







 该博客详细解析了一种立体匹配网络的实现,包括特征提取模块、视差预测模块和整体网络结构。特征提取部分采用卷积层进行多尺度特征学习,得到不同层次的特征;视差预测模块则通过HourGlass结构预测成本系数,进而计算视差。网络在处理输入图像时,先进行下采样并提取特征,然后构建分组相关成本量,再通过上采样和融合来细化预测。整个模型参数量约为5.31M,主要集中在视差预测模块。
该博客详细解析了一种立体匹配网络的实现,包括特征提取模块、视差预测模块和整体网络结构。特征提取部分采用卷积层进行多尺度特征学习,得到不同层次的特征;视差预测模块则通过HourGlass结构预测成本系数,进而计算视差。网络在处理输入图像时,先进行下采样并提取特征,然后构建分组相关成本量,再通过上采样和融合来细化预测。整个模型参数量约为5.31M,主要集中在视差预测模块。
理论准备
Bilateral Grid Learning for Stereo Matching Networks论文内容解读请参看“论文阅读笔记:Bilateral Grid Learning for Stereo Matching Networks”
特征提取模块
class feature_extraction(nn.Module):
def __init__(self):
super(feature_extraction, self).__init__()
self.inplanes = 32
# self.firstconv = convbn_relu(1, 32, 7, 2, 3, 1)
self.firstconv = nn.Sequential(convbn_relu(1, 32, 3, 2, 1, 1), #1/2
convbn_relu(32, 32, 3, 1, 1, 1),
convbn_relu(32, 32, 3, 1, 1, 1))
self.layer1 = self._make_layer(BasicBlock, 32, 1, 1, 1, 1)
self.layer2 = self._make_layer(BasicBlock, 64, 1, 2, 1, 1) #1/4
self.layer3 = self._make_layer(BasicBlock, 128, 1, 2, 1, 1) #1/8
self.layer4 = self._make_layer(BasicBlock, 128, 1, 1, 1, 1)
self.reduce = convbn_relu(128, 32, 3, 1, 1, 1)
self.conv1a = BasicConv(32, 48, kernel_size=3, stride=2, padding=1)
self.conv2a = BasicConv(48, 64, kernel_size=3, stride=2, padding=1)
self.conv3a = BasicConv(64, 96, kernel_size=3, stride=2, padding=1)
# self.conv4a = BasicConv(96, 128, kernel_size=3, stride=2, padding=1)
# self.deconv4a = Conv2x(128, 96, deconv=True)
self.deconv3a = Conv2x(96, 64, deconv=True)
self.deconv2a = Conv2x(64, 48, deconv=True)
self.deconv1a = Conv2x(48, 32, deconv=True)
self.conv1b = Conv2x(32, 48)
self.conv2b = Conv2x(48, 64)
self.conv3b = Conv2x(64, 96)
# self.conv4b = Conv2x(96, 128)
# self.deconv4b = Conv2x(128, 96, deconv=True)
self.deconv3b = Conv2x(96, 64, deconv=True)
self.deconv2b = Conv2x(64, 48, deconv=True)
self.deconv1b = Conv2x(48, 32, deconv=True)
def _make_layer(self, block, planes, blocks, stride, pad, dilation):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, pad, dilation))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, 1, None, pad, dilation))
return nn.Sequential(*layers)
def forward(self, x):
#1/2
x = self.firstconv(x)
x = self.layer1(x)
conv0a = x
x = self.layer2(x) #1/4
conv1a = x
x = self.layer3(x) #1/8 * 128
feat0 = x
x = self.layer4(x) #1/8 * 128
feat1 = x
x = self.reduce(x) #1/8 * 32
feat2 = x
rem0 = x
#1/2 * 1/2 * 48
x = self.conv1a(x)
rem1 = x
#1/4 * 1/4 * 64
x = self.conv2a(x)
rem2 = x
#1/8 * 1/8 * 96
x = self.conv3a(x)
rem3 = x
#1/16 * 1/16 * 128
# x = self.conv4a(x)
# rem4 = x
# x = self.deconv4a(x, rem3)
# rem3 = x
x = self.deconv3a(x, rem2)
rem2 = x
x = self.deconv2a(x, rem1)
rem1 = x
x = self.deconv1a(x, rem0)
feat3 = x
rem0 = x
#1/2
x = self.conv1b(x, rem1)
rem1 = x
x = self.conv2b(x, rem2)
rem2 = x
x = self.conv3b(x, rem3)
rem3 = x
#1/16
# x = self.conv4b(x, rem4)
# x = self.deconv4b(x, rem3)
x = self.deconv3b(x, rem2)
x = self.deconv2b(x, rem1)
x = self.deconv1b(x, rem0)
feat4 = x
gwc_feature = torch.cat((feat0,feat1,feat2,feat3,feat4),dim = 1)
return conv0a,gwc_feature
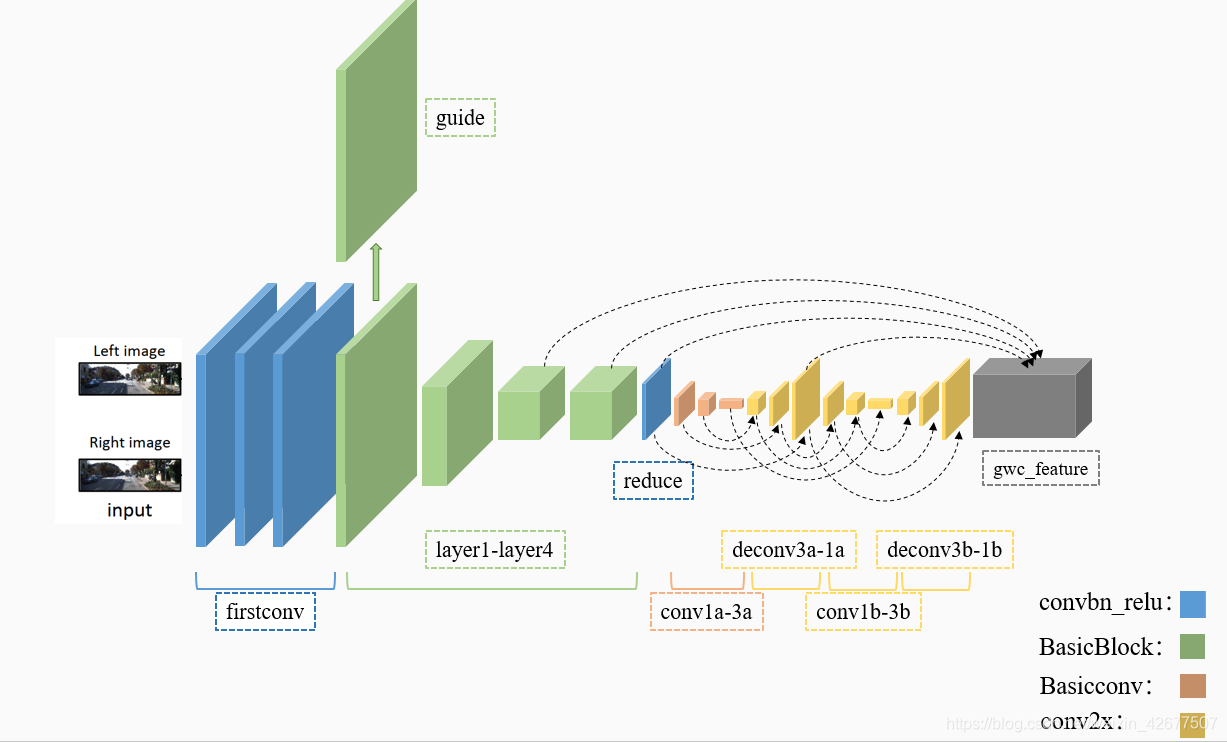
卷积过程示意图如下图所示:
| 输入 | 输出形状 |
|---|---|
| input | torch.Size([1, 1, 384, 1280]) |
| firstconv | torch.Size([1, 32, 192, 640]) |
| layer1 | torch.Size([1, 32, 192, 640]) |
| layer2 | torch.Size([1, 64, 96, 320]) |
| layer3 | torch.Size([1, 128, 48, 160]) |
| layer4 | torch.Size([1, 128, 48, 160]) |
| reduce | torch.Size([1, 32, 48, 160]) |
| conv1a | torch.Size([1, 48, 24, 80]) |
| conv2a | torch.Size([1, 64, 12, 40]) |
| conv3a | torch.Size([1, 96, 6, 20]) |
| deconv3a | torch.Size([1, 64, 12, 40]) |
| deconv2a | torch.Size([1, 48, 24, 80]) |
| deconv1a | torch.Size([1, 32, 48, 160]) |
| conv1b | torch.Size([1, 48, 24, 80]) |
| conv2b | torch.Size([1, 64, 12, 40]) |
| conv3b | torch.Size([1, 96, 6, 20]) |
| deconv3b | torch.Size([1, 64, 12, 40]) |
| deconv2b | torch.Size([1, 48, 24, 80]) |
| deconv1b | torch.Size([1, 32, 48, 160]) |
| gwc_feature | torch.Size([1, 352, 48, 160]) |
视差预测模块
class CoeffsPredictor(HourGlass):
def __init__(self, hourglass_inplanes=16):
super(CoeffsPredictor, self).__init__(hourglass_inplanes)
def forward(self, input):
output0 = self.conv1(input)
output0_a = self.conv2(output0) + output0
output0 = self.conv1_1(output0_a)
output0_c = self.conv2_1(output0) + output0
output0 = self.conv3(output0_c)
output0 = self.conv4(output0) + output0
output1 = self.conv5(output0) + output0_c
output1 = self.conv6(output1) + output0_a
output1 = self.conv7(output1)
#[B,G,D,H,W] -> [B,D,G,H,W]
coeffs = self.last_for_guidance(output1).permute(0,2,1,3,4).contiguous()
return coeffs
网络结构
class BGNet(SubModule):
def __init__(self):
super(BGNet, self).__init__()
self.softmax = nn.Softmax(dim = 1)
# self.refinement_net = HourglassRefinement()
self.feature_extraction = feature_extraction()
self.coeffs_disparity_predictor = CoeffsPredictor()
self.dres0 = nn.Sequential(convbn_3d_lrelu(44, 32, 3, 1, 1),
convbn_3d_lrelu(32, 16, 3, 1, 1))
