问题,需要设计专门的加速机制来应对。同时也额外增加了日常的模型上传、下载、调试和发布等产品迭代流程的额外时间成本。
高效推理能力:除了克服大镜像大模型带来的冷启动问题,LLM 还必须满足实时性要求极高的交互需求,能够在数秒甚至毫秒级别内返回推理结果,并确保每轮对话都能持续稳定高效地进行。这依赖 vLLM 与内嵌模型的交互能否合理利用缓存数据,维持对话的连续性和响应的速度。
上下文理解:在多数应用场景中,LLM 通过对话提供推理服务,因此服务必须确保每行对话之间的连贯性。避免每次对话被分配到不同的后端资源导致上下文信息丢失。LLM 同时需要稳定的长连接,为用户提供一个持久的交互窗口。这意味着底层系统必须能够有效地管理和协调众多底层资源生命周期,确保对话的连贯性和稳定性。
资源利用与波峰波谷管理:vLLM 业务对显卡集群的资源消耗呈现出明显的波峰和波谷特性。为了确保在业务高峰时段有足够的计算能力,企业通常会提前购买足量的显卡来覆盖峰值需求。然而,在非高峰时段(波谷),大部分显卡将处于空闲状态,造成资源浪费。这种时间上的使用不均,不仅增加了硬件闲置的成本,也降低了投资回报率。
资源使用不均衡与服务质量:即使在业务高峰期,显卡资源的使用也可能出现不均衡的情况。调度策略不当可能导致某些服务器的显卡、内存和 CPU 资源过度挤兑,而其他服务器则较为空闲。这种负载不均衡现象会影响整体的服务质量,降低用户体验。
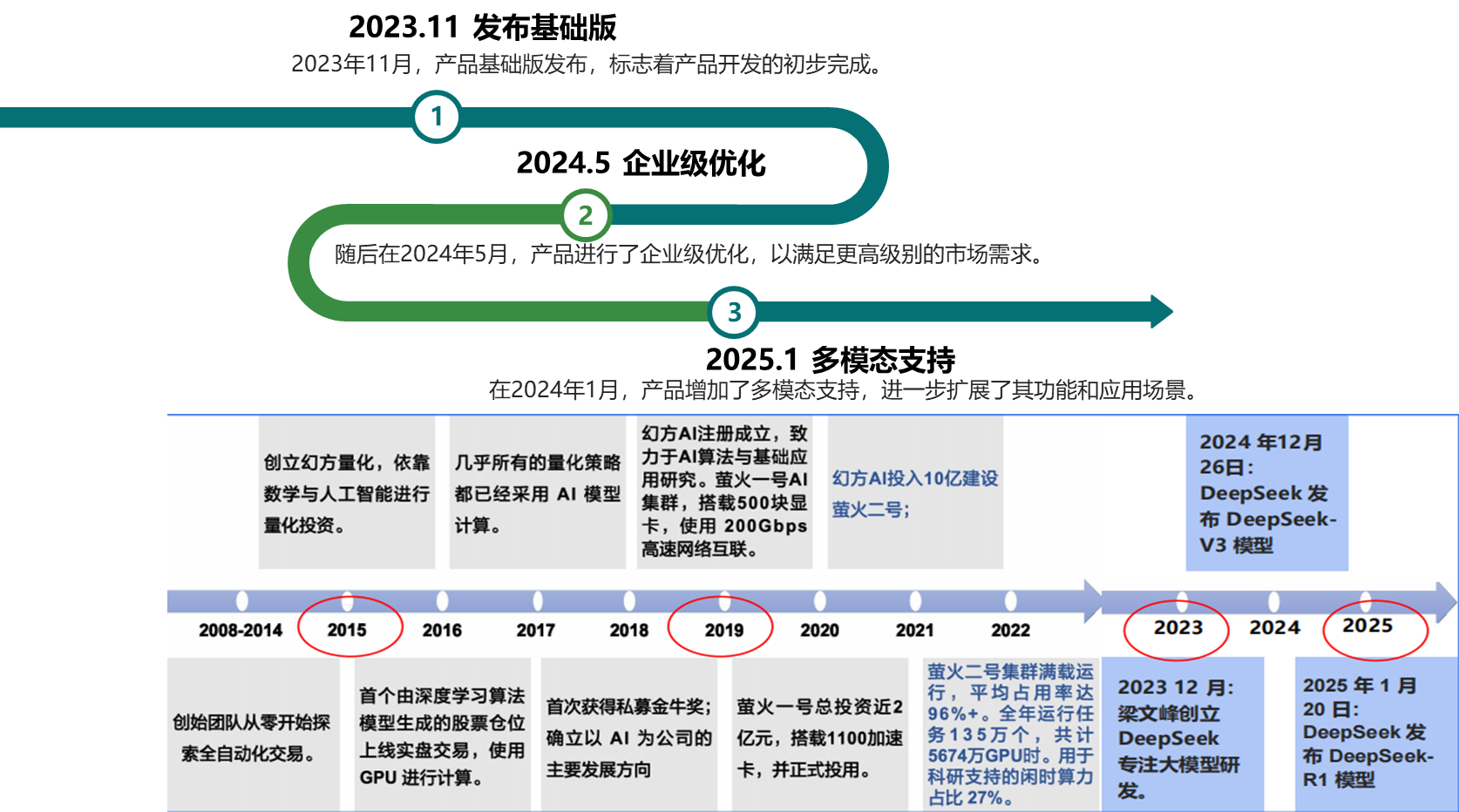
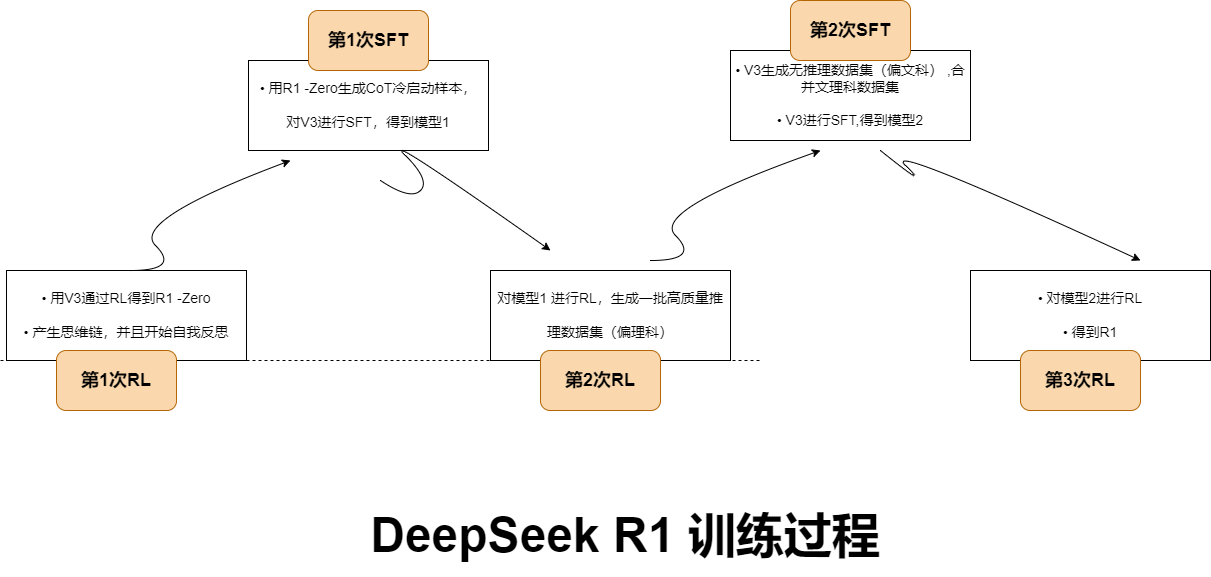
DeepSeek发展里程碑:
DeepSeek系列模型介绍:
DeepSeek 是由深度求索公司推出的大语言模型。大语言模型技术演进:DeepSeek-LLM、DeepSeek-V2、DeepSeek-V3、DeepSeek-R1。
其中:
DeepSeek LLMs是其发布的第一代大模型,在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型。
DeepSeek-V2是国产开源MoE大模型,性能达GPT-4级别,但开源、可免费商用、API价格仅为GPT-4-Turbo的百分之一。
DeepSeek-V3 是在14.8万亿高质量 token 上完成预训练的一个强大的混合专家 (MoE) 语言模型,拥有6710亿参数。作为通用大语言模型,其在知识问答、内容生成、智能客服等领域表现出色。
DeepSeek-R1 是基于 DeepSeek-V3-Base 训练生成的高性能推理模型,在数学、代码生成和逻辑推断等复杂推理任务上表现优异。
DeepSeek-R1-Distill 是使用 DeepSeek-R1 生成的样本对开源模型进行有监督微调(SFT)得到的小模型,即蒸馏模型。拥有更小参数规模,推理成本更低,基准测试同样表现出色。
| 版本 | 技术特点 | 主要贡献 | 数据集 | 性能与效率 | 其他 |
| DeepSeek LLM | 开源大语言模型,采用7B和67B两种配置;使用2万亿token数据集;引入多阶段训练和强化学习;通过直接偏好优化提升对话性能 | 提出扩展开源语言模型的规模;通过研究扩展规律指导模型扩展,在代码、数学和推理领域表现优异;提供丰富的预训练数据和多样化的训练信号 | 2万亿token(主要在英语和中文) | 在多个基准测试中优于LLaMA-2 70B,在中文和英文开放式评估中表现优异 | 强调长期主义和开源精神,强调模型在不同领域的泛化能力 |
