







收获
- 动态通信:减少了通信次数、缩小了通信成本、避免接受无用信息、减少了无用通信对合作的负面影响
- 双向LSTM,利用门遗忘不利于协作的内容
- 通信作用:团队内求异、团队间求同
摘要
通信可能是多智能体合作的一种有效方式。然而,在所有代理之间或在现有方法采用的预定义通信体系结构中共享信息可能存在问题。当存在大量的agent时,agent无法将有助于合作决策的有价值信息与全局共享信息区分开来。因此,交流对多智能体合作的学习几乎没有帮助,甚至会影响学习。另一方面,预定义的通信体系结构限制了代理之间的通信,从而抑制了潜在的合作。为了解决这些困难,本文提出了一个注意沟通模型,该模型学习何时需要沟通以及如何整合共享信息以进行合作决策。我们的模型导致了大规模多智能体合作的高效和有效的沟通。在经验上,我们在各种合作场景中展示了我们的模型的优势,在这些场景中,代理能够开发出比现有方法更协调和复杂的策略。
引语
- 问题:当存在大量的agent时,agent无法将有助于合作决策的有价值信息与全球共享的信息区分开来,因此交流对合作的学习几乎没有帮助,甚至可能危害到合作的学习。此外,在现实世界的应用中,agent之间相互通信都是昂贵的,因为接收大量的信息需要很高的带宽,时延长,计算复杂度高。预定义的通信体系结构可能会有帮助,但它们限制了特定代理之间的通信,从而限制了潜在的合作。
- 我们提出了一个被称为ATOC的注意通信模型,受视觉注意循环模型的启发,我们设计了一个注意单元,它接收一个agent编码的局部观察和动作意图,并决定该agent是否需要与其他agent在其可观察领域内进行交流合作。如果需要,呼叫发起者选择协作者组成一个通信组来协调策略。通信组只在必要时动态更改和保留。我们利用双向LSTM单元作为通信通道,连接通信组中的每个代理。LSTM单元以内部状态(即局部观察和动作意图的编码)作为输入,返回指导agent协调策略的思想。我们的LSTM单元有选择性地输出用于合作决策的重要信息,这使得agent在动态通信环境中学习协调策略成为可能。
- 我们实证地展示了三种情形下的ATOC的成功,分别对应于局部报酬、共享全局报酬和竞争报酬。结果表明,与现有方法相比,ATOC agent能够开发出更协调、更复杂的策略。据我们所知,这是第一次注意沟通成功应用于MARL。
相关工作
- 最近,一些端到端反向传播可训练的模型已经被证明是有效的学习MARL中的通信。
- DIAL[4]是第一个提出通过深度q网络反向传播进行可学习通信的机构。在每个时间步骤中,一个代理生成它的消息,作为其他代理为下一个时间步骤的输入。梯度通过沟通渠道从一个代理流到另一个代理,带来丰富的反馈,训练一个有效的渠道。但是,DIAL的通信相当简单,只需选择预定义的消息。
- CommNet是一个大型的前馈神经网络,它将所有代理的输入映射到它们的动作,其中每个代理占用一个单元子集,另外还可以访问一个广播通信信道来共享信息。在单个通信步骤中,每个代理将其隐藏状态作为通信消息发送到通道。来自其他代理的平均消息是下一层的输入,CommNet采用算术均值来整合agent共享信息。但是对于所有的agent来说,它只是一个大型的单一网络,难以扩展,在agent数量较多的环境中性能较差。值得一提的是,CommNet已经扩展为自然语言处理中的抽象摘要[2]。
- BiCNet[19]基于连续行动的行为者-批评模型,使用循环网络连接每个个体的策略和价值网络。BiCNet能够处理实时策略游戏,如星际争霸的微观管理任务。主从式[8]也是一个实时策略游戏的通信架构,其中每个从代理的动作都是由从代理和主代理的贡献组成的。然而,这两种工作都假设代理知道环境的全局状态,这在实践中是不现实的,BiCNet采用加权均值来整合agent共享信息。此外,预定义的通信体系结构限制了通信,从而抑制了代理之间潜在的合作。因此,他们不能适应场景的变化。
- MeanField[24]以相邻agent的观测和平均行为作为输入进行决策。然而,平均行动消除了相邻代理在行动和观察方面的差异,从而导致有助于合作决策的重要信息的丢失。
