







评价指标BLEU 原理+例子+代码
简介
BLEU全称:BiLingual Evaluation Understudy(双语评价替补,代替人对机器翻译的质量进行评价)
用于评估哪些模型的性能?2002年论文用户评价机器翻译的质量,即用来计算模型生成的语句(candidate)与参考的语句(reference)之间的相似性。因此,也可以用于文本生成领域,另一篇博文介绍的可解释推荐领域也可以应用此指标对结果进行评估。
背景
对机器翻译的结果进行评价需要考虑翻译的adequacy, fidelity, and fluency,因而十分耗时且成本高。为此,作者提出了BLEU评价指标,该指标具有快速、成本低、不依赖于具体语言、与人类评价结果高度相关和每次运行时边际成本低的优点。
作者的出发点在于认为,机器翻译和专家翻译的结果越接近,翻译的质量越高。因此,作者实际上需要做两件事,作者首先要提出一个量化的度量翻译相似性的指标,另外还需要一个高质量的专家翻译的语料库。作者主要研究的是第一个评价指标,即BLEU。
标准的N-gram精确度和修正的N-gram精确度
标准的N-gram精确度(standard N-gram precision)
standard N-gram precision使用传统的precision的定义。
以下面的Example 1为例
- Example 1
- Candidate 1: It is a guide to action which ensures that the military always obeys the commands of the party.
- Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
- Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
- Reference 3: It is the practical guide for the army always to heed the directions of the party.
首先,我们尝试计算unigram precision,很容易看出在Candidate 1中除了“obeys”之外都在reference语句中出现过(大小写不同可匹配,如party和Party,但是原型和第三人称单数不能匹配,Candidate 1中的commands无法与Reference 2,而只与Reference 1匹配)
可以使用如下代码进行计算,结果为17/18=0.9444
from nltk.translate.bleu_score import sentence_bleu
reference1 = "It is a guide to action that ensures that the military will forever heed Party commands".split()
reference2 = "It is the guiding principle which guarantees the military forces always being under the command of the Party".split()
reference3 = "It is the practical guide for the army always to heed the directions of the party".split()
reference = [reference1, reference2, reference3]
candidate = "It is a guide to action which ensures that the military always obeys the commands of the party".split()
score = sentence_bleu(reference, candidate, weights=[1, 0, 0, 0])
print(score)
尝试计算2-gram precision,可以发现Candidate 1中的“action which”、“which ensures”、“military always”、“always obeys”、“obeys the”、“the commands”和“commands of”没有出现在reference语句中,因此结果为10/17=0.5882
在实现上把上面代码倒数第二行改为下面的代码即可
score = sentence_bleu(reference, candidate, weights=[0, 1, 0, 0])
修正的N-gram精确度(modified N-gram precision)
标准的N-gram精确度看似解决了问题,但是在处理下面的Example 2时会遇到问题
- Example 2
- Candidate: the the the the the the the.
- Reference 1: The cat is on the mat.
- Reference 2: There is a cat on the mat.