| DeepSeek-V2 | 采用Mixture-of-Experts (MoE)架构,支持128K上下文长度;采用Multi-head Latent Attention (MLA) 和 DeepSeekMoE;提出辅助损失自由负载均衡策略;通过FP8训练提高训练效率 | 提出高效的MoE架构用于推理和训练通过MLA和DeepSeekMoE实现高效推理和经济训练;在推理吞吐量和生成速度上有显著提升 | 8.1万亿token(扩展到更多中文数据) | 在多个基准测试中表现优异,相比DeepSeek 67B节省42.5%的训练成本,提高最大生成吞吐量5.76倍 | 强调模型的高效性和经济性,提供多种优化策略以提高训练效率 |
| DeepSeek-V3 | 采用671B参数的MoE模型;采用多令牌预测训练目标;引入无辅助损失的负载均衡策略;支持FP8训练,实现高效的训练框架和基础设施优化 | 提出无辅助损失的负载均衡策略;通过多令牌预测增强模型性能;在多个基准测试中表现优异,接近闭源模型水平;在训练效率和成本上有显著优势 | 14.8万亿token(高质量和多样化) | 在多个基准测试中表现最佳,训练成本低,仅需2.788M H800 GPU小时,在推理和部署上表现出色 | 强调模型的高性能和经济性,提供多种优化策略以提高训练和推理效率 |
| DeepSeek-R1 | 通过大规模强化学习提升推理能力;采用冷启动数据和多阶段训练;提出从大模型中蒸馏推理能力到小型模型;在多个基准测试中表现优异 | 通过纯强化学习提升模型推理能力;通过冷启动数据和多阶段训练提高模型性能;通过蒸馏技术将推理能力扩展到小型模型 | 结合多种数据源进行训练,专注于推理任务的强化学习 | 在多个基准测试中表现优异,接近OpenAI o1-1217,在数学和编码任务中表现出色 | 强调模型的推理能力和泛化能力,提供多种优化策略以提高模型性能 |
DeepSeek-R1官方git仓库:
GitHub - deepseek-ai/DeepSeek-R1
DeepSeek-R1模型对比:
| 模型 | 参数量 | 硬件要求 | 总结 |
| DeepSeek-R1-Zero | 671B | 需超级计算机配置,包括大量显存、高性能GPU和强大处理器,通常需分布式计算 | 参数越大,硬件需求越强,尤其是GPU性能、内存容量和计算时间。个人用户适合较小的模型(如7b或8b),而更大的模型需要企业级资源 |
| DeepSeek-R1 | 671B | ||
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 中等性能,适用于个人用户。需要中型GPU如NVIDIA Quadro RTX 4000,内存需求约16GB | |
| DeepSeek-R1-Distill-Qwen-7B | 7B | 需稍高配置,如32GB内存,NVIDIA A100或T4系列GPU,运行时间较长。 | |
| DeepSeek-R1-Distill-Llama-8B | 8B | ||
| DeepSeek-R1-Distill-Qwen-14B | 14B | 更高性能,如64GB内存和A40级显卡,需更长的计算时间。 | |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 需更高配置,如80GB内存、A100或H100 GPU,适合企业级使用。 | |
| DeepSeek-R1-Distill-Llama-70B | 70B | 需超级计算机配置,包括大量显存、高性能GPU和强大处理器,通常需分布式计算 |
DeepSeek为什么火:

DeepSeek主要技术创新点:
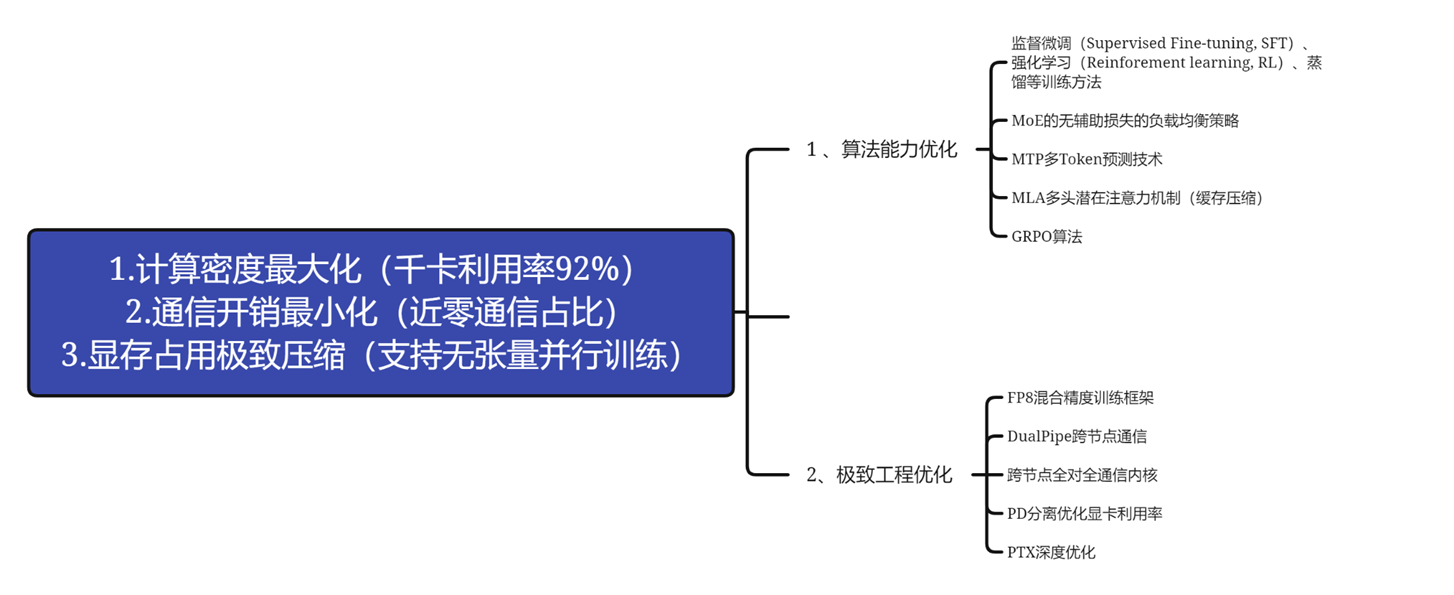