self.guide = GuideNN()
self.slice = Slice()
self.weight_init()
def forward(self, left_input, right_input):
left_low_level_features_1, left_gwc_feature = self.feature_extraction(left_input)
_, right_gwc_feature = self.feature_extraction(right_input)
guide = self.guide(left_low_level_features_1) #[B,1,H,W]
# torch.cuda.synchronize()
# start = time.time()
cost_volume = build_gwc_volume(left_gwc_feature,right_gwc_feature,25,44)
cost_volume = self.dres0(cost_volume)
#coeffs:[B,D,G,H,W]
coeffs = self.coeffs_disparity_predictor(cost_volume)
list_coeffs = torch.split(coeffs,1,dim = 1)
index = torch.arange(0,97)
index_float = index/4.0
index_a = torch.floor(index_float)
index_b = index_a + 1
index_a = torch.clamp(index_a, min=0, max= 24)
index_b = torch.clamp(index_b, min=0, max= 24)
wa = index_b - index_float
wb = index_float - index_a
list_float = []
device = list_coeffs[0].get_device()
wa = wa.view(1,-1,1,1)
wb = wb.view(1,-1,1,1)
wa = wa.to(device)
wb = wb.to(device)
wa = wa.float()
wb = wb.float()
N, _, H, W = guide.shape
#[H,W]
hg, wg = torch.meshgrid([torch.arange(0, H), torch.arange(0, W)]) # [0,511] HxW
if device >= 0:
hg = hg.to(device)
wg = wg.to(device)
#[B,H,W,1]
hg = hg.float().repeat(N, 1, 1).unsqueeze(3) / (H-1) * 2 - 1 # norm to [-1,1] NxHxWx1
wg = wg.float().repeat(N, 1, 1).unsqueeze(3) / (W-1) * 2 - 1 # norm to [-1,1] NxHxWx1
slice_dict = []
# torch.cuda.synchronize()
# start = time.time()
for i in range(25):
slice_dict.append(self.slice(list_coeffs[i], wg, hg, guide)) #[B,1,H,W]
slice_dict_a = []
slice_dict_b = []
for i in range(97):
inx_a = i//4
inx_b = inx_a + 1
inx_b = min(inx_b,24)
slice_dict_a.append(slice_dict[inx_a])
slice_dict_b.append(slice_dict[inx_b])
final_cost_volume = wa * torch.cat(slice_dict_a,dim = 1) + wb * torch.cat(slice_dict_b,dim = 1)
slice = self.softmax(final_cost_volume)
disparity_samples = torch.arange(0, 97, dtype=slice.dtype, device=slice.device).view(1, 97, 1, 1)
disparity_samples = disparity_samples.repeat(slice.size()[0],1,slice.size()[2],slice.size()[3])
half_disp = torch.sum(disparity_samples * slice,dim = 1).unsqueeze(1)
out2 = F.interpolate(half_disp * 2.0, scale_factor=(2.0, 2.0),
mode='bilinear',align_corners =False).squeeze(1)
return out2,out2
feature_extraction()返回conv0a,gwc_feature两个值,其中conv0a是仅经过firstconv和layer1的结果,gwc_feature是经过整个feature_extraction()的结果。
left_low_level_features_1会接着进入到GuideNN()里变成guide ,guide 就是论文里提到的Guidance Map,形状为[B,1,H,W]。
cost_volume的构建分两步,build_gwc_volume和dres0,build_gwc_volume就是论文里提到的为成本聚合构建了一个分组相关成本量,通过将特征通道划分为 Ng 组,为视差d 的每个像素位置 (x,y) 计算分组相关,这边具体的操作很细节,需要单独细讲。
coeffs_disparity_predictor是继承的HourGlass,有点像PSMNET里面的3D卷积结构。
BGNet_plus网络具体结构与每层权重大小
| 层名 | 权重大小 |
|---|---|
| refinement_net.conv1.0.weight | torch.Size([16, 2, 3, 3]) |
| refinement_net.conv1.1.weight | torch.Size([16]) |
| refinement_net.conv1.1.bias | torch.Size([16]) |
| refinement_net.conv1.1.running_mean | torch.Size([16]) |
| refinement_net.conv1.1.running_var | torch.Size([16]) |
| refinement_net.conv1.1.num_batches_tracked | torch.Size([]) |
| refinement_net.conv2.0.weight | torch.Size([16, 1, 3, 3]) |
| refinement_net.conv2.1.weight | torch.Size([16]) |
| refinement_net.conv2.1.bias | torch.Size([16]) |
| refinement_net.conv2.1.running_mean | torch.Size([16]) |
| refinement_net.conv2.1.running_var | torch.Size([16]) |
| refinement_net.conv2.1.num_batches_tracked | torch.Size([]) |
| refinement_net.conv_start.0.weight | torch.Size([32, 32, 3, 3]) |
| refinement_net.conv_start.1.weight | torch.Size([32]) |
| refinement_net.conv_start.1.bias | torch.Size([32]) |
| refinement_net.conv_start.1.running_mean | torch.Size([32]) |
| refinement_net.conv_start.1.running_var | torch.Size([32]) |
| refinement_net.conv_start.1.num_batches_tracked | torch.Size([]) |
| refinement_net.conv1a.conv.weight | torch.Size([48, 32, 3, 3]) |
| refinement_net.conv1a.bn.weight | torch.Size([48]) |
| refinement_net.conv1a.bn.bias | torch.Size([48]) |
| refinement_net.conv1a.bn.running_mean | torch.Size([48]) |
| refinement_net.conv1a.bn.running_var | torch.Size([48]) |
| refinement_net.conv1a.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv2a.conv.weight | torch.Size([64, 48, 3, 3]) |
| refinement_net.conv2a.bn.weight | torch.Size([64]) |
| refinement_net.conv2a.bn.bias | torch.Size([64]) |
| refinement_net.conv2a.bn.running_mean | torch.Size([64]) |
| refinement_net.conv2a.bn.running_var | torch.Size([64]) |
| refinement_net.conv2a.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv3a.conv.weight | torch.Size([96, 64, 3, 3]) |
| refinement_net.conv3a.bn.weight | torch.Size([96]) |
| refinement_net.conv3a.bn.bias | torch.Size([96]) |
| refinement_net.conv3a.bn.running_mean | torch.Size([96]) |
| refinement_net.conv3a.bn.running_var | torch.Size([96]) |
| refinement_net.conv3a.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv4a.conv.weight | torch.Size([128, 96, 3, 3]) |
| refinement_net.conv4a.bn.weight | torch.Size([128]) |
