







摘要
在特殊的团队合作中,多个代理需要在不了解他们的队友或他们的计划的前提下进行协作。在这个研究领域,一个常见的假设是代理不能通信。然而,就像两个随机的人可能说同一种语言一样,自治的团队成员也可能碰巧共享一个通信协议。本文考虑了如何利用这种共享协议,引入了一种方法来推理Ad Hoc团队通信(CAT)。这项工作的目标是通过明智地利用团队通信能力来实现改进的Ad Hoc团队。我们将我们的研究置于一个新的CAT场景中,包括多个步骤的任务,队友的计划会随着时间的推移而公布。在此背景下,本文提出了对通信的时间和价值进行推理的方法,并介绍了一种利用这些方法的自组织代理算法。最后,我们引入了一个新的多智能体领域,即工具获取领域,并研究了该领域的属性变化对通信有用性的影响。实证结果表明,在特殊团队合作中,明确的沟通内容和时间推理是有好处的。
- Ad Hoc Teamwork:临时合作团队、特殊团队
- CAT(Communication in Ad Hoc Teamwork): Ad Hoc团队合作中的沟通
- SOMALI CAT:本文应用场景
引语
- 随着代理变得更加强大和多样化,它们更有可能在新的情况下需要合作,而没有事先协调的能力。例如,在流行病爆发时,可以部署服务机器人协助医疗队。这种异构机器人可能在部署时不需要事先协调彼此的协助能力,但只有它们能够协同工作,并与医疗团队一起工作,而不需要事先明确提供协调策略,它们才会有效。
- 这种动机是Ad Hoc Teamwork合作的基础,该团队合作被定义为在没有事先协调的情况下与队友合作。这个术语反映了协作是特别的——代理学习、行动和互动的方式可能是相当有原则的。有两个主要属性可以区分特别团队协作与其他多代理系统。首先,它假设所有的队友都努力协作。第二,环境和队友的属性不能由临时代理改变。它的任务是在这些条件下进行推理和计划。
- 在许多实际情况下,以前不熟悉的代理仍然可能共享通信协议。在急诊的例子中,一旦部署了一个机器人,即使它不知道医生的具体目标或计划,他们仍然可以使用视觉和听觉信号交流,通过选择一个清晰的计划(Kulkarniet al ., 2019),或者通过改变队友的可实现的行动(Bisson et al ., 2011)。
- 本文的主要贡献是详细研究了一个更通用的CAT场景,该场景可以建模一个服务机器人,为医院的医生取不同的工具。医生通常会避免与机器人交流的额外认知负担,但会偶尔回答机器人提出的问题,这样机器人就能成为更好的合作者。基于此场景的核心属性,我们将其命名为顺序一次性多agent有限查询CAT场景,或SOMALI CAT。在SOMALI CAT中,代理执行顺序计划,只有特别代理可以查询队友的目标。SOMALI CAT被定义为具有广泛代表性的一类CAT问题。
- 在这里,我们研究了所有CAT问题中常见的几个问题:
- 潜力:在哪些情况下通信可以发挥作用的?
- 内容:要传达什么?
- 时间安排:代理何时沟通?
- 为了在SOMALI CAT的背景下回答这些问题,我们提供了通信价值的衡量标准,这是由信息的价值驱动的。这些度量在启发式算法中使用,该算法可以推理查询内容和时间,以便更好地理解团队成员的计划,同时最小化总执行成本。
- 作为第二个贡献,我们的实证分析引入了一个新的多智能体领域,在这个领域中,不同的CA T属性可以使通信或多或少有用。在这个工具抓取域中,一个代理访问一个工作站,而其他成员为该工作站获取相关的工具。
相关工作
Ad Hoc Teamwork(特别团队协作)
- 临时团队合作最初是作为一种挑战引入的,即创建一种自主代理,能够与之前不认识的团队成员在各自能够作为团队成员贡献的任务上高效、稳健地协作。
- 随后的工作提出通过将他们映射到一组类型中的一个来建模团队成员。我们的工作类似于将团队成员的类型表示为最终目标。Wang等人[2020]最近提出了一种反向强化学习技术,可以在没有沟通可用的情况下动态推断队友的目标。Barrett等人[2014]是第一个在多臂强盗问题的背景下对CAT进行推理的人。有一些关于临时代理的工作,试图影响他们的队友的行为。与我们的研究不同,在我们的研究中,互动是通过显性交流来完成的,而这些研究则是通过情景场景中行为主体的行为选择来实现隐性交流或互动。
多智能体通信
- 在多智能体系统的背景下,通信智能体的概念是一个肥沃的研究领域[Singh, 1998]。与多智能体系统中其他通信工作不同的是,它采用了单个智能体试图通过预定义的策略与其他成员协作的观点:单个智能体不能改变其他成员对通信信息的响应方式。相比之下,在一般的多智能体通信中,智能体之间的推理能力通常是对称的(分布式决策)。这种观点将挑战从协议设计的角度转移到对其他代理的信息状态进行推理的角度。
- 在本节的其余部分中,我们将重点关注做出类似假设的作品。强化学习是一种学习方法,其中agent主动尝试新事物,而不是遵循固定的策略[Epshteynet al., 2008]。研究各种交流机制,促进学习。一些作品允许学习agent接受评论[Griffithet al., 2013]或建议。在这些作品中,信息由教师提供,其他主体被动地将其整合。随着深度学习的最新发展,针对多智能体系统的一个子领域提出了若干工作,其中智能体使用学习的通信协议共享信息[Hernandez-Lealet al., 2019;Mordatch and Abbeel, 2018;Foersteret al ., 2016)。这些工作做了一些没有在本工作中使用的假设:代理可以学习新的沟通技巧,以及代理在执行前与队友一起训练。
建模其他智能体
- 另一个相关的研究领域是目标识别,在给定一系列观察到的动作后,观察者需要识别行动者的目标。目标识别中一个常见的假设是关键孔假设,即行动者没有意识到观察者[Kautz和Allen, 1986],这个假设在我们的工作中并不成立。其他一些研究也打破了这一假设,要么是为了在存在歧义时进行沟通[Mirskyet al., 2018],通过执行行动试图协助其他代理[Fernet al., 2007],要么是为了消除假设之间的歧义[Shvo和McIlraith, 2020],或通过影响其他代理人采取特定的行动过程[Bissonet al., 2011]。这些工作没有量化特定查询的值,也没有提供一种算法,可以利用这个值与其他代理协作进行规划。
SOMALI CAT
本文的其余部分集中于SOMALI CAT情景。在这个场景中,有两个代理:我们设计的临时代理和它的队友。团队成员心中有一个目标(从一组可能的任务中执行一个任务),临时代理需要通过帮助任务执行来帮助该团队成员。临时代理能够询问队友关于它的目标,在这种情况下,队友总是做出响应就会产生成本。
我们使用以下属性来定义SOMALI CAT:
- 环境:所执行的任务需要一系列的操作。这也是一项断断续续的一次性任务。环境是静态的、确定的、完全可观察的。
- 队友:一个被认为对环境有充分了解的队友。假设它是最优计划,因为它不知道临时代理的计划或成本。
- 通信通道:有一个通信通道,其中特设代理可以将查询作为一个操作,如果它这样做,团队成员将放弃其操作以真实地回复(通信通道是无噪声的)。
为了解释和举例说明我们在SOMALI CAT问题中的定义,我们引入了一个特定的领域:工具抓取领域。有两个代理、n个工作站、一个工具箱里面有n个工具,每个工作站只需要一个工具
环境中的两个代理是:一个临时代理:fetcher 和一个队友:worker。工具只能由fetcher 来取。worker的任务是使用某个工作站,而fetcher的任务是尽可能快地将所需的工具带到那个(最初未知的)工作站。
agent可以通过执行以下动作之一来改变自己的位置:Ufor向上移动,Dfor向下移动,Rfor向右移动,Lfor向左移动,orN for留在原地。
Fetcher也可以选择一个工具(T)或问一个问题(Q)。我们评估的问题格式是“你的目标工作站是什么?”以及“你的目标是g吗?”其中g是工作站的子集。工作人员必须立即(且真实地)回应一个问题®,这将导致他失去执行任何其他行动的机会。在每个时间步骤中,两个代理都根据它们感兴趣的执行操作分别做出决定。冲突只会在获取器问问题(Q)时发生,这将迫使worker执行应答操作®而不是执行计划的操作。
当两个代理都到达了某个工作站,并且Fetcher持有相关的工具时,问题就成功地结束了。在我们的设置中,Fetcher一次只能持有一个对象。除非代理与工具处于同一位置,否则拾取没有效果。图1显示了正在运行的工具获取域的示例,代理位于它们的初始位置。