监督微调(Supervised Fine-Tuning,SFT)是一种在机器学习和自然语言处理领域中常用的技术,在已经预训练好的模型基础上,使用有标注的数据进行进一步训练,以调整模型的参数,使其更适应于特定的任务或领域。监督学习类似于,学生通过大量的“例题”学习,在明确的问答中增加模型能力,对就是对,错就是错。但是这里正确的问答对很重要,也就是所谓的训练数据,这就是为什么 deepseek 只开源模型,你也不好改造他模型的原因,训练数据弄不来。
强化学习(Reinforcement Learning,RL)是一种机器学习方法,强化学习的基础框架是马尔可夫决策过程,它允许智能体能够在与环境的交互中通过试错来学习最优策略。智能体在环境中执行行动,并根据行动的结果接收反馈,即奖励。这些奖励信号指导智能体调整其策略,以最大化长期累积奖励。强化学习就像厨师在做完菜之后,听取顾客的评价是好吃不好吃,主动优化菜谱,客人不对具体某一步指导,但为最后的口味买单。
MoE无辅助损失的负载均衡
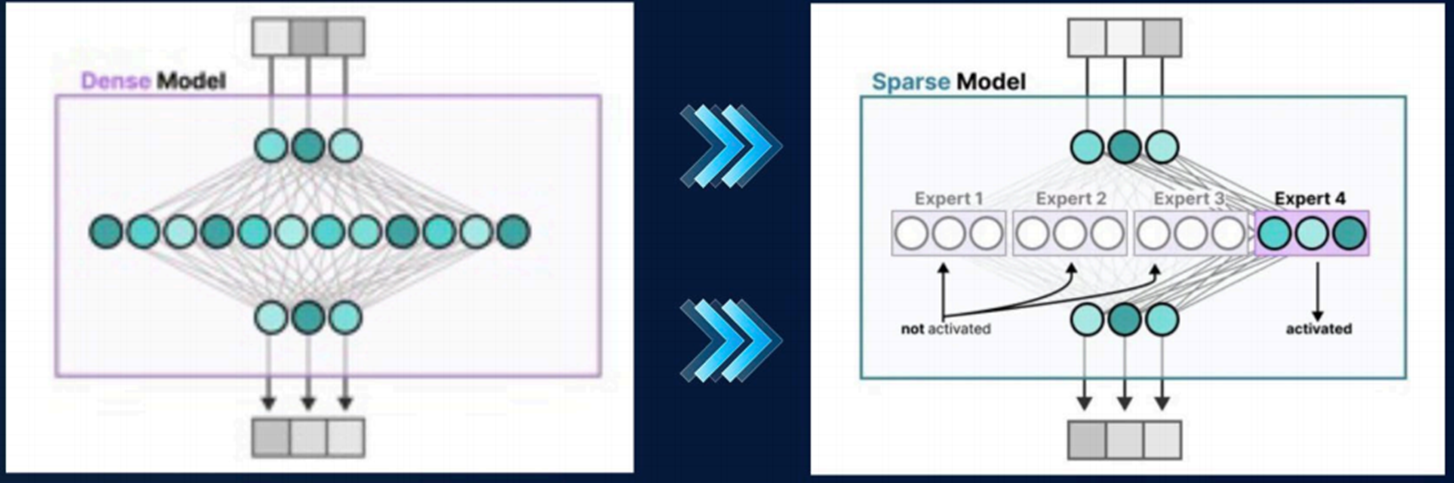
在模型计算过程当中,比起传统的所有节点“全员参与”,相当于有了一个新的分诊系统“moe层”,就类似于医院看病的导诊台,问一个问题,不同的问题由几个不同的科室专家配合完成,病人去医院看病,不用每个科室的大夫都凑在一起,模型不用全参数投入到每一次推理任务中,大大提升了效率、降低了对硬件资源的消耗。
DeepSeek采用无辅助损失函数的负载均衡策略,舍去了路由的优化目标,模型更专注于能力上的优化目标。相当于对分诊系统进行了优化,在计算(接待病人)的过程当中,让所有的专家“公平的”工作起来,防止偷懒,同时优化了任务分派体系,更加智能,平衡“专家科室”的压力。此技术优化让DeepSeek更高效地处理问题。
MTP多Token预测技术
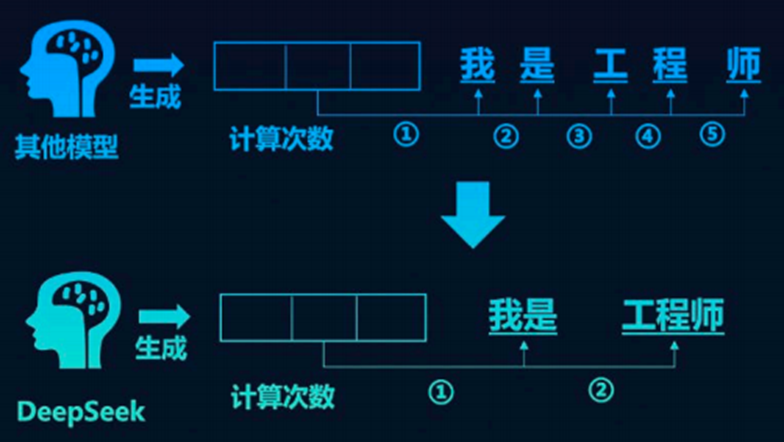
传统大语言模型是逐个生成Token,计算和通信量很大,MTP是同时生成连续Token。
优点:提升了训练时的模型智能,推理时的性能,输出更加连贯和准确。
一般来说,语言模型每次只能预测一个词,但 MTP 能让模型一次性预测多个词。这就像是在下棋时提前想好好几步棋,提升了计划和决策的效率
MLA-多头潜在注意力机制
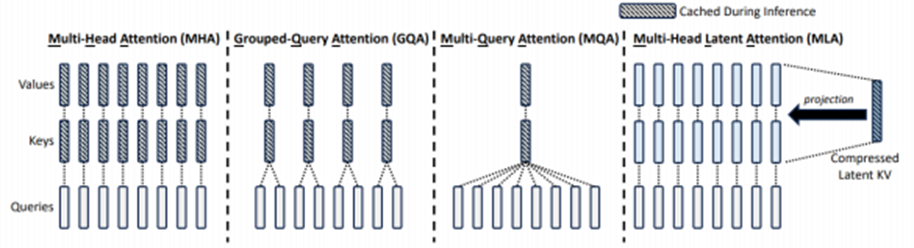
KV Cache技术和容量问题
• Transformer架构,每个Token都会重复计算之前所有Token,因此会把计算过的Key和Value缓存起来,就是KV-Cache,模型推理的显存消耗主要就是参数文件加KVCahe。
• 特点: KV-Cache提升推理性能,但是严重占用显存
DeepSeek在训练DeepSeek V2时独创了MLA压缩算法把一组Head的K和V的合并为一个隐藏变量
• 优点:显著缩小显存占用,降低推理成本,大幅度降低了运行时的显存需求,扩展了上下文长度
• 比喻:通过速记法,压缩了要记录的内容
GRPO算法
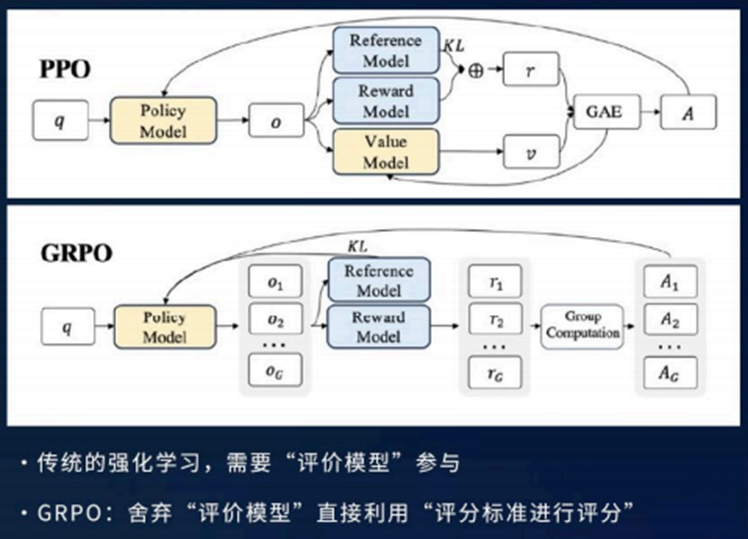
GRPO 是一种高效强化学习算法,旨在降低训练成本,同时避免传统方法对价值评估模型(Critic),的依赖。其核心思路是:通过组内输出的相对比较来估计策略更新的方向,而非依赖单独训练的评论家模型评估每个状态的价值。
高细粒度的MoE
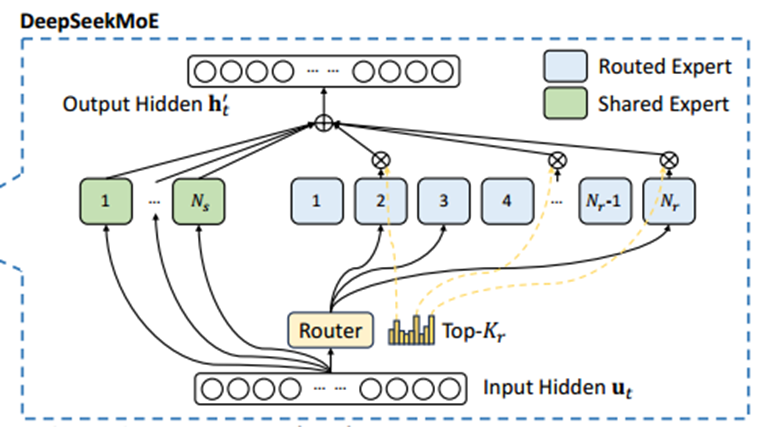
Deepseek使用moe架构,把大的神经网络拆成了256个“路由专家块”因此在训练过程中,专注训练每,个“专家模块”就像医院每个科室的医生专注的学习自己科室的知识,不用学习所有内容,因此降低了学习成本!
模型专业更加细分,通信成本更低,并充分挖掘了GPU资源
FP8混合精度训练框架
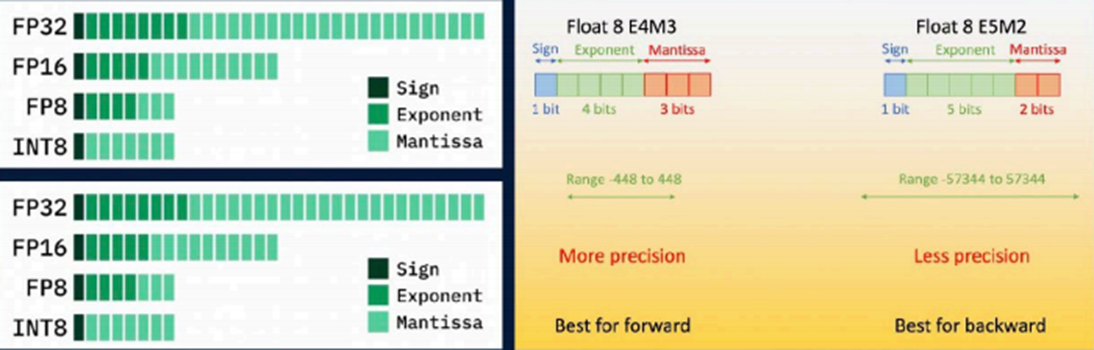