背景
- Recurrent Attention Model(RAM):在对图像的感知过程中,人类不是对整个感知场进行处理,而是将注意力集中在一些重要的部位,在需要的时候和地方获取信息,然后从一个部位转移到另一个部位。RAM[16]使用RNN来模拟注意机制。在每个时间步上,一个代理通过一个带宽受限的传感器获取并处理部分观测。从过去的观测中提取的瞥见特征以一种内部状态存储,并编码到RNN的隐藏层中。通过解码内部状态,agent决定传感器的位置以及与环境交互的动作。
方法
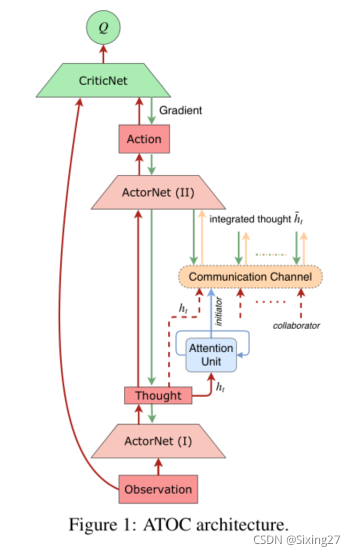
- 智能体i获得局部观测oit,编码本地观测和动作意图为hit,注意力模块将编码结果作为输入,并且确定在其可观测领域中是否需要通信进行合作。
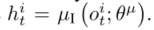
- 如果需要,代理会在其字段中选择其他代理,以组成一个通信组,该组保持相同的时间步长。沟通完全由注意力单位决定(何时和多长时间沟通)。
- 通信通道连接通信群中的各agent,输入各agent的思想,输出综合的思想,引导agent产生协调的行动。集成的思想属于hit(总)与hit合并,并馈入到政策网络的其余部分。然后,策略网络输出action it。
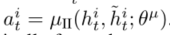
- 通过在动态形成的群体中共享局部观察和行动意图的编码,个体可以建立相对更全面的环境感知,推断其他个体的意图,并在决策上进行合作。
注意力模型
- 我们的注意力单元并没有对环境进行充分的感知,而只是对一个agent的观测结果和行动意图进行编码,决定沟通是否有利于合作。注意单元可以通过RNN或MLP实例化。产生思想的行为者网络的第一部分对应于glimpse网络,该思想可以看作是glimpse特征向量。注意单位以thought作为输入,产生agent的观测结果成为注意焦点的概率(即交流的概率)。
- 与MARL中现有的学习交流工作不同,例如:在CommNet和BiCNet中,所有的代理都可以随时进行通信,我们的注意力单元只在必要时才能实现代理之间的动态通信。这更加实际,因为在真实的应用程序中,通信受到带宽和/或范围的限制,并会产生额外的成本,因此在所有代理之间保持完全连接可能不可能,或者成本太高。另一方面,与完全连接相比,动态通信可以避免agent接收无用信息。如下一节所讨论的,无用的信息可能会对代理之间的合作决策产生负面影响。总的来说,注意力单元会导致更有效的沟通。
交流
- 当发起者选择其合作者时,它只考虑其可观察环境中的代理,而忽略那些无法被感知的代理。
- 这一设置符合以下事实:
- (1)通信的目的之一是分享部分观测结果,相邻的代理可以很容易地相互理解;
- (2)相邻代理之间更容易进行合作决策
- (3)所有的agent共享一个策略网络,这意味着相邻的agent可能有相似的行为,但通信可以增加它们策略的多样性。
- 在启动器的可观察环境中有三种类型的代理:其他发起代理;其他发起人选定的代理;未被选中的代理。
- 发起者首先从尚未选择的代理中选择协作者,然后从其他发起者选择的代理中选择协作者,最后从其他发起者中选择协作者,所有这些都基于邻近性。
- 当多个发起者选择一个代理时,它将参与每个组的通信。

- 多组共享的代理在个体组之间的信息鸿沟和策略划分之间架起了桥梁。它可以将一个团队的想法传播给其他团队,最终导致团队之间的协调策略。这对于所有代理在单个任务上协作的情况尤其重要。此外,为了解决角色分配和异构代理类型的问题,我们可以确定参与通信的代理的接口位置。
- 双向LSTM单元作为通信通道。它的作用是整合群体内各agent的内部状态,引导agent进行协调决策。不同于CommNet和BiCNet分别采用算术均值和加权均值来整合agent共享信息,我们的LSTM单元可以有选择地输出促进合作的信息,通过gate遗忘阻碍合作的信息。