获取域的工具示例。W、F、T 对应 worker, fetcher和toolbox的位置。工作站的位置用编号的方框表示。
圆圈表示每条路径属于哪个区域(参见第5节了解更多关于区域的信息)。空心的红色圆圈表示只属于信息区域的步骤。绿色的粗圈表示只属于计划分支区域的步骤。蓝色硬盘显示的是所属Zone的步骤。
Query Potential
- 定义查询潜力,即在CAT域中查询的最大收益相对于该域不进行查询的最小成本。
- 将CAT中的域模型看作是团队成员的一组操作(AT)和临时代理的一组操作(AA)、一组查询Q(Q属于AA)和一个成本函数©,该函数映射代理(C(pA, pT))的联合计划执行,p为计划。
- 假设团队成员有一个不受临时代理影响的计划(pT),但临时代理的计划取决于团队的行动(πA)。基于这些假设,在要求精确查询的约束下,临时代理对C的最优行为可以定义为队友的计划和k的函数:(πA: A∗T×N→A∗A)。该函数是针对特定代理的最优策略的跟踪,给定其对队友计划的不确定性。由于这种不确定性,跟踪可能包括等待、查询或回溯等操作。
- 直观地说,域内的查询值就是通过查询得到的最大增益。因此,我们现在将领域D={AT, AA, C}的查询潜力定义为:
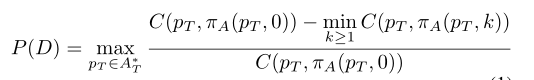
- 如果具有和不具有最佳查询的最优计划的成本是相同的,那么查询潜力为0。
- 如果有一个查询可以提高临时代理执行的总预期成本,那么它的潜力为正值。
- 如果所有查询只能使总成本更糟,那么它的潜力为负值。
- 如果域的查询潜力是正的,并且所有查询都有相同的成本,那么在任务开始时查询所有目标是最优行为,这似乎是合理的。然而,在下一节中,我们将反驳这个概念,并给出查询的最佳时机的上界和下界。
Query Content and Timing
- 在我们的环境中评估特定查询的值。直观地说,查询的值取决于查询的时间。
- 一般来说,对于团队成员的任何计划,都有一定的时 间使其目标从其行动中变得清晰。Keren等人[2014]将这一概念形式化为Worst Case Distinctiveness(wcd),或最优计划在两个目标之间模糊的最大时间。
定义1
- 它知道在wcd t (i, j)时间步之后不查询这个信息就会显示出来,其中wcd t (i, j)是wcd于通过观察它的动作来消除队友的目标j和目标j之间的歧义。
定义2
- 利用这一洞察力,我们可以定义临时代理通过查询目标 i ,j 获得信息的时间:
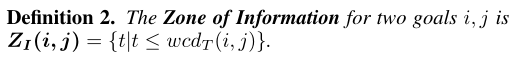
- 假设在给定的时间步长内,两个最优计划可以是相同的,在此时间过后,队友的目标不会有新的信息需要改变计划。然后,我们可以计算出在没有额外预期成本的情况下,我们的计划仍可以改进的时间:
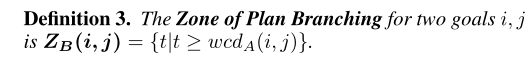
因为我们既需要改进计划的能力,也需要获取信息的能力,所以我们可以定义一段时间,在这段时间内,我们可以从查询中获得价值,而不需要提交可能招致惩罚的计划:
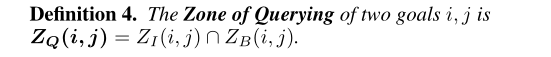