在这个框架中训练模型,大多数计算密集型操作都采用FP8精度进行,而一些关键操作则策略性地保持在它们原始的数据格式中,以平衡训练效率和数值稳定性。相比BF16/FP32减少50%显存和带宽占用
PTX优化技术
Nvidia为其GPU设计的一种中间指令集架构。
PTX位于高层次GPU编程语言(如CUDAC/C++或者其他语言前言)和低层次机器码(流式汇编或者SASS)之间。
PTX是一种close-to-metalISA,将GPU看作数据并行计算设备,因此允许进行细粒度优化。比如寄存器分配和线程级别的调整,这是CUDAC/C++和其他语言无法实现的。
当PTX进入SASS,它就会针对特定代的NvidiaGPU进行优化。
当训练V3模型时,DeepSeek对H800GPU进行重新配置:在132个SM中,其分配了20个用于服务器到服务器之间的通信,可能用于压缩和解压缩数据,以克服处理器的链接限制并加快事务处理速度。
为了最大化性能,DeepSeek也实现了先进的管线算法,可能时进行更加精细的线程调整。
特点:硬件利用率高,和特定产品型号深度绑定,难以移植。
想象一个繁忙的十字路口(代表GPU的计算和通信任务)普通交通管理(高层编程语言如CUDA):红绿灯按固定周期切换,所有车辆(计算/通信任务)必须排队等待。虽然规则简单,但高峰期容易拥堵,救护车(关键通信任务)可能被堵在车流中。
智能交通优化(PTX底层汇编)::交通工程师(开发者)直接调整红绿灯时序,为救护车开辟专用车道(定制通信内核),动态分配车道资源(如IB和NVLink带宽),甚至让部分车辆借道逆行(绕过默认调度规则)。最终,救护车能无阻通行,普通车辆也能高效流动。
DualPipe流水线优化
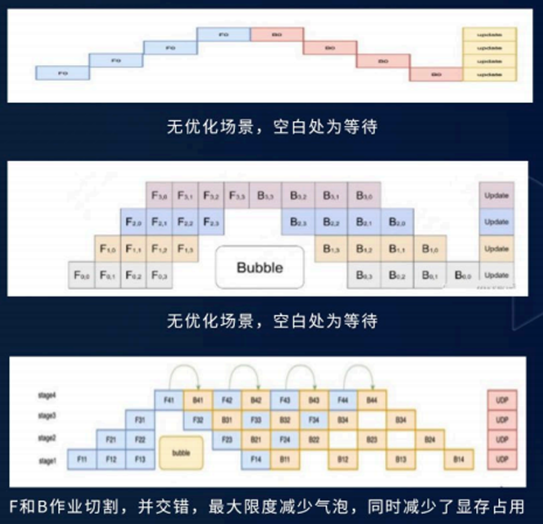
双流水线并行策略,让计算与通信近乎重叠
大大减少了训练时GPU不干活干看着的时间
PD分离优化技术
合理调配输入prefill和输出decode的算力
基本原理
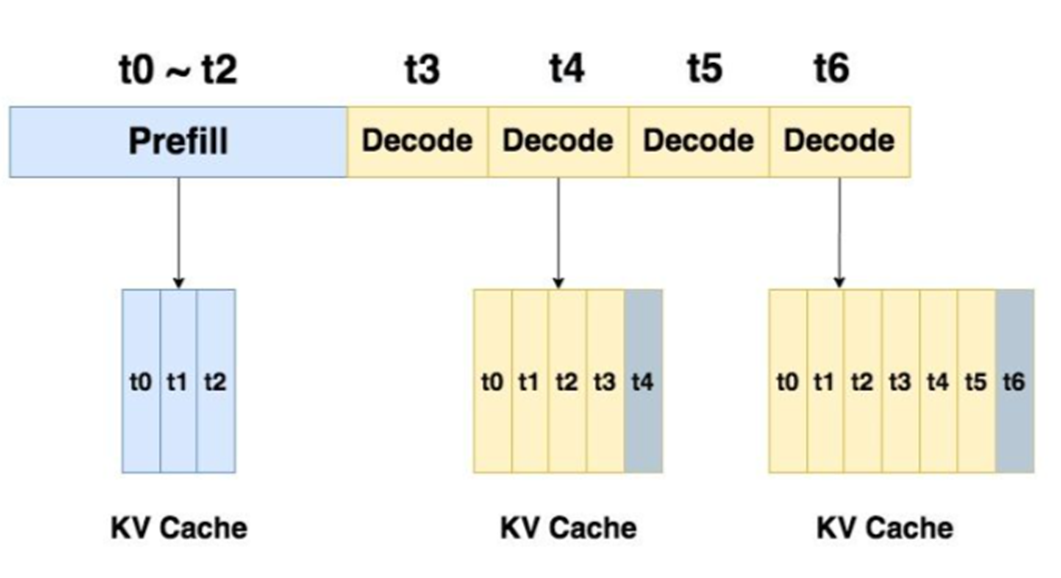
DeepSeek采用Transform架构,以decode(解码算法)为主
当用户提问时,首先要把问题做处理,这部分称为prefill,生成KV-Cache后就结束,然后把KV-Cache用于decode解码,得到输出内容,每个
Token都要访问KV-Cache。PD分离的话, GPU利用率提高,但是网络压力变大。为了让传输更精准,又搞了个PTX优化技术。
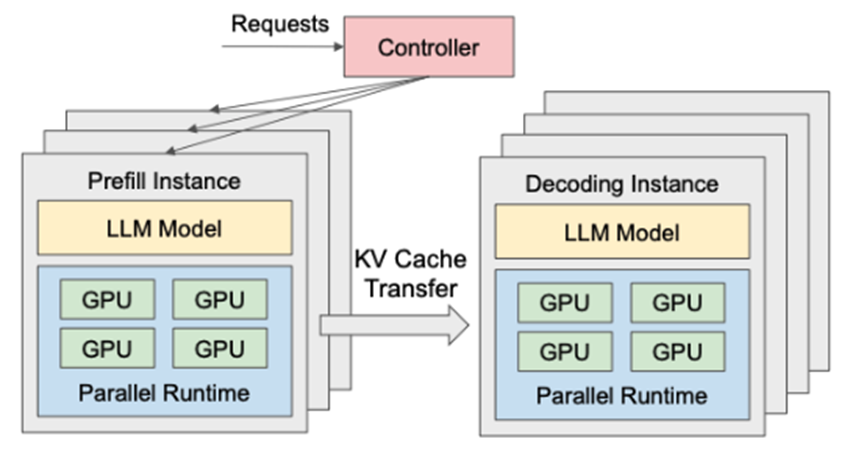
DeepSeek优化
把P和D放在不同计算单元上,精确匹配GPU资源和网络带宽
优点:提升了推理效率
PD分离和具体硬件配置高度耦合,具体方案不能直接用于其它配置
PD分离体现了DeepSeek的技术整合能力
未来可能出现专门为PD分离设计的GPU(双功能CPU,或单CPU双功能芯片)
P对计算能力要求高(可以并行), D对显存带宽要求高(不能并行,只能缓存)
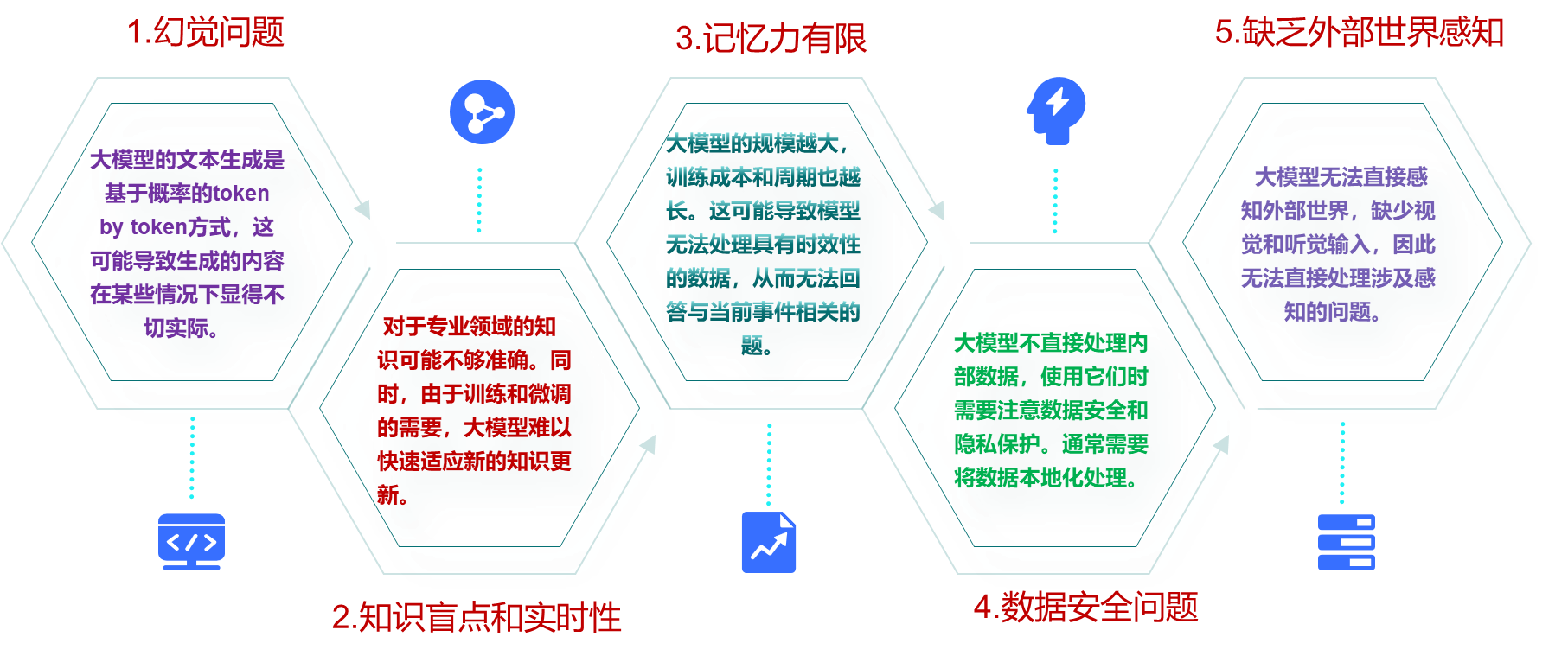
大模型的局限性:
大模型开源的几个层次:
模型框架
即提供模型的设计方案(算法)。 难以用于重现
模型代码
即直接给出模型的开发源码。
参数文件
给出已经训练好的模型参数文件,用户可以部署使用
训练数据
因为数据涉及众多产权、安全等问题,目前大模型开源训练数据的比例很低
过程文档
研发过程文档,非代码和数据类的设计、实施、维护文档
结论:开源模型无法继续训练,可以用于微调和推理, 无法深度利用思考过程
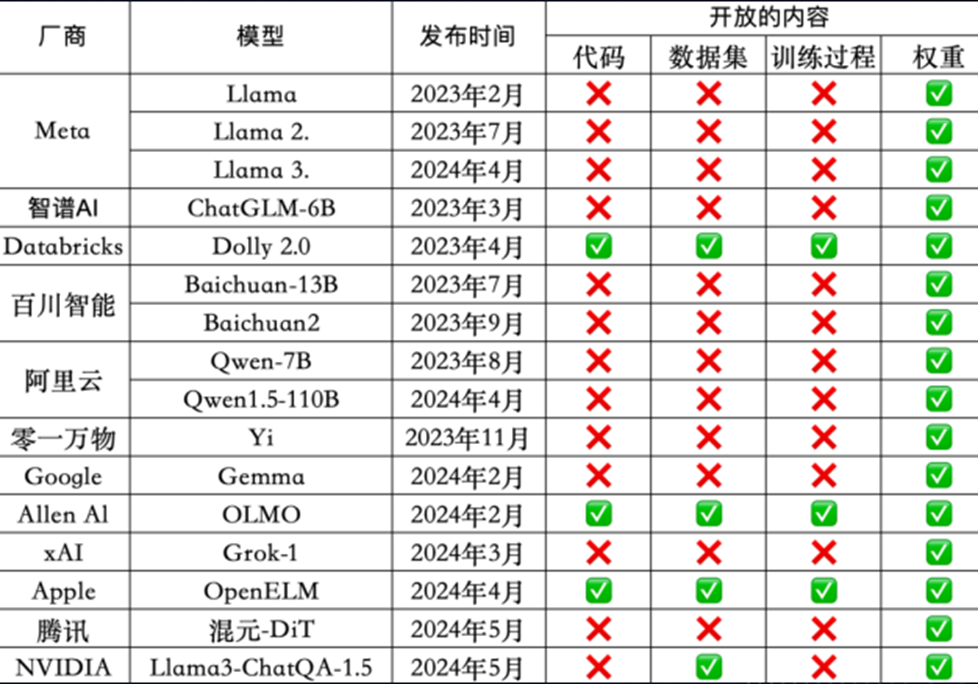
大模型部署工具对比:
| 工具名称 | 性能表现 | 易用性 | 适用场景 | 硬件需求 | 模型支持 | 部署方式 | 系统支持 | 总结 |