| refinement_net.conv4a.bn.bias | torch.Size([128]) |
| refinement_net.conv4a.bn.running_mean | torch.Size([128]) |
| refinement_net.conv4a.bn.running_var | torch.Size([128]) |
| refinement_net.conv4a.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv4a.conv1.conv.weight | torch.Size([128, 96, 4, 4]) |
| refinement_net.deconv4a.conv1.bn.weight | torch.Size([96]) |
| refinement_net.deconv4a.conv1.bn.bias | torch.Size([96]) |
| refinement_net.deconv4a.conv1.bn.running_mean | torch.Size([96]) |
| refinement_net.deconv4a.conv1.bn.running_var | torch.Size([96]) |
| refinement_net.deconv4a.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv4a.conv2.conv.weight | torch.Size([96, 192, 3, 3]) |
| refinement_net.deconv4a.conv2.bn.weight | torch.Size([96]) |
| refinement_net.deconv4a.conv2.bn.bias | torch.Size([96]) |
| refinement_net.deconv4a.conv2.bn.running_mean | torch.Size([96]) |
| refinement_net.deconv4a.conv2.bn.running_var | torch.Size([96]) |
| refinement_net.deconv4a.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv3a.conv1.conv.weight | torch.Size([96, 64, 4, 4]) |
| refinement_net.deconv3a.conv1.bn.weight | torch.Size([64]) |
| refinement_net.deconv3a.conv1.bn.bias | torch.Size([64]) |
| refinement_net.deconv3a.conv1.bn.running_mean | torch.Size([64]) |
| refinement_net.deconv3a.conv1.bn.running_var | torch.Size([64]) |
| refinement_net.deconv3a.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv3a.conv2.conv.weight | torch.Size([64, 128, 3, 3]) |
| refinement_net.deconv3a.conv2.bn.weight | torch.Size([64]) |
| refinement_net.deconv3a.conv2.bn.bias | torch.Size([64]) |
| refinement_net.deconv3a.conv2.bn.running_mean | torch.Size([64]) |
| refinement_net.deconv3a.conv2.bn.running_var | torch.Size([64]) |
| refinement_net.deconv3a.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv2a.conv1.conv.weight | torch.Size([64, 48, 4, 4]) |
| refinement_net.deconv2a.conv1.bn.weight | torch.Size([48]) |
| refinement_net.deconv2a.conv1.bn.bias | torch.Size([48]) |
| refinement_net.deconv2a.conv1.bn.running_mean | torch.Size([48]) |
| refinement_net.deconv2a.conv1.bn.running_var | torch.Size([48]) |
| refinement_net.deconv2a.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv2a.conv2.conv.weight | torch.Size([48, 96, 3, 3]) |
| refinement_net.deconv2a.conv2.bn.weight | torch.Size([48]) |
| refinement_net.deconv2a.conv2.bn.bias | torch.Size([48]) |
| refinement_net.deconv2a.conv2.bn.running_mean | torch.Size([48]) |
| refinement_net.deconv2a.conv2.bn.running_var | torch.Size([48]) |
| refinement_net.deconv2a.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv1a.conv1.conv.weight | torch.Size([48, 32, 4, 4]) |
| refinement_net.deconv1a.conv1.bn.weight | torch.Size([32]) |
| refinement_net.deconv1a.conv1.bn.bias | torch.Size([32]) |
| refinement_net.deconv1a.conv1.bn.running_mean | torch.Size([32]) |
| refinement_net.deconv1a.conv1.bn.running_var | torch.Size([32]) |
| refinement_net.deconv1a.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv1a.conv2.conv.weight | torch.Size([32, 64, 3, 3]) |
| refinement_net.deconv1a.conv2.bn.weight | torch.Size([32]) |
| refinement_net.deconv1a.conv2.bn.bias | torch.Size([32]) |
| refinement_net.deconv1a.conv2.bn.running_mean | torch.Size([32]) |
| refinement_net.deconv1a.conv2.bn.running_var | torch.Size([32]) |
| refinement_net.deconv1a.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv1b.conv1.conv.weight | torch.Size([48, 32, 3, 3]) |
| refinement_net.conv1b.conv1.bn.weight | torch.Size([48]) |
| refinement_net.conv1b.conv1.bn.bias | torch.Size([48]) |
| refinement_net.conv1b.conv1.bn.running_mean | torch.Size([48]) |
| refinement_net.conv1b.conv1.bn.running_var | torch.Size([48]) |
| refinement_net.conv1b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv1b.conv2.conv.weight | torch.Size([48, 96, 3, 3]) |
| refinement_net.conv1b.conv2.bn.weight | torch.Size([48]) |
| refinement_net.conv1b.conv2.bn.bias | torch.Size([48]) |
| refinement_net.conv1b.conv2.bn.running_mean | torch.Size([48]) |
| refinement_net.conv1b.conv2.bn.running_var | torch.Size([48]) |
| refinement_net.conv1b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv2b.conv1.conv.weight | torch.Size([64, 48, 3, 3]) |
| refinement_net.conv2b.conv1.bn.weight | torch.Size([64]) |
| refinement_net.conv2b.conv1.bn.bias | torch.Size([64]) |
| refinement_net.conv2b.conv1.bn.running_mean | torch.Size([64]) |
| refinement_net.conv2b.conv1.bn.running_var | torch.Size([64]) |
| refinement_net.conv2b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv2b.conv2.conv.weight | torch.Size([64, 128, 3, 3]) |
| refinement_net.conv2b.conv2.bn.weight | torch.Size([64]) |
| refinement_net.conv2b.conv2.bn.bias | torch.Size([64]) |
| refinement_net.conv2b.conv2.bn.running_mean | torch.Size([64]) |
| refinement_net.conv2b.conv2.bn.running_var | torch.Size([64]) |