训练
- 梯度被反向传播到策略网络和通信通道,以更新参数。然后,我们缓慢地更新目标网络
- 注意单元被训练为用于通信的二进制分类器。对于代理i,和他的分组i,我们计算协调行动和独立行动之间的平均Q值之差,衡量通信带来的性能提升。
- 一个时间步长周期结束,再使用log损失来更新注意单元。
实验
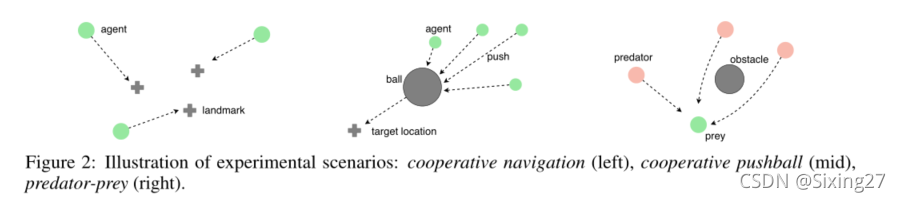
每个代理只能进行局部观察,独立且合作地行动,并收集自己的奖励或共享的全局奖励。我们在图2所示的三个场景中进行了实验,分别研究了在局部奖励、共享全局奖励和竞争奖励下的代理之间的合作。我们将ATOC与CommNet、BiCNet和DDPG进行了比较。CommNet和BiCNet是完整的通信模型,DDPG就是一个没有通信的TOC。MADDPG必须为每个agent训练一个独立的策略网络,这使得它在大规模MARL中不可行。
场景
- 合作导航(左)
- 合作推球(中)
- 捕食者-猎物(右)。
奖励
- 局部奖励
- 共享全局奖励
- 竞争奖励下的代理之间的合作
模型
- ATOC
- CommNet
- BiCNet
- DDPG
实验
实验是基于多智能体粒子环境[14,18]进行的,该环境是一个空间连续、时间离散的二维世界,由智能体和标志物组成。我们对环境做了一些修改,采用了大量的代理商。每个代理只能进行局部观察,独立且合作地行动,并收集自己的奖励或共享的全球奖励。我们在图2所示的三个场景中进行了实验,分别研究了在局部奖励、共享全局奖励和竞争奖励下的代理之间的合作。我们将A TOC与CommNet、BiCNet和DDPG进行了比较。CommNet和BiCNet是完整的通信模型,DDPG就是一个没有通信的TOC。MADDPG必须为每个agent训练一个独立的策略网络,这使得它在大规模MARL中不可行。
合作的导航
在这个场景中,Nagents协同到达llandmarks,同时避免碰撞。每个代理将根据其与最近的地标的距离获得奖励,而当它与其他代理发生碰撞时将受到惩罚。理想情况下,每个智能体根据自己的观察和从其他智能体接收到的信息预测附近智能体的行动,并决定自己在不与其他智能体发生冲突的情况下占领地标的行动。
我们训练了一个TOC和基线,设置为N=50和L=50,每个代理可以观察三个最近的代理和四个具有相对位置和速度的地标。在每个时间步中,代理的报酬都是㼿d、 其中,注意代理与其最近地标之间的距离,或㼿D㼿1如果发生碰撞。图3显示了3000集的平均回报学习曲线,在所有代理和时间步长上取平均值。我们可以看到TOC收敛到比基线更高的平均报酬。我们通过运行30个测试游戏来评估TOC和基线,并测量平均奖励、碰撞次数和占用地标的百分比。
如表1所示,TOC在很大程度上优于所有基线。在实验中,CommNet、BiCNet和DDPG都没有学习到TOC获得的策略。这是一名特工首先试图占领最近的地标。如果地标更有可能被其他代理占用,代理将转向另一个空地标,而不是继续探测和接近最近的地标。DDPG的战略更具侵略性,即:。e、 ,,多个代理通常同时接近一个地标,这可能导致冲突。CommNet和BiCNet代理都比较保守,即。e、 ,,他们更愿意避免碰撞,而不是占领一个地标,这最终会导致少数地标被占领。此外,CommNet和BiCNet代理更可能围绕地标并观察其他代理的行为。然而,聚集的代理容易发生碰撞。
由于没有沟通的TOC正是DDPG,TOC的表现优于DDPG,我们可以看到沟通确实有帮助。然而,CommNet和BiCNet也有通信,为什么性能差得多?CommNet对隐藏层的信息执行算术平均。此操作隐式地平等对待来自不同代理的信息。然而,来自不同代理的信息对于代理做出决策具有不同的价值。例如,来自附近一个想要夺取同一个地标的代理的信息要比来自远方代理的信息有用得多。在具有大量代理的场景中,存在大量无用信息,这些信息可以被视为干扰代理决策的噪声。BiCNet的用途一个RNN作为通信信道,可以看作是加权平均值。然而,随着代理数量的增加,RNN也无法捕获来自不同代理的信息的重要性。与CommNet和BiCNet不同,TOC利用注意单元动态执行通信,大多数信息来自附近的代理,因此有助于决策。