| SGLang v0.4 | 零开销批处理提升1.1倍吞吐量,缓存感知负载均衡提升1.9倍,结构化输出提速10倍 | 需一定技术基础,但提供完整API和示例 | 企业级推理服务、高并发场景、需要结构化输出的应用 | 推荐A100/H100,支持多GPU部署 | 全面支持主流大模型,特别优化DeepSeek等模型 | Docker、Python包 | Linux | 综合来看,如果您是专业的科研团队,拥有强大的计算资源,追求极致的推理速度,那么 SGLang 无疑是首选,它能像一台超级引擎,助力前沿科研探索;要是您是普通的个人开发者、学生,或是刚踏入 AI 领域的新手,渴望在本地轻松玩转大模型,Ollama 就如同贴心伙伴,随时响应您的创意需求;对于需要搭建大规模在线服务,面对海量用户请求的开发者而言,VLLM 则是坚实后盾,以高效推理确保服务的流畅稳定;而要是您手头硬件有限,只是想在小型设备上浅尝大模型的魅力,或者快速验证一些简单想法,LLaMA.cpp 就是那把开启便捷之门的钥匙,让 AI 触手可及。 |
| Ollama | 继承 llama.cpp 的高效推理能力,提供便捷的模型管理和运行机制 | 小白友好,提供图形界面安装程序一键运行和命令行,支持 REST API | 个人开发者创意验证、学生辅助学习、日常问答、创意写作等个人轻量级应用场景 | 与 llama.cpp 相同,但提供更简便的资源管理 | 模型库丰富,涵盖 1700 多款,支持一键下载安装 | 独立应用程序、Docker、REST API | Windows、macOS、Linux | |
| VLLM | 借助 PagedAttention 和 Continuous Batching 技术,多 GPU 环境下性能优异 | 需要一定技术基础,配置相对复杂 | 大规模在线推理服务、高并发场景 | 要求 NVIDIA GPU,推荐 A100/H100 | 支持主流 Hugging Face 模型 | Python包、OpenAI兼容API、Docker | 仅支持 Linux | |
| LLaMA.cpp | 多级量化支持,跨平台优化,高效推理 | 命令行界面直观,提供多语言绑定 | 边缘设备部署、移动端应用、本地服务 | CPU/GPU 均可,针对各类硬件优化 | GGUF格式模型,广泛兼容性 | 命令行工具、API服务器、多语言绑定 | 全平台支持 |
其他:
TRT-LLM,(NVIDIA官方支持)用于在NVIDIA GPU平台做大模型推理部署工作。
LMDeploy,由MMDeploy和MMRazor团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。
大模型前后端平台:
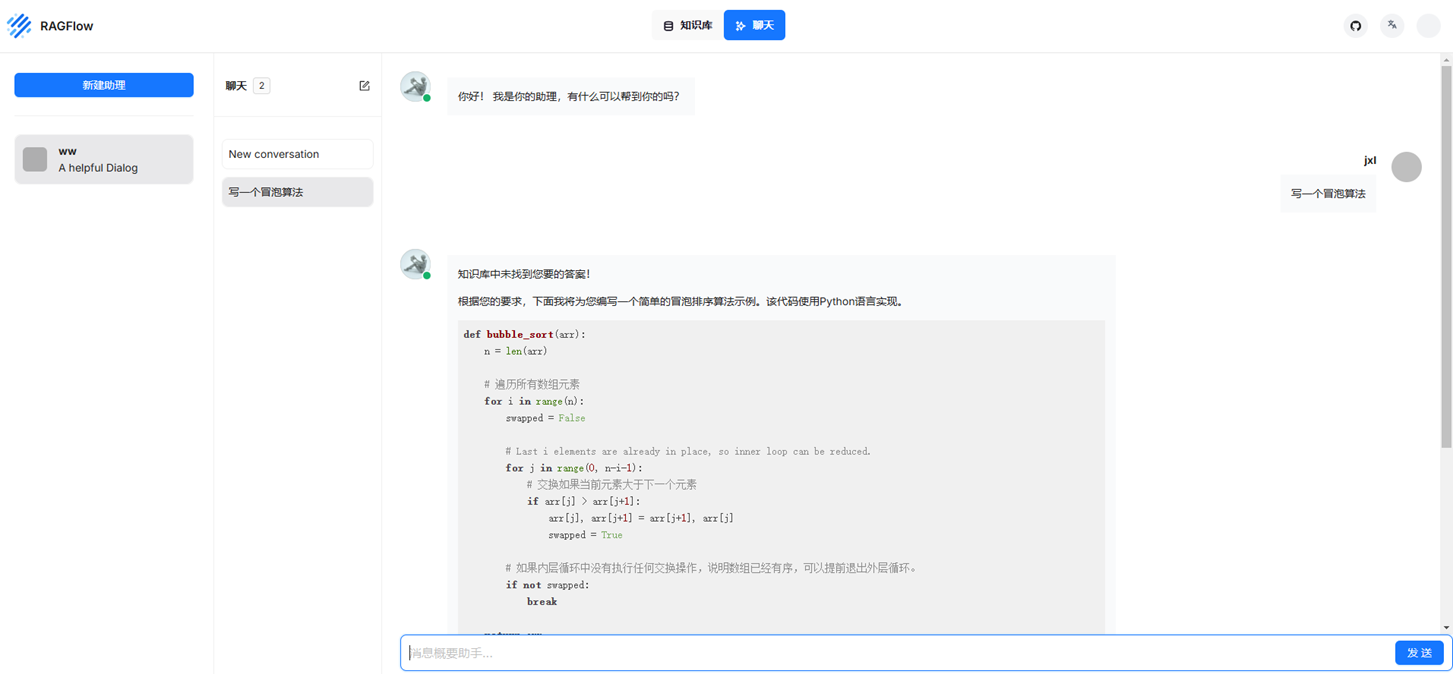
LangChain,集成了RAG(基于chatglm3-6b的演示,http://10.1.12.10:8501/)
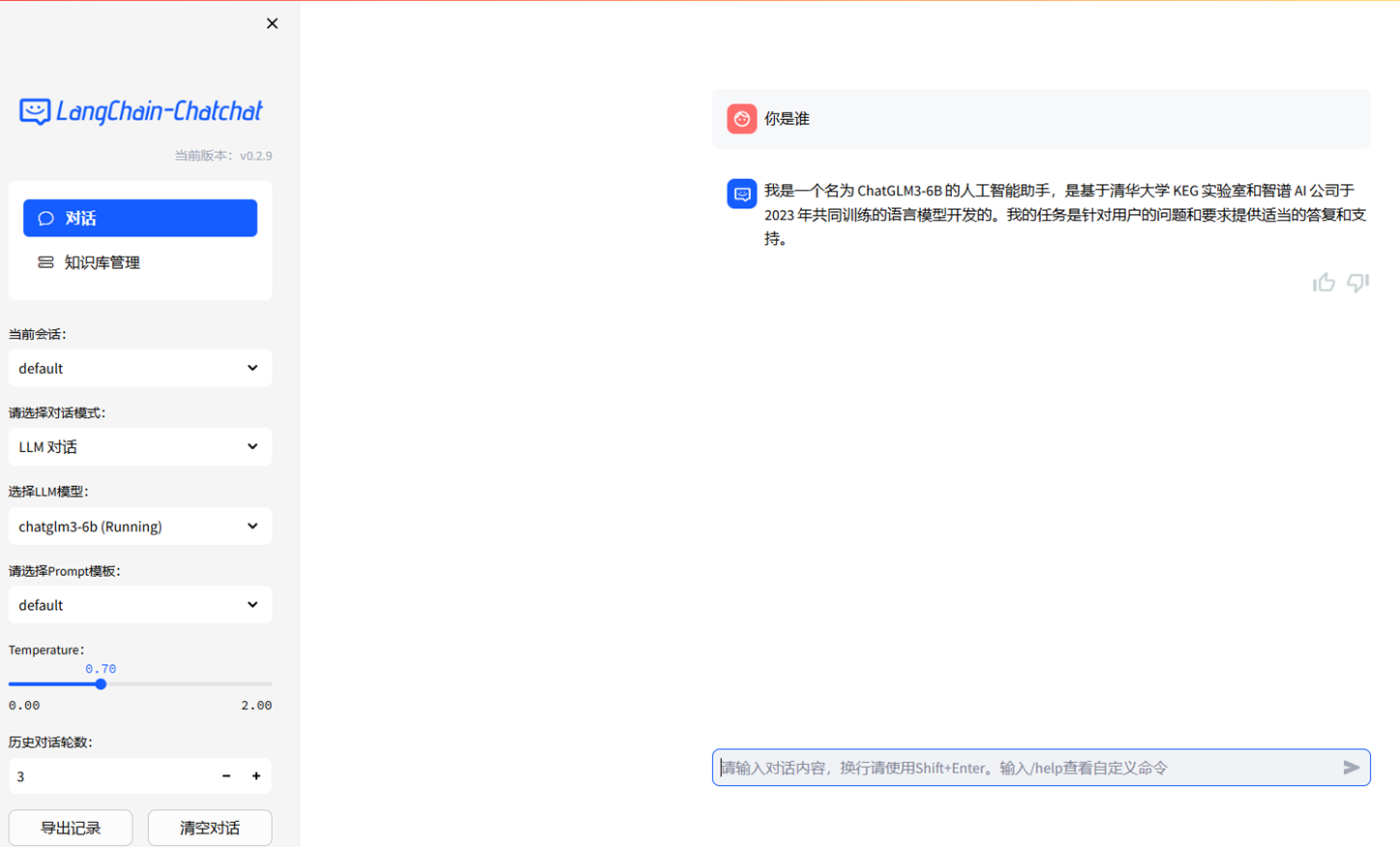
Dify,比较笨重,提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,使用软件涉及了redis、nginx、milvus|、sandbox等,个人认为是最强大的平台,和coze类似,尤其是流程引擎可以做很多事情,还支持发布,更偏向开发人员。(http://10.1.12.10/signin)
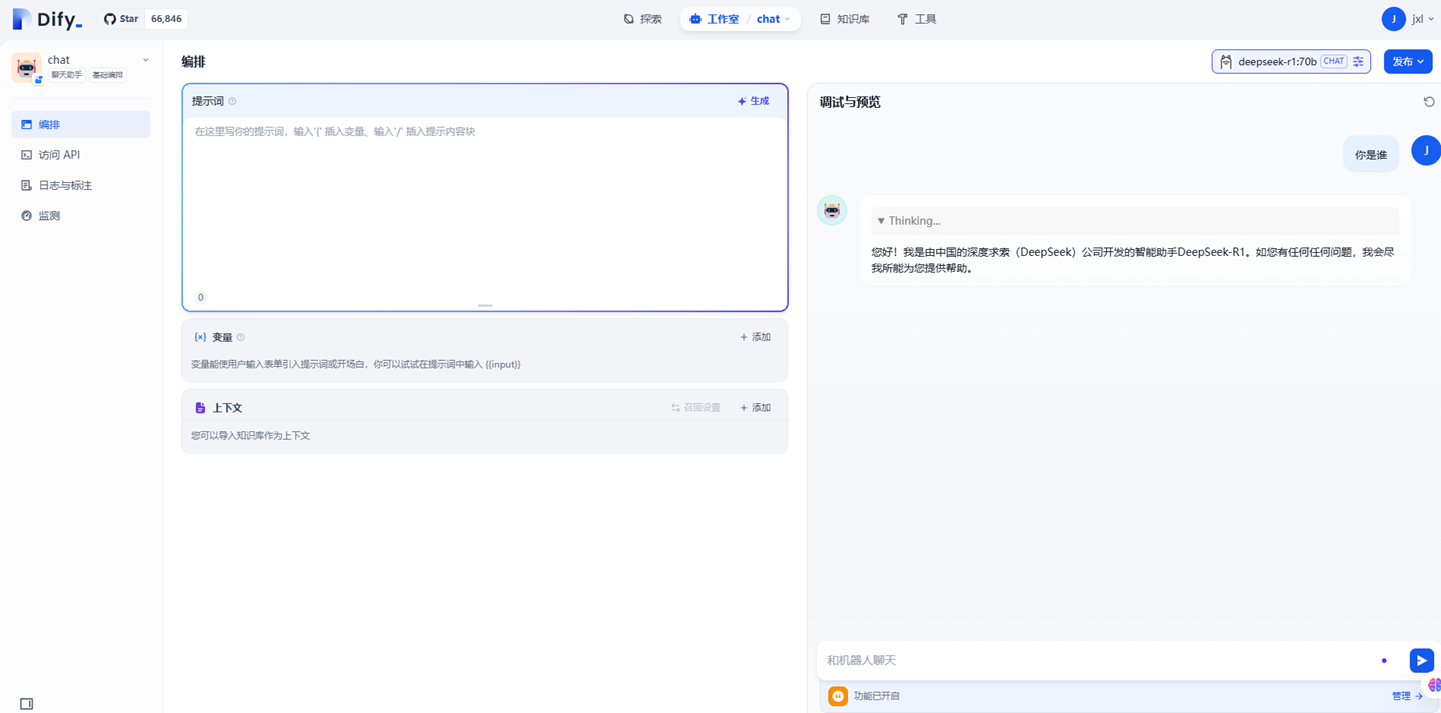
Ragflow,比较笨重,具备用户管理,集成了RAG,速度很慢,使用软件涉及了es,minio,mysql等,基于助手的产品设计思路不苟同(http://10.1.12.10:80/)
