






前言
今天看了一篇结肠息肉分割的论文《Automatic Polyp Segmentation with Multiple Kernel Dilated Convolution Network》,顺便看了一下源码,觉得写得挺规整的,因为自己主要用tensorflow所以试着用tensorflow实现一下,这次在努力做到和源码完全一致了。其实网络结构本身还是比较规矩的,这次编程主要是尝试一下上传代码到github,还有另外一点很有趣,我学会了如何截取预训练模型的特定层,比如说resnet50,只选取第二到第三个卷积块的结构和权重。
文献:https://arxiv.org/abs/2206.06264v1
源码:https://github.com/nikhilroxtomar/MKDCNet
自己写的Tensorflow实现:https://github.com/pokemon493/TF_MKDCNet
一、MKDCNet概述
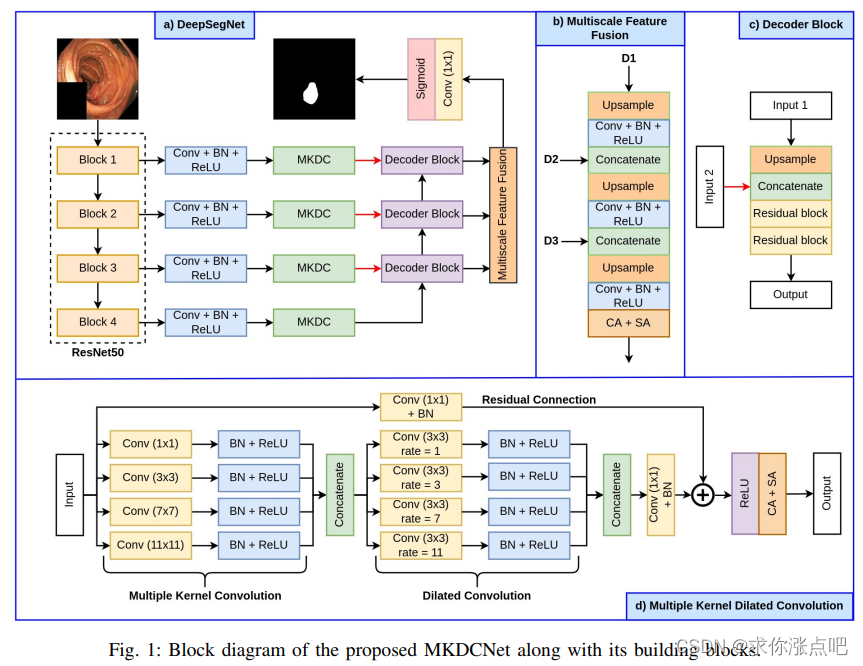
由于结肠息肉的大小和形状多变,提取多尺度的特征是十分重要的。相关工作也主要集中在多尺度和注意力方面。作者也给出“提取多尺度特征”这一问题自己的答案,一个是大卷积核+大扩张率的3x3卷积堆叠提取多尺度特征,另一个是解码器结构的多尺度特征融合。作者还使用了空间和通道注意力(结构类似CBAM),但是如今这种基础的注意力已经沦为了在论文中用一句话提一下、连结构都不用画的地步了(卷 起 来 了)。
放个网络结构图在这里,其实就已经挺明显的了。MKDCNet(Multiple Kernel Dilated Convolution Network)的主要结构还是UNet那一套编-解码结构。该网络使用了预训练的ResNet50做编码器主干网络,编码器特征经过卷积+BN+ReLu降维后送入MKDC(多核扩张卷积)模块。然后输入到传统UNet的逐级解码器块,本文还特意将解码器特征进行了一个多尺度融合,最后进行输出。
在多核扩张卷积模块中,先使用四个并行的卷积(1x1, 3x3, 7x7, 11x11)提取多尺度特征,然后再用四个并行的3x3卷积(扩张率1, 3, 7, 11)进一步增大感受野,多尺度特征随后和残差路径相加,并且被馈送入空间和通道注意力模块。这个模块感觉类似DeepLab V3+里提出的空洞空间金字塔池化(ASPP),但是感受野似乎比ASPP还要大的多。而且用到了不带扩张率而且非深度可分离的11x11卷积核,可以说是非常豪迈了。
解码器和普通UNet差不多,相当于一个卷积块换成了两个残差块。
解码器部分的特征被进一步传入到多尺度特征融合(Multiscale Features Fusion)模块。感觉这个模块有点冗余,结构上像是又搞了一个解码器的样子,只不过在模块的最后加入了注意力机制,但是文章里的消融实验表明这个模块还是有用的,可能是起到类似深监督的作用吧。
值得注意的是网络的参数量控制得不错,除了编码器和最终的输出卷积外,网络中每一层的卷积核数量基本都是96,因此哪怕使用了11x11还不带扩张率的超大卷积核,也基本把参数量压缩到小于20M的范围内。
结果比较就不放图了,有兴趣可以看原文,虽然作者说自己的方法达到了SOTA,不过感觉并没有和很多最新的方法比较,近两年结肠息肉的常用方法诸如PraNet,CaraNet,DoubleUNet等都没有比,还是用的DeepLabV3+这种方法进行对比,而且FPS还低很多,就emmm。不过这篇文章也比较了跨数据集的性能表现(在数据集A上训练,在数据集B上测试),而且结果还不错,看起来也是最近的方向了。
二、代码
代码我已经上传到github了,当然也可以直接在这里看。
1.引入库
import tensorflow as tf # tensorflow version 2.8.0
import keras
from keras import layers
# import tensorflow_addons as tfa
from keras.applications import resnet
'''
Unofficial tensorflow code implementation of paper "Automatic Polyp Segmentation with Multiple Kernel Dilated Convolution Network"
Paper link: https://arxiv.org/pdf/2206.06264v2.pdf
Offical pytorch code implementation: https://github.com/nikhilroxtomar/MKDCNet
I implemented the tf version code according to the official pytorch code as much as possible
'''
2.构建辅助层
class Conv2D(layers.Layer):
def __init__(self, out_c, kernel_size=3, padding='same', dilation=1, bias=False, act=True):
super().__init__()
self.act = act
self.conv = keras.models.Sequential([
layers.Conv2D(
out_c,
kernel_size=kernel_size,
padding=padding,
dilation_rate=dilation,
use_bias=bias
),
layers.BatchNormalization(),
])
self.relu = layers.Activation('relu')
def call(self, x):
x = self.conv(x)
if self.act == True:
x = self.relu(x)
return x
class ResidualBlock(layers.Layer):
def __init__(self, out_c):