| refinement_net.conv2b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv3b.conv1.conv.weight | torch.Size([96, 64, 3, 3]) |
| refinement_net.conv3b.conv1.bn.weight | torch.Size([96]) |
| refinement_net.conv3b.conv1.bn.bias | torch.Size([96]) |
| refinement_net.conv3b.conv1.bn.running_mean | torch.Size([96]) |
| refinement_net.conv3b.conv1.bn.running_var | torch.Size([96]) |
| refinement_net.conv3b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv3b.conv2.conv.weight | torch.Size([96, 192, 3, 3]) |
| refinement_net.conv3b.conv2.bn.weight | torch.Size([96]) |
| refinement_net.conv3b.conv2.bn.bias | torch.Size([96]) |
| refinement_net.conv3b.conv2.bn.running_mean | torch.Size([96]) |
| refinement_net.conv3b.conv2.bn.running_var | torch.Size([96]) |
| refinement_net.conv3b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv4b.conv1.conv.weight | torch.Size([128, 96, 3, 3]) |
| refinement_net.conv4b.conv1.bn.weight | torch.Size([128]) |
| refinement_net.conv4b.conv1.bn.bias | torch.Size([128]) |
| refinement_net.conv4b.conv1.bn.running_mean | torch.Size([128]) |
| refinement_net.conv4b.conv1.bn.running_var | torch.Size([128]) |
| refinement_net.conv4b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.conv4b.conv2.conv.weight | torch.Size([128, 256, 3, 3]) |
| refinement_net.conv4b.conv2.bn.weight | torch.Size([128]) |
| refinement_net.conv4b.conv2.bn.bias | torch.Size([128]) |
| refinement_net.conv4b.conv2.bn.running_mean | torch.Size([128]) |
| refinement_net.conv4b.conv2.bn.running_var | torch.Size([128]) |
| refinement_net.conv4b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv4b.conv1.conv.weight | torch.Size([128, 96, 4, 4]) |
| refinement_net.deconv4b.conv1.bn.weight | torch.Size([96]) |
| refinement_net.deconv4b.conv1.bn.bias | torch.Size([96]) |
| refinement_net.deconv4b.conv1.bn.running_mean | torch.Size([96]) |
| refinement_net.deconv4b.conv1.bn.running_var | torch.Size([96]) |
| refinement_net.deconv4b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv4b.conv2.conv.weight | torch.Size([96, 192, 3, 3]) |
| refinement_net.deconv4b.conv2.bn.weight | torch.Size([96]) |
| refinement_net.deconv4b.conv2.bn.bias | torch.Size([96]) |
| refinement_net.deconv4b.conv2.bn.running_mean | torch.Size([96]) |
| refinement_net.deconv4b.conv2.bn.running_var | torch.Size([96]) |
| refinement_net.deconv4b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv3b.conv1.conv.weight | torch.Size([96, 64, 4, 4]) |
| refinement_net.deconv3b.conv1.bn.weight | torch.Size([64]) |
| refinement_net.deconv3b.conv1.bn.bias | torch.Size([64]) |
| refinement_net.deconv3b.conv1.bn.running_mean | torch.Size([64]) |
| refinement_net.deconv3b.conv1.bn.running_var | torch.Size([64]) |
| refinement_net.deconv3b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv3b.conv2.conv.weight | torch.Size([64, 128, 3, 3]) |
| refinement_net.deconv3b.conv2.bn.weight | torch.Size([64]) |
| refinement_net.deconv3b.conv2.bn.bias | torch.Size([64]) |
| refinement_net.deconv3b.conv2.bn.running_mean | torch.Size([64]) |
| refinement_net.deconv3b.conv2.bn.running_var | torch.Size([64]) |
| refinement_net.deconv3b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv2b.conv1.conv.weight | torch.Size([64, 48, 4, 4]) |
| refinement_net.deconv2b.conv1.bn.weight | torch.Size([48]) |
| refinement_net.deconv2b.conv1.bn.bias | torch.Size([48]) |
| refinement_net.deconv2b.conv1.bn.running_mean | torch.Size([48]) |
| refinement_net.deconv2b.conv1.bn.running_var | torch.Size([48]) |
| refinement_net.deconv2b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv2b.conv2.conv.weight | torch.Size([48, 96, 3, 3]) |
| refinement_net.deconv2b.conv2.bn.weight | torch.Size([48]) |
| refinement_net.deconv2b.conv2.bn.bias | torch.Size([48]) |
| refinement_net.deconv2b.conv2.bn.running_mean | torch.Size([48]) |
| refinement_net.deconv2b.conv2.bn.running_var | torch.Size([48]) |
| refinement_net.deconv2b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv1b.conv1.conv.weight | torch.Size([48, 32, 4, 4]) |
| refinement_net.deconv1b.conv1.bn.weight | torch.Size([32]) |
| refinement_net.deconv1b.conv1.bn.bias | torch.Size([32]) |
| refinement_net.deconv1b.conv1.bn.running_mean | torch.Size([32]) |
| refinement_net.deconv1b.conv1.bn.running_var | torch.Size([32]) |
| refinement_net.deconv1b.conv1.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.deconv1b.conv2.conv.weight | torch.Size([32, 64, 3, 3]) |
| refinement_net.deconv1b.conv2.bn.weight | torch.Size([32]) |
| refinement_net.deconv1b.conv2.bn.bias | torch.Size([32]) |
| refinement_net.deconv1b.conv2.bn.running_mean | torch.Size([32]) |
| refinement_net.deconv1b.conv2.bn.running_var | torch.Size([32]) |
| refinement_net.deconv1b.conv2.bn.num_batches_tracked | torch.Size([]) |
| refinement_net.final_conv.weight | torch.Size([1, 32, 3, 3]) |
| refinement_net.final_conv.bias | torch.Size([1]) |
| feature_extraction.firstconv.0.0.weight | torch.Size([32, 1, 3, 3]) |
| feature_extraction.firstconv.0.1.weight | torch.Size([32]) |