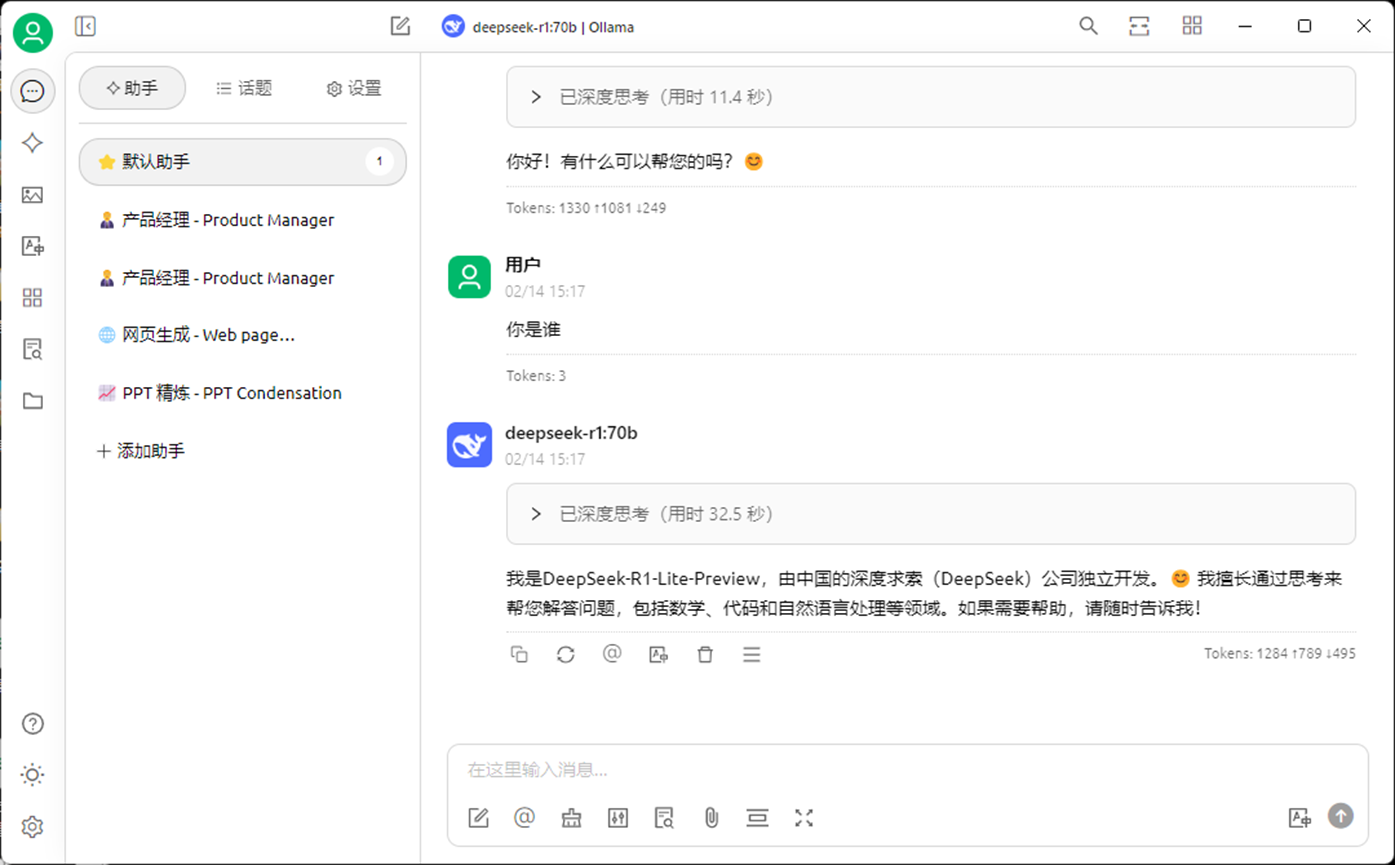
Open WebUI,具备用户管理,语音朗读,多模型同时问答(基于qwen2.5-7b、deepseek-r1:70b的对比演示,http://10.1.12.10:9010/)
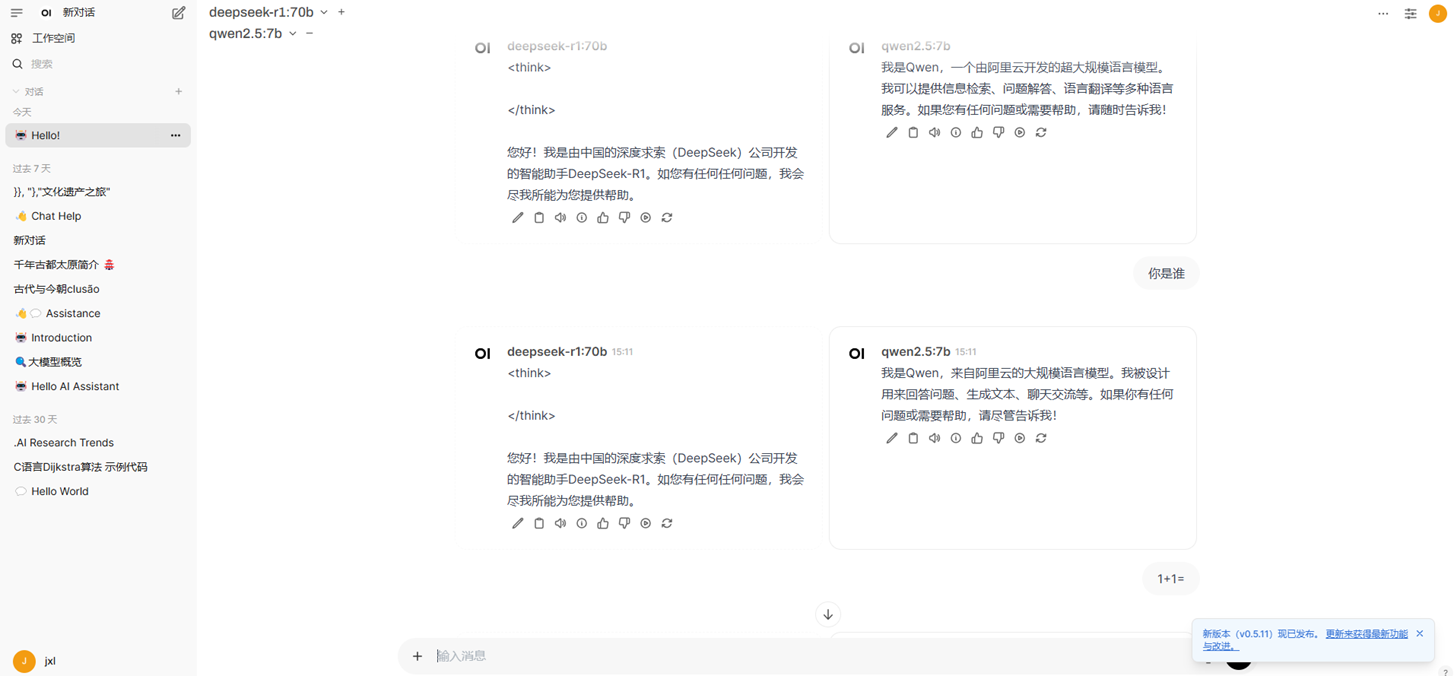
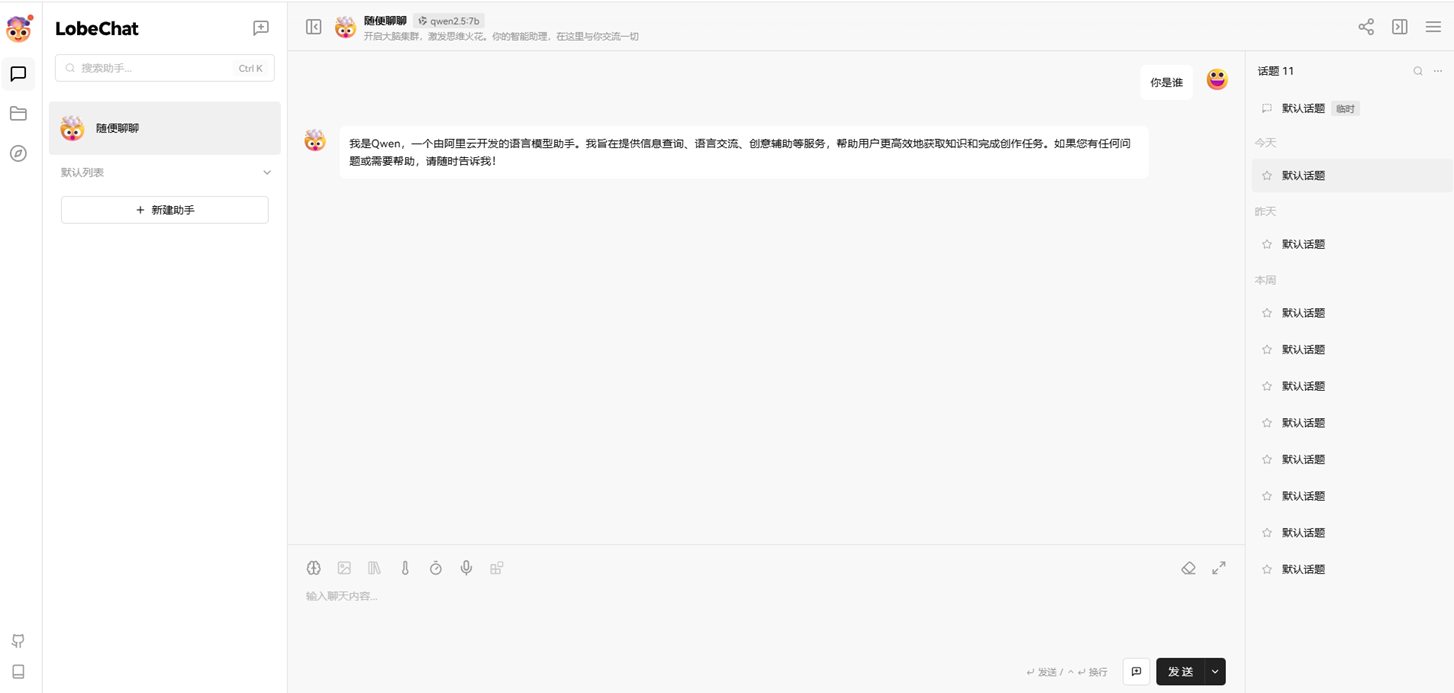
LobeChat,可以基于客户端部署模型(基于qwen2.5-7b的演示,http://10.1.12.10:3210/)
cherry-studio,集成了市场上的大模型、智能体等(本地桌面版)
Chatbox AI
Page Assist
coze
FastGPT
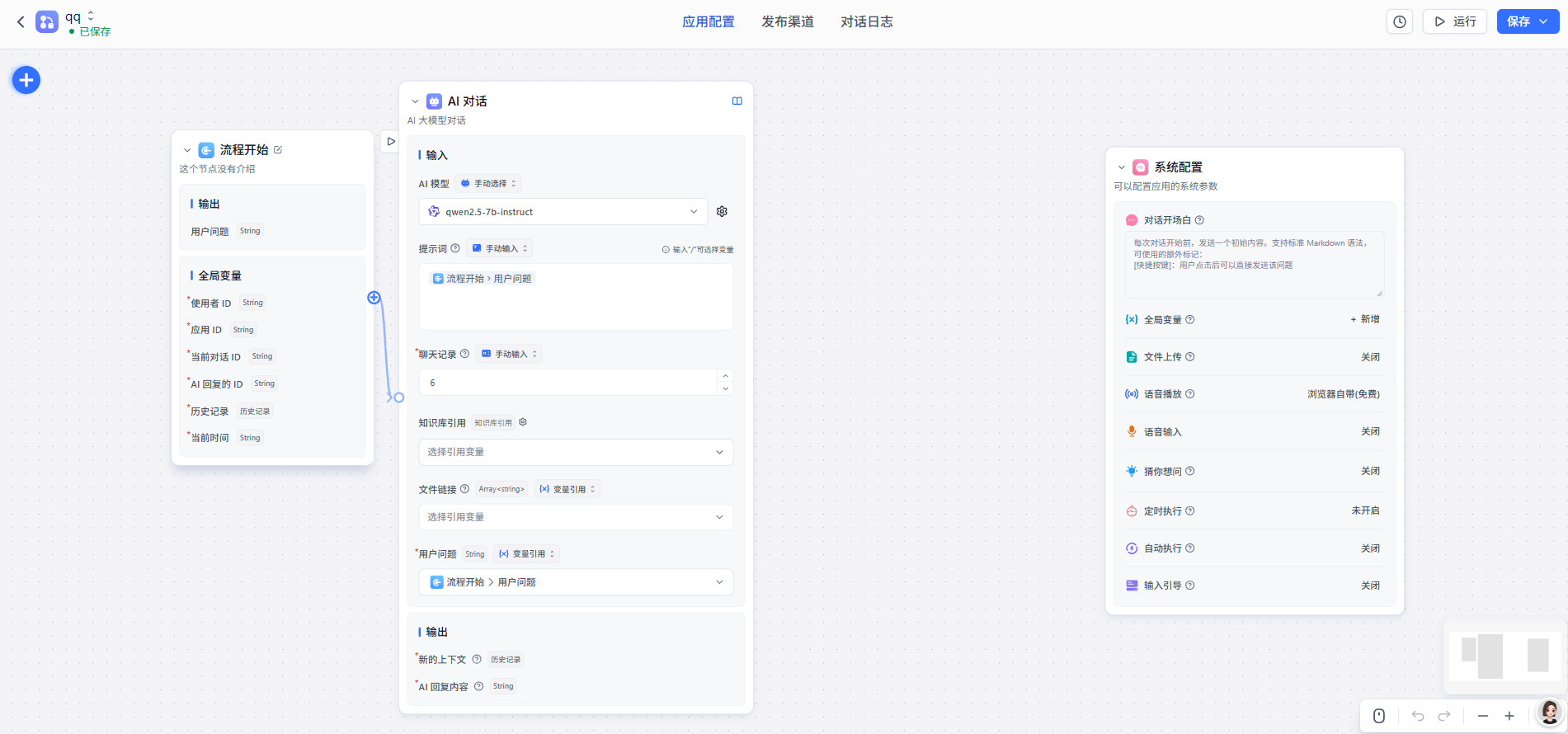
LLM推理速度指标:
LLM推理速度的指标主要包括:
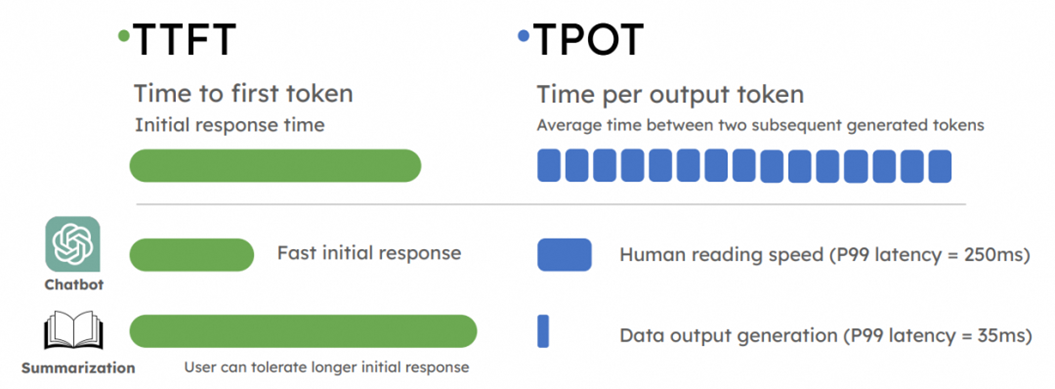
1. Time to First Token(TTFT),第一个Token出来的延迟:
用户在输入查询后开始看到模型输出的速度,低等待响应时间在实时交互中至关重要,
2. Time Per output Token(TPOT),每输出令牌时间:
为每个查询系统生成输出令牌所需的时间。这个指标对应于每个用户对模型“速度”的感知。
3. 延迟:
模型为用户生成完整响应所需的总时间。
延迟计算公式为:延迟=(TTFT)+(TPOT)*(要生成的令牌数量)。
4.吞吐量
推理服务器每秒可以跨所有用户和请求生成的输出令牌数。
这些指标共同决定了LLM服务的性能,包括响应速度和处理能力。
这些指标的测试工具是采用vllm的benchmark_serving或者采用sglang.bench_serving
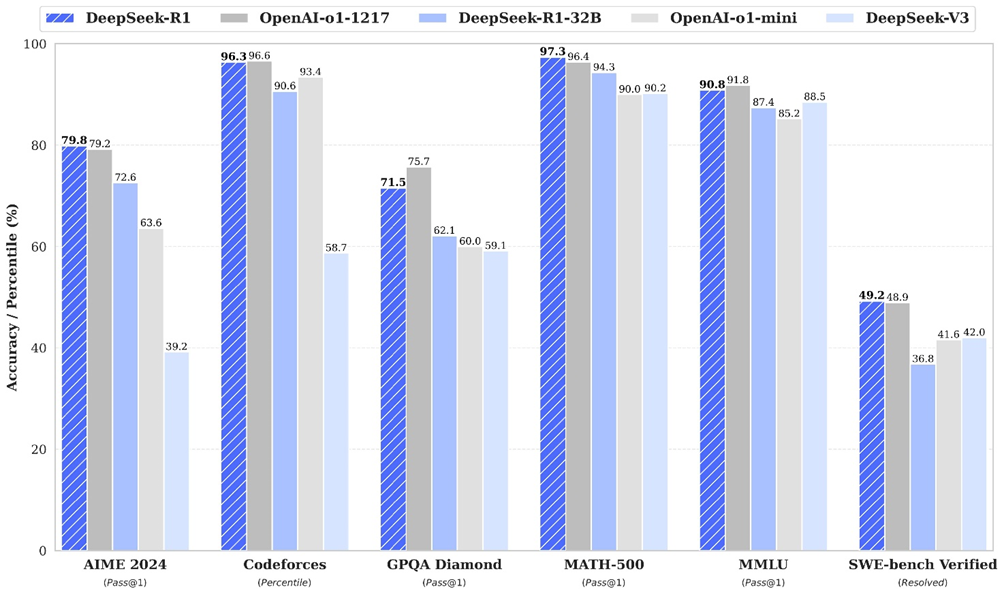
LLM精度指标:
GPQA,(Graduate-Level Google-Proof Q&A Benchmark)研究生级别的谷歌防护问答基准
MMLU,(Massive Multitask Language Understanding)测量大量多任务的语言理解
SWE-bench Verified,(OpenAI 推出更可靠的代码生成评估基准)
MATH500,(高中竞赛级别题目)测量数学问题解决能力
AIME2024,(American Invitational Mathematics Examination)美国奥数比赛
Codeforces,(为计算机编程爱好者提供在线评测系统的俄罗斯网站)
DROP,(Discrete Reasoning Over Paragraphs)需要对段落进行离散推理的阅读理解基准
MGSM,(Multilingual General Semantic Understanding),多语言小学数学基准,语言模型作为多语言思维链推理者
HumanEval,(评估在代码上训练的大型语言模型)
MMMU,(More Robust Multi-discipline Multimodal Understanding Benchmark),用于专家通用人工智能的大规模多学科多模态理解和推理基准
大模型命名方式:
1. 主版本号、日期
(1)GPT 3.5 → GPT 4,版本号递增,能力有重大提升,如生成更精准、逻辑更连贯。
(2)日期编码如claude-3-5-sonnet-20241022,末尾日期表明更新时间。
2. 参数规模
(1)B = Billion(十亿):如“70B”就表示模型有700亿参数(例:DeepSeek-R1-Distill-Llama-70B)