super().__init__()
self.network = keras.models.Sequential([
Conv2D(out_c, kernel_size=3),
Conv2D(out_c, kernel_size=1, act=False),
])
self.shortcut = Conv2D(out_c, kernel_size=1, act=False)
self.relu = layers.Activation('relu')
def call(self, x_init):
x = self.network(x_init)
s = self.shortcut(x_init)
x = self.relu(x+s)
return x
class ChannelAttention(layers.Layer):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = layers.GlobalAveragePooling2D(keepdims=True)
self.max_pool = layers.GlobalMaxPooling2D(keepdims=True)
self.fc1 = layers.Conv2D(in_planes // ratio, 1, use_bias=False)
self.relu1 = layers.Activation('relu')
self.fc2 = layers.Conv2D(in_planes, 1, use_bias=False)
self.sigmoid = layers.Activation('sigmoid')
def call(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(layers.Layer):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
self.conv1 = layers.Conv2D(1, kernel_size, padding='same', use_bias=False)
self.sigmoid = layers.Activation('sigmoid')
def call(self, x):
avg_out = tf.reduce_mean(x, axis=-1, keepdims=True)
max_out = tf.reduce_max(x, axis=-1, keepdims=True)
x = layers.concatenate([avg_out, max_out], axis=-1)
x = self.conv1(x)
return self.sigmoid(x)
class Encoder(layers.Layer):
def __init__(self, ch, pretrained=True):
super().__init__()
'''ResNet50'''
backbone = resnet.ResNet50(
include_top=False,
weights='imagenet' if pretrained else None,
)
self.layer0 = keras.models.Model(
inputs = backbone.get_layer('conv1_pad').input,
outputs = backbone.get_layer('conv1_relu').output)
self.layer1 = keras.models.Model(
inputs = backbone.get_layer('pool1_pad').input,
outputs = backbone.get_layer('conv2_block3_out').output)
self.layer2 = keras.models.Model(
inputs = backbone.get_layer('conv3_block1_1_conv').input,
outputs = backbone.get_layer('conv3_block4_out').output)
self.layer3 = keras.models.Model(
inputs = backbone.get_layer('conv4_block1_1_conv').input,
outputs = backbone.get_layer('conv4_block6_out').output)
'''Reduce feature channels'''
self.c1 = Conv2D(ch)
self.c2 = Conv2D(ch)
self.c3 = Conv2D(ch)
self.c4 = Conv2D(ch)
def call(self, x):
'''Backbone: ResNet50'''
x0 = x
x1 = self.layer0(x0)
x2 = self.layer1(x1)
x3 = self.layer2(x2)
x4 = self.layer3(x3)
c1 = self.c1(x1)
c2 = self.c2(x2)
c3 = self.c3(x3)
c4 = self.c4(x4)
return c1, c2, c3, c4
class MultiKernelDilatedConv(layers.Layer):
def __init__(self, out_c):
super().__init__()
self.relu = layers.Activation('relu')
self.c1 = Conv2D(out_c, kernel_size=1)
self.c2 = Conv2D(out_c, kernel_size=3)
self.c3 = Conv2D(out_c, kernel_size=7)
self.c4 = Conv2D(out_c, kernel_size=11)
self.s1 = Conv2D(out_c, kernel_size=1)
