







 本文通过Python对纽约出租车数据进行分析,包括聚类区域划分、客流趋势动态展示和邻居分析。利用数据挖掘,揭示了出租车运行的时空特征,如客流密集区域、时间因素对运行的影响以及区域间客流量。
本文通过Python对纽约出租车数据进行分析,包括聚类区域划分、客流趋势动态展示和邻居分析。利用数据挖掘,揭示了出租车运行的时空特征,如客流密集区域、时间因素对运行的影响以及区域间客流量。
一、项目概述
根据出租车的运营数据,针对客户旅途时间展开分析与建模,对客流趋势及区域分布进行分析,对出租车历史数据进行分析,为客户预测预计到达时间等
过程设计:
提出问题
理解数据
数据清理
数据分析
得出结论
重要字段说明 :
编号: id
出租车类型: vendor_id
上车时间: pickup_datetime、
下车时间: dropoff_datetime、
乘客数量: passenger_count 、
上车地点 : pickup_longitude(经度)、pickup_latitude(纬度)、
下车地点: dropoff_longitude (经度)、 dropoff_latitude(纬度)、
旅途持续时间(秒): trip_duration。
首先导入需要的模块
#导入包
import os
import pandas as pd
import numpy as np
from matplotlib.pyplot import *
from matplotlib import animation
from matplotlib import cm
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from dateutil import parser
import io
import base64
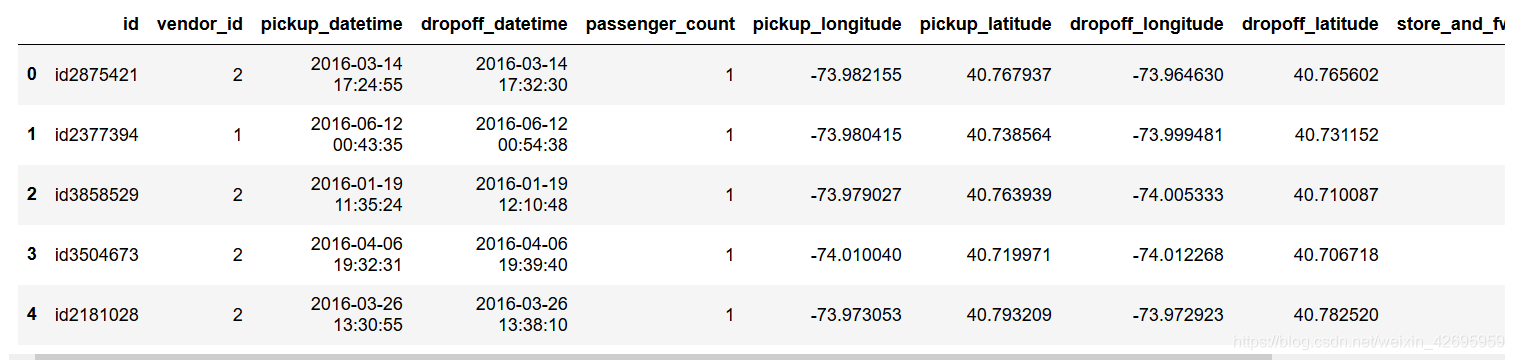
导入数据,查看前五行:
df=pd.read_csv(r'C:\Users\www12\Desktop\python\pythonDA\NewYork\train.csv')
df.head()
print(df.shape[0])
1458644
二、聚类区域划分
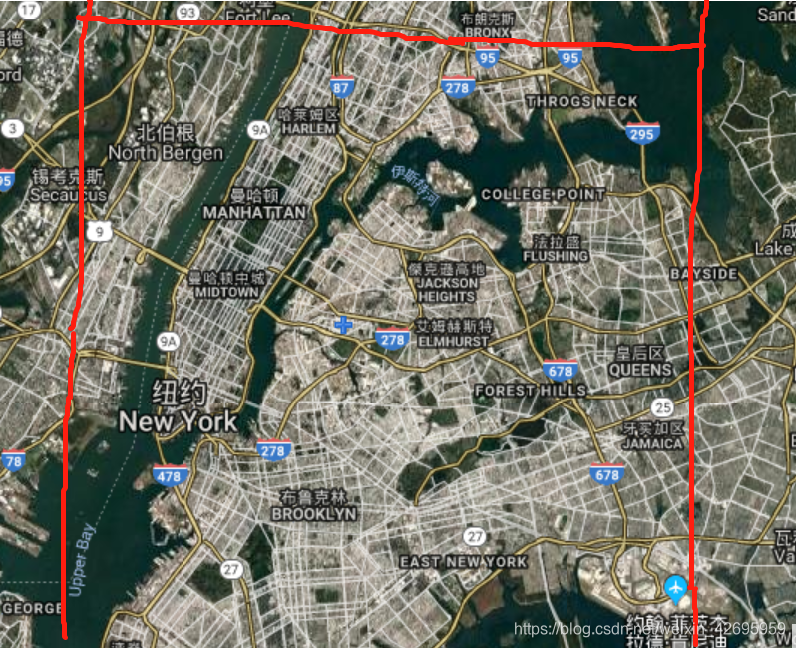
查看纽约市地图,划分出分析区域的经纬度,再根据数据分布情况,选择对经度[-74.03,-73.77],纬度[40.63,40.85]之间数据较为集中的区域进行分析,筛选掉区域之外的地点。
xlim=[-74.03,-73.77]
ylim=[40.63,40.85]
df=df[(df['pickup_longitude']>=xlim[0]) & (df['pickup_longitude']<=xlim[1])]
df=df[(df['dropoff_longitude']>=xlim[0]) & (df[' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