(2)T = Trillion(万亿):如“1T”表示模型拥有1万亿参数(例:Google PaLM-2-1T
(3)Small/Base/Large:表示某一系列模型的不同参数规模,参数量只是相对的多少,类似于小杯、中杯、大杯,如:7B→13B→70B(例:deepseek-vl2-small)
3. 功能定位
- Instruct:通常专注于执行指令型的任务,确定性高,如查询解析、自动化工具、指令问答等(例:Qwen2.5-14B-Instruct-1M)
- Chat:通常擅长于模拟人类之间的自然对话,更加自然,比如客服、聊天、多轮对话等(例:DeepSeek-Chat-32B)
- Coder:擅长代码的生成、解释等等(例:Qwen2.5-Coder)
- Math:擅长于数学方面的逻辑推理(例:Qwen2.5-Math)
(5)VL:视觉类;Audio:语音类
4. 技术类型
训练参数
- 4e1t:4个训练周期+1万亿token(例:Llama-3-8B-4e1t)
(2)1M:支持百万token上下文(例:Qwen2.5-14B-1M)
权重量化
- FP(浮点精度):保留完整小数精度,适合训练和高精度推理
(2)INT(整数量化):通过缩放因子将权重转换为整数,牺牲精度换取效率,INT8 > INT4
特殊技术
- GPTQ:针对LLM优化的后训练量化方法(例:Llama-2-7B-GPTQ)
- AWQ:激活感知权重量化(例:Qwen1.5-14B-AWQ)
- GGUF:优化推理格式,变成GGUF格式可以更快地被载入使用
- MoE:混合专家架构(例:Mixtral-8x7B)
(5)Distill:知识蒸馏技术(例:DeepSeek-R1-Distill-Qwen-32B)
训练方法
- SFT:监督微调(例:Claude-3-70B-SFT)
(2)RLHF:人类反馈强化学习(例:GPT-4-RLHF)
大模型的Tokens:
人类是以字数来计算文本长度,大语言模型 (LLM)是以 Token 数来计算长度的。在自然语言处理技术领域,Tokens是文本处理的基本单位。
Token计费将输入和输出的文本统一折算为可量化的单位,例如输入1k Token + 输出2k Token = 总费用3k Token,这样一来,用户可直观控制成本。
传统API按次收费(如每次0.01元)无法区分简单查询与复杂任务的资源差异。
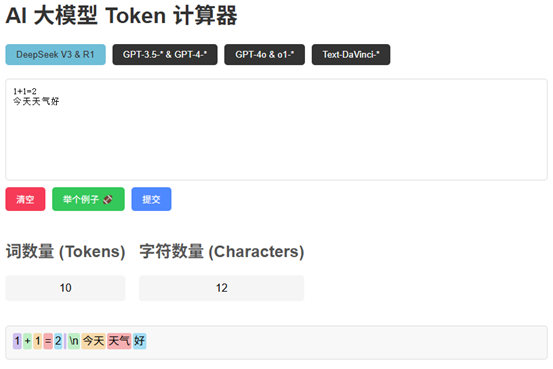
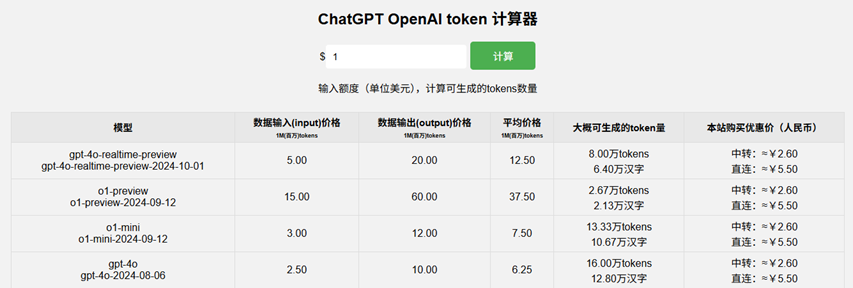
eg:腾讯混元大模型1Token ≈1.8个汉字,通义千问1Token ≈ 1个汉字,而英文1Token可能对应3-4个字母或一个单词。
网址:AI 大模型 Token 计算器 Token在线计算器
网址:ChatGPT OpenAI token 计算器 1美元可以买多少Token
常见的Token计算方式:gpt2、p50k_base、p50k_edit、r50k_base、cl100k_base
大模型幻觉问题解决思路:
为了应对这些潜在问题和风险,LLMs可以采用包括以下方案在内的多种策略来最大限度地解决幻觉现象。
(1)首先是预处理和输入控制,包括限制回复长度和受控输入。
限制回复长度可以避免生成不相关或冗长的内容,确保生成的文本保持一致。
受控输入可以给用户提供特定的样式选项或结构化提示,缩小输出范围并降低幻觉的可能性。
(2)其次是模型配置,由于 LLMs生成的输出受各种模型参数的影响很大,包括温度 (Temperature)、频率损失、存在损失和top-p。
高温度促进随机性和创造性,低温度则增加确定性。
增加频率惩罚值会鼓励模型更加谨慎地使用重复标记。