| feature_extraction.firstconv.0.1.bias | torch.Size([32]) |
| feature_extraction.firstconv.0.1.running_mean | torch.Size([32]) |
| feature_extraction.firstconv.0.1.running_var | torch.Size([32]) |
| feature_extraction.firstconv.0.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.firstconv.1.0.weight | torch.Size([32, 32, 3, 3]) |
| feature_extraction.firstconv.1.1.weight | torch.Size([32]) |
| feature_extraction.firstconv.1.1.bias | torch.Size([32]) |
| feature_extraction.firstconv.1.1.running_mean | torch.Size([32]) |
| feature_extraction.firstconv.1.1.running_var | torch.Size([32]) |
| feature_extraction.firstconv.1.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.firstconv.2.0.weight | torch.Size([32, 32, 3, 3]) |
| feature_extraction.firstconv.2.1.weight | torch.Size([32]) |
| feature_extraction.firstconv.2.1.bias | torch.Size([32]) |
| feature_extraction.firstconv.2.1.running_mean | torch.Size([32]) |
| feature_extraction.firstconv.2.1.running_var | torch.Size([32]) |
| feature_extraction.firstconv.2.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer1.0.conv1.0.weight | torch.Size([32, 32, 3, 3]) |
| feature_extraction.layer1.0.conv1.1.weight | torch.Size([32]) |
| feature_extraction.layer1.0.conv1.1.bias | torch.Size([32]) |
| feature_extraction.layer1.0.conv1.1.running_mean | torch.Size([32]) |
| feature_extraction.layer1.0.conv1.1.running_var | torch.Size([32]) |
| feature_extraction.layer1.0.conv1.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer1.0.conv2.0.weight | torch.Size([32, 32, 3, 3]) |
| feature_extraction.layer1.0.conv2.1.weight | torch.Size([32]) |
| feature_extraction.layer1.0.conv2.1.bias | torch.Size([32]) |
| feature_extraction.layer1.0.conv2.1.running_mean | torch.Size([32]) |
| feature_extraction.layer1.0.conv2.1.running_var | torch.Size([32]) |
| feature_extraction.layer1.0.conv2.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer2.0.conv1.0.weight | torch.Size([64, 32, 3, 3]) |
| feature_extraction.layer2.0.conv1.1.weight | torch.Size([64]) |
| feature_extraction.layer2.0.conv1.1.bias | torch.Size([64]) |
| feature_extraction.layer2.0.conv1.1.running_mean | torch.Size([64]) |
| feature_extraction.layer2.0.conv1.1.running_var | torch.Size([64]) |
| feature_extraction.layer2.0.conv1.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer2.0.conv2.0.weight | torch.Size([64, 64, 3, 3]) |
| feature_extraction.layer2.0.conv2.1.weight | torch.Size([64]) |
| feature_extraction.layer2.0.conv2.1.bias | torch.Size([64]) |
| feature_extraction.layer2.0.conv2.1.running_mean | torch.Size([64]) |
| feature_extraction.layer2.0.conv2.1.running_var | torch.Size([64]) |
| feature_extraction.layer2.0.conv2.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer2.0.downsample.0.weight | torch.Size([64, 32, 1, 1]) |
| feature_extraction.layer2.0.downsample.1.weight | torch.Size([64]) |
| feature_extraction.layer2.0.downsample.1.bias | torch.Size([64]) |
| feature_extraction.layer2.0.downsample.1.running_mean | torch.Size([64]) |
| feature_extraction.layer2.0.downsample.1.running_var | torch.Size([64]) |
| feature_extraction.layer2.0.downsample.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer3.0.conv1.0.weight | torch.Size([128, 64, 3, 3]) |
| feature_extraction.layer3.0.conv1.1.weight | torch.Size([128]) |
| feature_extraction.layer3.0.conv1.1.bias | torch.Size([128]) |
| feature_extraction.layer3.0.conv1.1.running_mean | torch.Size([128]) |
| feature_extraction.layer3.0.conv1.1.running_var | torch.Size([128]) |
| feature_extraction.layer3.0.conv1.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer3.0.conv2.0.weight | torch.Size([128, 128, 3, 3]) |
| feature_extraction.layer3.0.conv2.1.weight | torch.Size([128]) |
| feature_extraction.layer3.0.conv2.1.bias | torch.Size([128]) |
| feature_extraction.layer3.0.conv2.1.running_mean | torch.Size([128]) |
| feature_extraction.layer3.0.conv2.1.running_var | torch.Size([128]) |
| feature_extraction.layer3.0.conv2.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer3.0.downsample.0.weight | torch.Size([128, 64, 1, 1]) |
| feature_extraction.layer3.0.downsample.1.weight | torch.Size([128]) |
| feature_extraction.layer3.0.downsample.1.bias | torch.Size([128]) |
| feature_extraction.layer3.0.downsample.1.running_mean | torch.Size([128]) |
| feature_extraction.layer3.0.downsample.1.running_var | torch.Size([128]) |
| feature_extraction.layer3.0.downsample.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer4.0.conv1.0.weight | torch.Size([128, 128, 3, 3]) |
| feature_extraction.layer4.0.conv1.1.weight | torch.Size([128]) |
| feature_extraction.layer4.0.conv1.1.bias | torch.Size([128]) |
| feature_extraction.layer4.0.conv1.1.running_mean | torch.Size([128]) |
| feature_extraction.layer4.0.conv1.1.running_var | torch.Size([128]) |
| feature_extraction.layer4.0.conv1.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.layer4.0.conv2.0.weight | torch.Size([128, 128, 3, 3]) |