Example 2的翻译显然不尽人意,但是使用standard N-gram precision计算出的unigram的结果是7/7,显示不合适。不合适的原因在于reference中的单词被重复用于匹配,更合理的设置是如果Reference语句中的单词片段已被匹配,那么该片段就不能再次被匹配,并且单词片段只能取一个Reference语句中出现次数的最大值,例如7个the分别在Reference 1 和 2中出现2和1次,所以取2而不是两者相加的3。
代码如下,结果是2/7=0.2857
from nltk.translate.bleu_score import sentence_bleu
# 不加Here的话结果是1/7,即无法把大写的The与the进行匹配,该问题后面再解决
reference1 = "Here the cat is on the mat".split()
reference2 = "There is a cat on the mat".split()
reference = [reference1, reference2]
candidate = "the the the the the the the".split()
score = sentence_bleu(reference, candidate, weights=[1, 0, 0, 0])
print(score)
多个句子上的测试集的modified N-gram precision的公式如下所示
p
n
=
∑
C
∈
{
C
a
n
d
i
d
a
t
e
s
}
∑
n
−
g
r
a
m
∈
C
C
o
u
n
t
c
l
i
p
(
n
−
g
r
a
m
)
∑
C
∈
{
C
a
n
d
i
d
a
t
e
s
}
∑
n
−
g
r
a
m
∈
C
C
o
u
n
t
(
n
−
g
r
a
m
)
p_n = \frac{\sum_{C \in \{Candidates \}} \sum_{n-gram \in C} Count_{clip}(n-gram)} {\sum_{C \in \{Candidates \}} \sum_{n-gram \in C} Count(n-gram)}
pn=∑C∈{Candidates}∑n−gram∈CCount(n−gram)∑C∈{Candidates}∑n−gram∈CCountclip(n−gram)
分子的计算公式为
C
o
u
n
t
c
l
i
p
(
n
−
g
r
a
m
)
=
m
i
n
(
C
o
u
n
t
(
n
−
g
r
a
m
)
,
R
e
f
(
n
−
g
r
a
m
)
)
R
e
f
(
n
−
g
r
a
m
)
=
m
a
x
(
R
e
f
j
(
n
−
g
r
a
m
)
)
,
j
=
1
,
2
,
.
.
.
,
M
Count_{clip}(n-gram) = min(Count(n-gram), Ref(n-gram)) \\ Ref(n-gram) = max(Ref^j(n-gram)),j=1,2,...,M
Countclip(n−gram)=min(Count(n−gram),Ref(n−gram))Ref(n−gram)=max(Refj(n−gram)),j=1,2,...,M
首先从M个参考句子中找出所要找的n-gram的最大值,如在Example 2中对于‘the’这个n-gram最多的是Reference 1,且
R
e
f
(
′
t
h
e
′
)
=
2
Ref('the')=2
Ref(′the′)=2,然后在Candidate中
C
o
u
n
t
(
′
t
h
e
′
)
=
7
Count('the')=7
Count(′the′)=7,因此
C
o
u
n
t
c
l
i
p
(
′
t
h
e
′
)
=
2
Count_{clip}('the')=2
Countclip(′the′)=2。
综合考虑的Precision
对于不同的n,会有不同的
p
n
p_n
pn,如1-gram会得到
p
1
p_1
p1,而2-gram会得到
p
2
p_2
p2。因此,如果将不同n得到的不同的
p
n
p_n
pn组合成最后的precision是下面遇到的问题,考虑下简单的线性加权?作者给了一个测试集在不同的n-gram下的结果
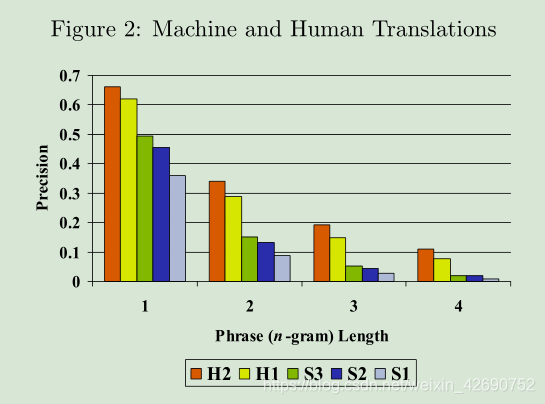
X轴上是n,不同的颜色柱代表不同的模型,很显然伴随着n的增加,
p
n
p_n
pn呈现出的是指数下降的趋势。因此,取对数后再加权更加合适。n的总数为N,一般N取4,用
ω
n
\omega_n
ωn表示权重,那么综合的
p
a
v
g
p_{avg}
pavg为
p
a
v
g
=
e
∑
n
=
1
N
ω
n
l
o
g
(
p
n
)
p_{avg} = e^{\sum_{n=1}^N\omega_n log(p_n)}
pavg=e∑n=1Nωnlog(pn)
至此,
p
a
v
g
p_{avg}
pavg已经实现了两大功能:
- 1、对candidate中没有出现在reference中的单词或词组进行了惩罚
- 2、对在candidate中异常出现的重复词语(大于单条reference中该词语出现的最大次数即为异常)进行了惩罚
BP值(Brevity Penalty)和BLEU值的计算公式
Brevity Penalty
尽管 p a v g p_{avg} pavg已经看起来很完美,也确实能在很多情境下发挥作用,但请看下面的例子
- Example 3
- Candidate 1: of the
- Candidate 2: of the party
- Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
- Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
- Reference 3: It is the practical guide for the army always to heed the directions of the party.