代理必须像在实验中一样共享策略网络。主要原因是大多数真实世界的应用程序都是开放系统,即。E特工来来去去。如果每个代理都使用一个独立的策略网络进行训练,那么该网络很容易过度适应环境中的代理数量,因此很难概括,更不用说在大规模多代理环境中训练大量独立策略网络(如MADDPG)所需的努力了。然而,共享策略网络的代理在策略方面可能是同质的,例如。GDDPG代理商都积极抢占地标,而CommNet和BiCNet代理商都很保守。然而,与这些基线不同,TOC代理的行为不同:当一个地标更有可能被代理占用时,附近的代理将转向其他地标。这背后的主要原因是TOC的通信方案。代理可以将其本地观察和意图共享给附近的代理,即。E动态形成的通信组。尽管通信组的大小很小,但是共享信息可以由属于多个组的代理在组之间进一步编码和转发。因此,每个代理可以获得更多和多样的信息。基于接收到的信息,代理可以推断其他代理的行为并相应地进行行为。总的来说,TOC代理展示了占领地标的合作策略。
为了研究TOC和基线的可伸缩性,我们直接使用设置为N=50和L=50的经过训练的模型来研究场景N=100和L=100。随着代理密度的增加,所有方法的碰撞次数都增加。然而,如表1所示,就所有指标而言,TOC仍然比基线好得多,这证明了TOC的可伸缩性。有趣的是,DDPG和CommNet的地标占用率有所增加。如前所述,CommNet的学习策略在原始设置中是保守的,因此,当代理密集且决策更具冲突性时,它可能会导致更多的地标被占用。DDPG被占据的地标百分比略有增加,但碰撞次数有所增加。BiCNet在所有指标方面的性能大幅下降表明其可扩展性差。
我们将TOC代理之间的通信可视化,以跟踪注意单元的效果。如图4(左三图)所示,注意力交流发生在主体密集、情境复杂的区域。随着游戏的进行,代理占据了更多的地标,因此不需要太多的沟通。我们选择一个交流小组,观察他们有无交流的行为。我们发现,没有通信的代理更可能以相同的地标为目标,这可能导致冲突,而具有通信的代理可以扩展到不同的地标,如图4(最右边的图)所示。
为了研究沟通和注意之间的相关性,我们进一步可视化了TOC代理在特定时间步长上的沟通及其在特定时间段内的相应注意热图
Figure5。发生通信的区域是注意焦点,如图5所示。只有在agent密集、地标不被占用的区域,才需要沟通进行合作决策。我们的注意力单元准确地学习我们所期望的,也就是。,只在需要时进行沟通。此外,我们关闭了A TOC代理的通信(没有再培训),性能下降,如表1所示。因此,我们认为在执行过程中的沟通对于更好的合作也是必不可少的。
合作推球
在这种情况下,共享全球奖励的Nagents合作地将一个沉重的球推到指定的位置。这个球比经纪人重200倍,大144倍。代理人通过碰撞而不是力来推动球,并通过不同的角度撞击球来控制运动方向。然而,在训练过程中,agent并没有掌握如何控制方向的先验知识。球的惯性质量使得agent很难改变其运动状态,球和agent的圆形表面使得任务更加复杂。因此,这项任务非常具有挑战性。在实验中,有50个agent,每个agent可以在预定义的距离内观察到球的相对位置,最多10个agent,指定的位置是操场的中心。每个时间步的奖励是-d,其中:为球到运动场中心的距离。
图6显示了学习曲线的标准化平均奖励为一个TOC和基线。TOC会收敛到比所有基线更高的奖励。CommNet和BiCNet具有相当的奖励,高于DDPG。我们通过运行30个测试游戏来评估一个TOC和基线。标准化平均奖励如表2所示。
TOC代理学习复杂的策略:代理通过击打球的中心来推动球;他们通过击打球的侧面来改变运动方向;当球接近目标位置时,一些agent会转向球的相反运动方向与球相撞,降低球的速度,以阻止球通过目标位置;最后,各agent分成大小相等的两部分,从两个相反的方向打击球,最终球将稳定在目标位置。移动方向和减速的控制体现了agent之间的分工和协作,这是通过通信来实现的。通过可视化agent的通信结构和行为,我们发现在同一通信组中的agent行为是同质的,例如:,一组智能体推动球,一组智能体控制方向,一组智能体在球接近目标位置时降低速度。