从直觉上讲,只有当团队成员执行的动作序列是在两个或两个以上的目标优化计划之前,并且临时代理的下一个动作偏离了至少一个目标的优化计划时,查询才会有好处。这意味着,在zq (G0)内的第一个时间步骤是**(1)特别代理可能执行错误的操作和(2)对于团队成员的目标可能仍然存在一些不明确的第一个时间步骤**。

在我们正在运行的示例中,关键查询点是CQP({1}) =CQP({2}) =CQP({1,3}) = 6,和CQP({3}) =−1。接下来,我们为ad hoc代理提出一种启发式规划算法,该算法考虑关键查询点来询问目标sg0 (G)的每个子集,并为某个g0选择第一个时间步骤为acqp,并查询“您的目标是inG0吗?”
Query Algorithm
在本节中,我们将介绍一种算法,用于规划特设代理的操作,同时对一组目标的查询区域进行推理,以确定何时进行查询。该算法由三部分组成:(1)计算所有目标对的wcdt和wcda,并将这些值保存在一个矩阵中;(2)计算多个目标的zq值;(3)使用这些信息来决定何时查询什么。
计算最坏情况下的差异值。除了形式化wcd之外,Keren等人[2014]还提供了一种计算两个目标的wcd的有效方法。任何两个目标的zq仅仅是从wcdatowcdt开始的时间间隔,可以通过矩阵查找来确定。
CalculatingZQfor多个目标。计算两个以上目标的zq要复杂得多。首先,对于一组目标sg0 (G),计算zb (G0)和zi (G0):
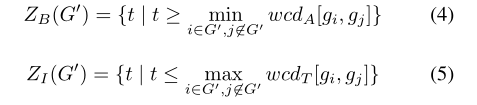
已知zb (G0)和zi (G0),取zbandzifor goalsi的所有并集的交点,使i∈G0, j∈G\G0,用式2计算zq (G0)的值。
决定何时查询。我们已经展示了如何对一组目标进行计算,现在我们可以利用该信息来确定何时进行查询。如上所述,CQP对应于zq的第一个点,这是查询一组目标的最佳时间。此外,我们知道我们不能从查询中获得价值来消除目标的歧义whoseZQ=∅。我们在算法1中完成了这个策略。计算完zqfor allG0后,一个知情的ad hoc代理将选择在最早的cqp for anyG0进行查询,并将选择一个消除歧义的g0frommg \G0的查询,例如“您的目标是inG0?”在我们的域中,最小cqpi与allg0的值相同,这样cqp (G0)6=−1。
















 77
77











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