存在惩罚值则增加生成未包含在文本中的令牌可能性。
top-p 控制单词选择的累积概率阈值,以平衡生成不同响应和确保准确性。
这些参数提供微调灵活性,平衡不同的响应和准确性。
(3)最后是学习与改进,包括建立反馈、监控和改进机制和领域适应及增强。
具体来说可以参与主动学习过程,根据用户反馈和交互进行提示优化和数据集调整;
引入对抗性样本或对抗性训练技术,通过对抗性测试可以识别幻觉的漏洞和潜在来源;
建立人工审核机制,对系统生成的结果进行定期审核和评估;
使用特定领域的信息扩充知识库,允许模型回答查询并生成相关响应。
大厂LLM云服务现状:
短短一周内,全球云巨头纷纷“抢滩登陆”,上线DeepSeek大模型。
2月4日,华为云宣布,经过硅基流动和华为云团队连日攻坚,双方联合首发并上线基于华为云昇腾云服务的DeepSeekR1/V3推理服务。
近日,腾讯云TI平台也宣布上架DeepSeek系列模型,包括“满血”的V3、R1原版模型,参数量达到671B;以及基于DeepSeek-R1蒸馏得到的系列模型,参数规模从70B到1.5B不等。
字节跳动旗下火山引擎也宣布,将支持 V3、R1 等不同尺寸的 DeepSeek 开源模型,可以通过在火山引擎机器学习平台 veMLP 中部署和在火山方舟中调用模型两种方式使用模型。
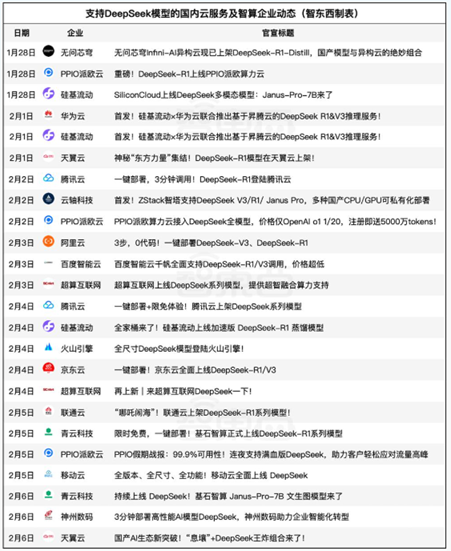
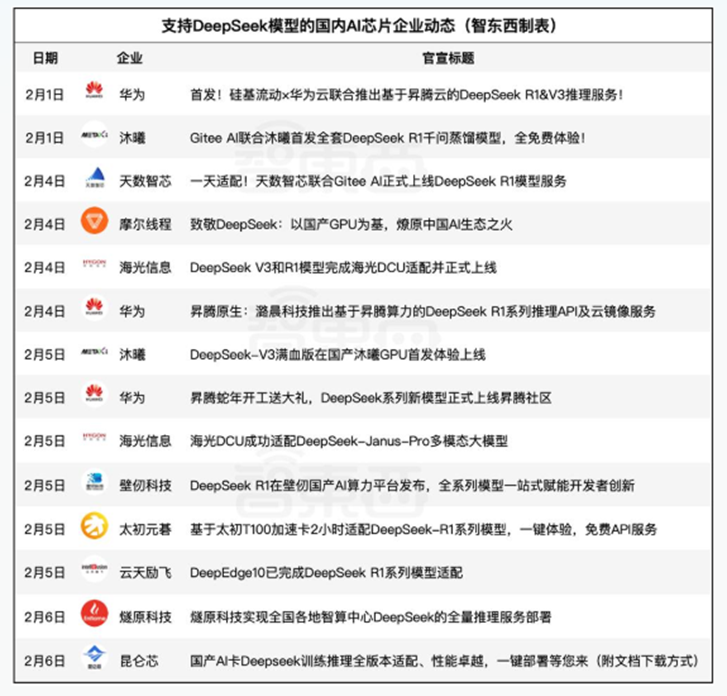
国产显卡支持LLM现状:
短短六天内,10家国产AI芯片企业(华为昇腾、沐曦、天数智芯、摩尔线程、海光信息、壁仞科技、太初元碁、云天励飞、燧原科技、昆仑芯)相继宣布适配或上架DeepSeek模型服务。
可以做的事情:
- 模型参数高效微调(Parameter-Effcient Fine-Tuning, PEFT)、LoRA等、小模型蒸馏distlation
- 模型编辑,减少模型偏见、毒瘤、知识错误等,进行风控。
- 检索增强生成(Retrieval-Augmented Generation, RAG)
- 视觉-语言模型(VLMs)(Mllama、Qwen2-VL、DeepSeek-VL2)
- 智能体Agent(面向不同厅局、单位的专业模型)
- 信创下的LLM(政务云、超算)
- 一键部署的云服务(政务云、超算)
- AIOps 平台
- DevOps 和 AIOps 的融合
- 面向OA网站的文稿校对编写(错别字、语义歧义、)
- 面向OA网站的自动创建公告通知、应用表单,智能检索文件柜中的内容等(类似通达OA)
总结:深度探索,智领未来,自主信创、云端赋能
写在最后:
灵蛇抱玉绕山川,万象更新映乾坤!
愿2025年的同途者:若履幽壑,便作青蛇幻绕,潜移默化;若穿天际,便如金鳞翻飞,直冲云霄。
纵使人世路如蛇纹九曲,千回百转,眉心蓄势待发,胸中烈焰不息。
祝大家新的一年:风霜淬炼骨,星光点亮魂,所行之路若蛇攀天际——披荆为舟,踏浪斩涛!
参考链接·:
https://juejin.cn/post/7455138070298017811
TI-ONE 训练平台 快速部署和体验 DeepSeek 系列模型-实践教程-文档中心-腾讯云
开始使用 LobeChat · LobeChat Docs · LobeHub
https://github.com/InternLM/lmdeploy
https://zhuanlan.zhihu.com/p/697706325
https://zhuanlan.zhihu.com/p/22972365914


















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