显然,这样的Candidate 1质量较低,但是计算得出的 p 1 p_1 p1为2/2,计算得出的 p 2 p_2 p2为1/1。出现该问题的原因在于,Candidate 1过短实际上只匹配了Reference中的一部分,那么很自然的想到 能不能用recall解决这一问题?是的,使用recall之后会得出Candidate 2的质量高于Candidate 1的结论,满足题意,但是对于下面的例子呢?
- Example 4
- Candidate 1: I always invariably perpetually do.
- Candidate 2: I always do.
- Reference 1: I always do.
- Reference 2: I invariably do.
- Reference 3: I perpetually do.
在每个reference上,Candidate 1的recall都不低于Candidate 2,但显然Candidate 2的质量更高。因此不能采用recall指标。
为了解决Example 3中的Candidate 1因为过短导致modified N-gram precision无法准确衡量翻译质量的问题,作者设置了BP(Brevity Penalty)指标。由于在modified N-gram precision已经对Candidate过长进行惩罚(过长则分母较大),此处仅需要对Candidate过短进行惩罚。令
c
c
c表示Candidate的长度,
r
r
r表示reference中长度最接近Candidate的句子的长度,当
c
c
c小于
r
r
r时进行惩罚
B
P
=
{
1
i
f
c
>
r
e
1
−
r
/
c
i
f
c
≤
r
BP=\left\{ \begin{array}{rcl} 1 & & {if c > r}\\ e^{1-r/c} & & {if c \leq r} \end{array} \right.
BP={1e1−r/cifc>rifc≤r
假设Candidate的长度为18,而reference分别为16、18、16,则
c
c
c为18,
r
r
r为18(选择最接近Candidate的长度)。
BLEU
将BP和modified N-gram precision进行整合,可以得到BLEU值
B
L
E
U
=
B
P
⋅
p
a
v
g
=
B
P
⋅
e
∑
n
=
1
N
ω
n
l
o
g
(
p
n
)
BLEU=BP \cdot p_{avg}=BP \cdot e^{\sum_{n=1}^N\omega_n log(p_n)}
BLEU=BP⋅pavg=BP⋅e∑n=1Nωnlog(pn)
一般,N取4,
w
n
w_n
wn取1/N
实现代码(借助于NLTK库)
其实在上文中,本文已经使用NLTK库进行了计算,在这里主要对其中的函数进行介绍
score = sentence_bleu(reference, candidate, weights=[1, 0, 0, 0])
首先,要注意的是,该代码计算的是BLEU值,因为例子中的BR为1,所以计算出的BLEU等于
p
1
p_1
p1
代码中的参数weights=[1, 0, 0, 0]列表中的四个数字分别表示
ω
1
,
ω
2
,
ω
3
,
ω
4
\omega_1,\omega_2,\omega_3,\omega_4
ω1,ω2,ω3,ω4,仅设置
ω
1
\omega_1
ω1为1表示计算的是BLEU-1,如果想计算BLEU-4,代码改为如下即可
score = sentence_bleu(reference, candidate, weights=[0.25, 0.25, 0.25, 0.25])
参考资料
- BLEU论文(Bleu: a Method for Automatic Evaluation of Machine Translation)
- 一种机器翻译的评价准则——Bleu
- 机器翻译评价指标BLEU介绍
- 机器翻译之BLEU值
- 机器翻译评测——BLEU算法详解 (新增 在线计算BLEU分值)

















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