| feature_extraction.layer4.0.conv2.1.weight | torch.Size([128]) |
| feature_extraction.layer4.0.conv2.1.bias | torch.Size([128]) |
| feature_extraction.layer4.0.conv2.1.running_mean | torch.Size([128]) |
| feature_extraction.layer4.0.conv2.1.running_var | torch.Size([128]) |
| feature_extraction.layer4.0.conv2.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.reduce.0.weight | torch.Size([32, 128, 3, 3]) |
| feature_extraction.reduce.1.weight | torch.Size([32]) |
| feature_extraction.reduce.1.bias | torch.Size([32]) |
| feature_extraction.reduce.1.running_mean | torch.Size([32]) |
| feature_extraction.reduce.1.running_var | torch.Size([32]) |
| feature_extraction.reduce.1.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv1a.conv.weight | torch.Size([48, 32, 3, 3]) |
| feature_extraction.conv1a.bn.weight | torch.Size([48]) |
| feature_extraction.conv1a.bn.bias | torch.Size([48]) |
| feature_extraction.conv1a.bn.running_mean | torch.Size([48]) |
| feature_extraction.conv1a.bn.running_var | torch.Size([48]) |
| feature_extraction.conv1a.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv2a.conv.weight | torch.Size([64, 48, 3, 3]) |
| feature_extraction.conv2a.bn.weight | torch.Size([64]) |
| feature_extraction.conv2a.bn.bias | torch.Size([64]) |
| feature_extraction.conv2a.bn.running_mean | torch.Size([64]) |
| feature_extraction.conv2a.bn.running_var | torch.Size([64]) |
| feature_extraction.conv2a.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv3a.conv.weight | torch.Size([96, 64, 3, 3]) |
| feature_extraction.conv3a.bn.weight | torch.Size([96]) |
| feature_extraction.conv3a.bn.bias | torch.Size([96]) |
| feature_extraction.conv3a.bn.running_mean | torch.Size([96]) |
| feature_extraction.conv3a.bn.running_var | torch.Size([96]) |
| feature_extraction.conv3a.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv3a.conv1.conv.weight | torch.Size([96, 64, 4, 4]) |
| feature_extraction.deconv3a.conv1.bn.weight | torch.Size([64]) |
| feature_extraction.deconv3a.conv1.bn.bias | torch.Size([64]) |
| feature_extraction.deconv3a.conv1.bn.running_mean | torch.Size([64]) |
| feature_extraction.deconv3a.conv1.bn.running_var | torch.Size([64]) |
| feature_extraction.deconv3a.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv3a.conv2.conv.weight | torch.Size([64, 128, 3, 3]) |
| feature_extraction.deconv3a.conv2.bn.weight | torch.Size([64]) |
| feature_extraction.deconv3a.conv2.bn.bias | torch.Size([64]) |
| feature_extraction.deconv3a.conv2.bn.running_mean | torch.Size([64]) |
| feature_extraction.deconv3a.conv2.bn.running_var | torch.Size([64]) |
| feature_extraction.deconv3a.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv2a.conv1.conv.weight | torch.Size([64, 48, 4, 4]) |
| feature_extraction.deconv2a.conv1.bn.weight | torch.Size([48]) |
| feature_extraction.deconv2a.conv1.bn.bias | torch.Size([48]) |
| feature_extraction.deconv2a.conv1.bn.running_mean | torch.Size([48]) |
| feature_extraction.deconv2a.conv1.bn.running_var | torch.Size([48]) |
| feature_extraction.deconv2a.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv2a.conv2.conv.weight | torch.Size([48, 96, 3, 3]) |
| feature_extraction.deconv2a.conv2.bn.weight | torch.Size([48]) |
| feature_extraction.deconv2a.conv2.bn.bias | torch.Size([48]) |
| feature_extraction.deconv2a.conv2.bn.running_mean | torch.Size([48]) |
| feature_extraction.deconv2a.conv2.bn.running_var | torch.Size([48]) |
| feature_extraction.deconv2a.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv1a.conv1.conv.weight | torch.Size([48, 32, 4, 4]) |
| feature_extraction.deconv1a.conv1.bn.weight | torch.Size([32]) |
| feature_extraction.deconv1a.conv1.bn.bias | torch.Size([32]) |
| feature_extraction.deconv1a.conv1.bn.running_mean | torch.Size([32]) |
| feature_extraction.deconv1a.conv1.bn.running_var | torch.Size([32]) |
| feature_extraction.deconv1a.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv1a.conv2.conv.weight | torch.Size([32, 64, 3, 3]) |
| feature_extraction.deconv1a.conv2.bn.weight | torch.Size([32]) |
| feature_extraction.deconv1a.conv2.bn.bias | torch.Size([32]) |
| feature_extraction.deconv1a.conv2.bn.running_mean | torch.Size([32]) |
| feature_extraction.deconv1a.conv2.bn.running_var | torch.Size([32]) |
| feature_extraction.deconv1a.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv1b.conv1.conv.weight | torch.Size([48, 32, 3, 3]) |
| feature_extraction.conv1b.conv1.bn.weight | torch.Size([48]) |
| feature_extraction.conv1b.conv1.bn.bias | torch.Size([48]) |
| feature_extraction.conv1b.conv1.bn.running_mean | torch.Size([48]) |
| feature_extraction.conv1b.conv1.bn.running_var | torch.Size([48]) |
| feature_extraction.conv1b.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv1b.conv2.conv.weight | torch.Size([48, 96, 3, 3]) |
| feature_extraction.conv1b.conv2.bn.weight | torch.Size([48]) |
| feature_extraction.conv1b.conv2.bn.bias | torch.Size([48]) |