self.d1 = Conv2D(out_c, kernel_size=3, dilation=1)
self.d2 = Conv2D(out_c, kernel_size=3, dilation=3)
self.d3 = Conv2D(out_c, kernel_size=3, dilation=7)
self.d4 = Conv2D(out_c, kernel_size=3, dilation=11)
self.s2 = Conv2D(out_c, kernel_size=1, act=False)
self.s3 = Conv2D(out_c, kernel_size=1, act=False)
self.ca = ChannelAttention(out_c)
self.sa = SpatialAttention()
def call(self, x):
x0 = x
x1 = self.c1(x)
x2 = self.c2(x)
x3 = self.c3(x)
x4 = self.c4(x)
x = layers.concatenate([x1, x2, x3, x4], axis=-1)
x = self.s1(x)
x1 = self.d1(x)
x2 = self.d2(x)
x3 = self.d3(x)
x4 = self.d4(x)
x = layers.concatenate([x1, x2, x3, x4], axis=-1)
x = self.s2(x)
s = self.s3(x0)
x = self.relu(x+s)
x = x * self.ca(x)
x = x * self.sa(x)
return x
class DecoderBlock(layers.Layer):
def __init__(self, out_c):
super().__init__()
self.up = layers.UpSampling2D(size=(2, 2), interpolation='bilinear')
self.r1 = ResidualBlock(out_c)
self.r2 = ResidualBlock(out_c)
def call(self, x, s):
x = self.up(x)
x = layers.concatenate([x, s], axis=-1)
x = self.r1(x)
x = self.r2(x)
return x
class MultiScaleFeatureFusion(layers.Layer):
def __init__(self, out_c):
super().__init__()
self.up_2 = layers.UpSampling2D(size=(2, 2), interpolation='bilinear')
self.c1 = Conv2D(out_c)
self.c2 = Conv2D(out_c)
# self.c3 = Conv2D(out_c)
self.c4 = Conv2D(out_c)
self.ca = ChannelAttention(out_c)
self.sa = SpatialAttention()
def call(self, f1, f2, f3):
x1 = self.up_2(f1)
x1 = self.c1(x1)
x1 = layers.concatenate([x1, f2], axis=-1)
x1 = self.up_2(x1)
x1 = self.c2(x1)
x1 = layers.concatenate([x1, f3], axis=-1)
x1 = self.up_2(x1)
x1 = self.c4(x1)
x1 = x1 * self.ca(x1)
x1 = x1 * self.sa(x1)
return x1
3.搭建网络
def build_model(input_shape=(384, 384, 1), num_classes=1, pretrained=True):
inputs = layers.Input(shape=input_shape)
s = inputs
if input_shape[-1] != 3: s = layers.Conv2D(3, 1)(inputs)
s1, s2, s3, s4 = Encoder(96, pretrained)(s)
x1 = MultiKernelDilatedConv(96)(s1)
x2 = MultiKernelDilatedConv(96)(s2)
x3 = MultiKernelDilatedConv(96)(s3)
x4 = MultiKernelDilatedConv(96)(s4)
d1 = DecoderBlock(96)(x4, x3)
d2 = DecoderBlock(96)(d1, x2)
d3 = DecoderBlock(96)(d2, x1)
x = MultiScaleFeatureFusion(96)(d1, d2, d3)
y = layers.Conv2D(num_classes, kernel_size=1)(x)
outputs = layers.Activation('sigmoid' if num_classes==1 else 'softmax')(y)
model = keras.models.Model(inputs=inputs, outputs=outputs)
return model
4.简单测试一下
if __name__ == '__main__':
input_tensor = tf.zeros((4, 384, 384, 1))
model = build_model()
model.summary()
output_tensor = model(input_tensor)
print(output_tensor.shape)
print('done')
唉,日子真的太难了。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