DDPG代理的行为都相似,没有分工。也就是说,几乎所有球员都从同一个方向推动球,这可能导致偏离方向或快速通过目标位置。直到球被推离目标位置,DDPG球员才意识到他们推错了方向,然后一起换到相反的方向。因此,球被向后推和力,很难稳定在目标位置。沟通确实有帮助,这也解释了为什么CommNet和BiCNet比DDPG更好。TOC比CommNet和BiCNet更好在实验中反映出ATOC的振荡幅度要小得多。主要原因已在前一节中解释。
为了研究通信在A TOC中的效果,我们关闭了A TOC agent的通信(没有再培训),结果如表2所示。A TOC的性能下降了,但它仍然比所有的基线要好。这背后的原因是,在训练过程中,沟通可以稳定环境。此外,在一个TOC中,合作策略梯度可以反向传播来更新单个策略网络,这使得agent可以推断其他agent的动作,从而进行合作行为。
捕食者-食饵
在这个经典的捕食者-猎物游戏的变体中,60个较慢的捕食者追逐20个较快的猎物,周围有5个路标挡道。每次掠食者与猎物碰撞时,掠食者获得+10奖励,而猎物则受到惩罚-10,每个代理观察5个最近的捕食者和3个最近的猎物的相对位置和速度,以及两个最近的地标的位置。为了控制在操场上的猎物而不是逃跑,猎物还会根据其坐标获得奖励(x, y)at each timestep. The reward is㼿f(x)㼿f(y), where f(a) = 0ifa0.9, F (a) = 10⇥(a port 0.9)if0.9< a <1,Otherwisef (a) = e2a - 2.
在这种情况下,捕食者合作包围并抓住猎物,而猎物则合作进行诱惑和逃避。在实验中,我们关注的是捕食者/猎物之间的合作,而不是它们之间的竞争。对于每种方法,捕食者和被捕食者是一起训练的。图7为捕食者和被捕食者对A TOC和CommNet的学习曲线。由于DDPG和BiCNet在此场景下的学习曲线不稳定,我们仅展示A TOC和CommNet的学习曲线。从图7中我们可以看出,A TOC比CommNet收敛得快得多,其中A TOC在1000集之后稳定下来,而CommNet在2500集之后稳定下来。如图7所示,由于场景的设置似乎更有利于捕食者而不是猎物,因此TOC和CommNet捕食者都比猎物收敛得更快。
为了评估性能,我们在A TOC和基线之间进行交叉比较。也就是我们在游戏中使用一个TOC捕食者对抗基线猎物,反之亦然。结果显示在0-1的标准化平均掠夺者得分30次测试运行的每个游戏,如图8所示。第一个bar cluster表示的是相同方法下捕食者与猎物之间的博弈,由此我们可以看出,由于捕食者在所有方法中得分都是正的,所以游戏设置确实对捕食者更有利。第二个条形图显示了A TOC捕食者对抗DDPG、CommNet和BiCNet捕食者的游戏分数。我们可以看到,A TOC捕食者的得分高于所有基线的捕食者,因此也比其他捕食者更强。第三个栏显示了DDPG、CommNet和BiCNet捕食者对抗A TOC猎物的游戏。捕食者的得分都很低,与第一个集群的得分相当。因此,我们认为,即使在竞争环境中,ATOC也能带来比基线更好的合作,而且TOC捕食者和被捕食者的学习策略可以推广到不同策略的对手。
总结
我们提出了一种大规模多智能体环境下的注意通信模型,其中智能体学习一个注意单元,该注意单元动态地决定是否需要进行通信以进行合作,同时学习一个双向的LSTM单元作为通信通道来接收来自其他智能体的编码信息。与现有的通信方法不同,ATOC可以有效地利用通信来进行合作决策。从经验上看,ATOC在多种协作多智能体环境下优于现有的方法。















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