| feature_extraction.conv1b.conv2.bn.running_mean | torch.Size([48]) |
| feature_extraction.conv1b.conv2.bn.running_var | torch.Size([48]) |
| feature_extraction.conv1b.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv2b.conv1.conv.weight | torch.Size([64, 48, 3, 3]) |
| feature_extraction.conv2b.conv1.bn.weight | torch.Size([64]) |
| feature_extraction.conv2b.conv1.bn.bias | torch.Size([64]) |
| feature_extraction.conv2b.conv1.bn.running_mean | torch.Size([64]) |
| feature_extraction.conv2b.conv1.bn.running_var | torch.Size([64]) |
| feature_extraction.conv2b.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv2b.conv2.conv.weight | torch.Size([64, 128, 3, 3]) |
| feature_extraction.conv2b.conv2.bn.weight | torch.Size([64]) |
| feature_extraction.conv2b.conv2.bn.bias | torch.Size([64]) |
| feature_extraction.conv2b.conv2.bn.running_mean | torch.Size([64]) |
| feature_extraction.conv2b.conv2.bn.running_var | torch.Size([64]) |
| feature_extraction.conv2b.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv3b.conv1.conv.weight | torch.Size([96, 64, 3, 3]) |
| feature_extraction.conv3b.conv1.bn.weight | torch.Size([96]) |
| feature_extraction.conv3b.conv1.bn.bias | torch.Size([96]) |
| feature_extraction.conv3b.conv1.bn.running_mean | torch.Size([96]) |
| feature_extraction.conv3b.conv1.bn.running_var | torch.Size([96]) |
| feature_extraction.conv3b.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.conv3b.conv2.conv.weight | torch.Size([96, 192, 3, 3]) |
| feature_extraction.conv3b.conv2.bn.weight | torch.Size([96]) |
| feature_extraction.conv3b.conv2.bn.bias | torch.Size([96]) |
| feature_extraction.conv3b.conv2.bn.running_mean | torch.Size([96]) |
| feature_extraction.conv3b.conv2.bn.running_var | torch.Size([96]) |
| feature_extraction.conv3b.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv3b.conv1.conv.weight | torch.Size([96, 64, 4, 4]) |
| feature_extraction.deconv3b.conv1.bn.weight | torch.Size([64]) |
| feature_extraction.deconv3b.conv1.bn.bias | torch.Size([64]) |
| feature_extraction.deconv3b.conv1.bn.running_mean | torch.Size([64]) |
| feature_extraction.deconv3b.conv1.bn.running_var | torch.Size([64]) |
| feature_extraction.deconv3b.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv3b.conv2.conv.weight | torch.Size([64, 128, 3, 3]) |
| feature_extraction.deconv3b.conv2.bn.weight | torch.Size([64]) |
| feature_extraction.deconv3b.conv2.bn.bias | torch.Size([64]) |
| feature_extraction.deconv3b.conv2.bn.running_mean | torch.Size([64]) |
| feature_extraction.deconv3b.conv2.bn.running_var | torch.Size([64]) |
| feature_extraction.deconv3b.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv2b.conv1.conv.weight | torch.Size([64, 48, 4, 4]) |
| feature_extraction.deconv2b.conv1.bn.weight | torch.Size([48]) |
| feature_extraction.deconv2b.conv1.bn.bias | torch.Size([48]) |
| feature_extraction.deconv2b.conv1.bn.running_mean | torch.Size([48]) |
| feature_extraction.deconv2b.conv1.bn.running_var | torch.Size([48]) |
| feature_extraction.deconv2b.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv2b.conv2.conv.weight | torch.Size([48, 96, 3, 3]) |
| feature_extraction.deconv2b.conv2.bn.weight | torch.Size([48]) |
| feature_extraction.deconv2b.conv2.bn.bias | torch.Size([48]) |
| feature_extraction.deconv2b.conv2.bn.running_mean | torch.Size([48]) |
| feature_extraction.deconv2b.conv2.bn.running_var | torch.Size([48]) |
| feature_extraction.deconv2b.conv2.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv1b.conv1.conv.weight | torch.Size([48, 32, 4, 4]) |
| feature_extraction.deconv1b.conv1.bn.weight | torch.Size([32]) |
| feature_extraction.deconv1b.conv1.bn.bias | torch.Size([32]) |
| feature_extraction.deconv1b.conv1.bn.running_mean | torch.Size([32]) |
| feature_extraction.deconv1b.conv1.bn.running_var | torch.Size([32]) |
| feature_extraction.deconv1b.conv1.bn.num_batches_tracked | torch.Size([]) |
| feature_extraction.deconv1b.conv2.conv.weight | torch.Size([32, 64, 3, 3]) |
| feature_extraction.deconv1b.conv2.bn.weight | torch.Size([32]) |
| feature_extraction.deconv1b.conv2.bn.bias | torch.Size([32]) |
| feature_extraction.deconv1b.conv2.bn.running_mean | torch.Size([32]) |
| feature_extraction.deconv1b.conv2.bn.running_var | torch.Size([32]) |
| feature_extraction.deconv1b.conv2.bn.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv1.0.weight | torch.Size([32, 16, 3, 3, 3]) |
| coeffs_disparity_predictor.conv1.1.weight | torch.Size([32]) |
| coeffs_disparity_predictor.conv1.1.bias | torch.Size([32]) |
| coeffs_disparity_predictor.conv1.1.running_mean | torch.Size([32]) |
| coeffs_disparity_predictor.conv1.1.running_var | torch.Size([32]) |
| coeffs_disparity_predictor.conv1.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv2.0.weight | torch.Size([32, 32, 3, 3, 3]) |
| coeffs_disparity_predictor.conv2.1.weight | torch.Size([32]) |
| coeffs_disparity_predictor.conv2.1.bias | torch.Size([32]) |
| coeffs_disparity_predictor.conv2.1.running_mean | torch.Size([32]) |
| coeffs_disparity_predictor.conv2.1.running_var | torch.Size([32]) |
| coeffs_disparity_predictor.conv2.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv1_1.0.weight | torch.Size([64, 32, 3, 3, 3]) |
| coeffs_disparity_predictor.conv1_1.1.weight | torch.Size([64]) |
| coeffs_disparity_predictor.conv1_1.1.bias | torch.Size([64]) |
| coeffs_disparity_predictor.conv1_1.1.running_mean | torch.Size([64]) |
| coeffs_disparity_predictor.conv1_1.1.running_var | torch.Size([64]) |
| coeffs_disparity_predictor.conv1_1.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv2_1.0.weight | torch.Size([64, 64, 3, 3, 3]) |
| coeffs_disparity_predictor.conv2_1.1.weight | torch.Size([64]) |
| coeffs_disparity_predictor.conv2_1.1.bias | torch.Size([64]) |
| coeffs_disparity_predictor.conv2_1.1.running_mean | torch.Size([64]) |
| coeffs_disparity_predictor.conv2_1.1.running_var | torch.Size([64]) |
| coeffs_disparity_predictor.conv2_1.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv3.0.weight | torch.Size([128, 64, 3, 3, 3]) |
| coeffs_disparity_predictor.conv3.1.weight | torch.Size([128]) |
| coeffs_disparity_predictor.conv3.1.bias | torch.Size([128]) |
| coeffs_disparity_predictor.conv3.1.running_mean | torch.Size([128]) |
| coeffs_disparity_predictor.conv3.1.running_var | torch.Size([128]) |
| coeffs_disparity_predictor.conv3.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv4.0.weight | torch.Size([128, 128, 3, 3, 3]) |
| coeffs_disparity_predictor.conv4.1.weight | torch.Size([128]) |
| coeffs_disparity_predictor.conv4.1.bias | torch.Size([128]) |
| coeffs_disparity_predictor.conv4.1.running_mean | torch.Size([128]) |
| coeffs_disparity_predictor.conv4.1.running_var | torch.Size([128]) |
| coeffs_disparity_predictor.conv4.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv5.0.weight | torch.Size([128, 64, 3, 3, 3]) |
| coeffs_disparity_predictor.conv5.1.weight | torch.Size([64]) |
| coeffs_disparity_predictor.conv5.1.bias | torch.Size([64]) |
| coeffs_disparity_predictor.conv5.1.running_mean | torch.Size([64]) |
| coeffs_disparity_predictor.conv5.1.running_var | torch.Size([64]) |
| coeffs_disparity_predictor.conv5.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv6.0.weight | torch.Size([64, 32, 3, 3, 3]) |
| coeffs_disparity_predictor.conv6.1.weight | torch.Size([32]) |
| coeffs_disparity_predictor.conv6.1.bias | torch.Size([32]) |
| coeffs_disparity_predictor.conv6.1.running_mean | torch.Size([32]) |
| coeffs_disparity_predictor.conv6.1.running_var | torch.Size([32]) |
| coeffs_disparity_predictor.conv6.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.conv7.0.weight | torch.Size([32, 16, 3, 3, 3]) |
| coeffs_disparity_predictor.conv7.1.weight | torch.Size([16]) |
| coeffs_disparity_predictor.conv7.1.bias | torch.Size([16]) |
| coeffs_disparity_predictor.conv7.1.running_mean | torch.Size([16]) |
| coeffs_disparity_predictor.conv7.1.running_var | torch.Size([16]) |
| coeffs_disparity_predictor.conv7.1.num_batches_tracked | torch.Size([]) |
| coeffs_disparity_predictor.last_for_guidance.0.weight | torch.Size([32, 16, 3, 3, 3]) |
| coeffs_disparity_predictor.last_for_guidance.1.weight | torch.Size([32]) |
| coeffs_disparity_predictor.last_for_guidance.1.bias | torch.Size([32]) |
| coeffs_disparity_predictor.last_for_guidance.1.running_mean | torch.Size([32]) |
| coeffs_disparity_predictor.last_for_guidance.1.running_var | torch.Size([32]) |
| coeffs_disparity_predictor.last_for_guidance.1.num_batches_tracked | torch.Size([]) |
| dres0.0.0.weight | torch.Size([32, 44, 3, 3, 3]) |
| dres0.0.1.weight | torch.Size([32]) |
| dres0.0.1.bias | torch.Size([32]) |
| dres0.0.1.running_mean | torch.Size([32]) |
| dres0.0.1.running_var | torch.Size([32]) |
| dres0.0.1.num_batches_tracked | torch.Size([]) |
| dres0.1.0.weight | torch.Size([16, 32, 3, 3, 3]) |
| dres0.1.1.weight | torch.Size([16]) |
| dres0.1.1.bias | torch.Size([16]) |
| dres0.1.1.running_mean | torch.Size([16]) |
| dres0.1.1.running_var | torch.Size([16]) |
| dres0.1.1.num_batches_tracked | torch.Size([]) |
| guide.conv1.0.weight | torch.Size([16, 32, 1, 1]) |
| guide.conv1.1.weight | torch.Size([16]) |
| guide.conv1.1.bias | torch.Size([16]) |
| guide.conv1.1.running_mean | torch.Size([16]) |
| guide.conv1.1.running_var | torch.Size([16]) |
| guide.conv1.1.num_batches_tracked | torch.Size([]) |
| guide.conv2.0.weight | torch.Size([1, 16, 1, 1]) |
| guide.conv2.1.weight | torch.Size([1]) |
| guide.conv2.1.bias | torch.Size([1]) |
| guide.conv2.1.running_mean | torch.Size([1]) |
| guide.conv2.1.running_var | torch.Size([1]) |
| guide.conv2.1.num_batches_tracked | torch.Size([]) |
Number of model parameters: 5315811
参数总量为5.31M,参数主要集中在coeffs_disparity_predictor,因为是一个5维的匹配代价卷,所以参数量比较多。
(本文仅代表个人见解,如有不妥,欢迎大家共同探讨!如需转载,请联系本人。)

















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









