






 本文介绍了DANet(DualAttentionNetwork)在场景分割中的应用,并探讨了其在医学图像分割任务上的可能性。作者分享了对DANet中位置注意力模块(PAM)和通道注意力模块(CAM)的理解,并提供了Pytorch和Keras两种实现方式的代码。尽管在实际应用中,注意力机制并未显著提升分割效果,但作者仍对注意力机制的原理和作用提出疑问。最后,作者表达了对与业界专家交流的期待。
本文介绍了DANet(DualAttentionNetwork)在场景分割中的应用,并探讨了其在医学图像分割任务上的可能性。作者分享了对DANet中位置注意力模块(PAM)和通道注意力模块(CAM)的理解,并提供了Pytorch和Keras两种实现方式的代码。尽管在实际应用中,注意力机制并未显著提升分割效果,但作者仍对注意力机制的原理和作用提出疑问。最后,作者表达了对与业界专家交流的期待。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
DANet: Dual Attention Network for Scene Segmentation(CVPR2019)
原文地址:https://arxiv.org/pdf/1809.02983.pdf
项目地址(Pytorch):https://github.com/junfu1115/DANet
其实个人对DANet理解还不是很透彻,大致上无非是通道(CAM)+空间注意力(PAM)。但是和CBAM、scSE等其它空间-通道注意力的区别在于,Daul Attention采用了类似self-attention的结构,是全局的。
最近几个月一直在自己的2D MRI数据集上尝试添加注意力机制的多类别医学图像分割方法,但是尝试了attention gate、 se、 cbam等等一箩筐的注意力机制,和基线(U-Net)相比竟然都没什么提升,整个人都处在一个怀疑人生的状态。难道注意力机制真就对当前任务没有帮助?太难顶了。
有的时候想想,注意力机制无非也是卷积、矩阵乘法、MLP的堆叠,到底是什么赋予了它们额外的特征提取的能力呢?
说回来,其实DANet的第三方实现挺多的,keras的也有,我是参考[2]的keras代码,尽可能地按照[1]的流程简单且一致地实现了一遍。
tensorflow版本建议>=2.6.0
代码参考:
[1] https://github.com/junfu1115/DANet
[2] https://blog.csdn.net/hc1104349963/article/details/109594161
[3] https://github.com/niecongchong/DANet-keras
提示:以下是本篇文章正文内容,下面案例可供参考
一、Dual Attention
原文用于场景分割,是加在Resnet底部的。医学图像分割的话,一般考虑加在编码器底部或者跳跃连接的位置吧。
别的就不多说了先,看看概览图。
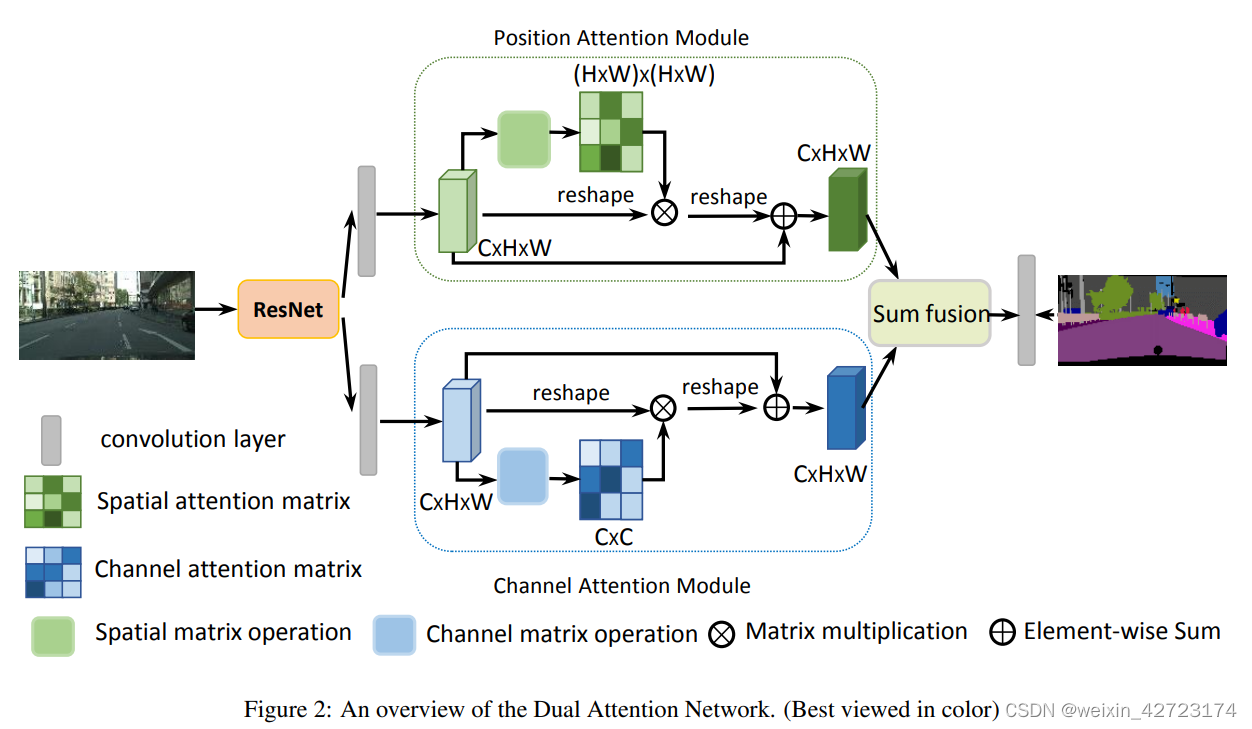
位置注意力(PAM)和通道注意力细节(CAM)
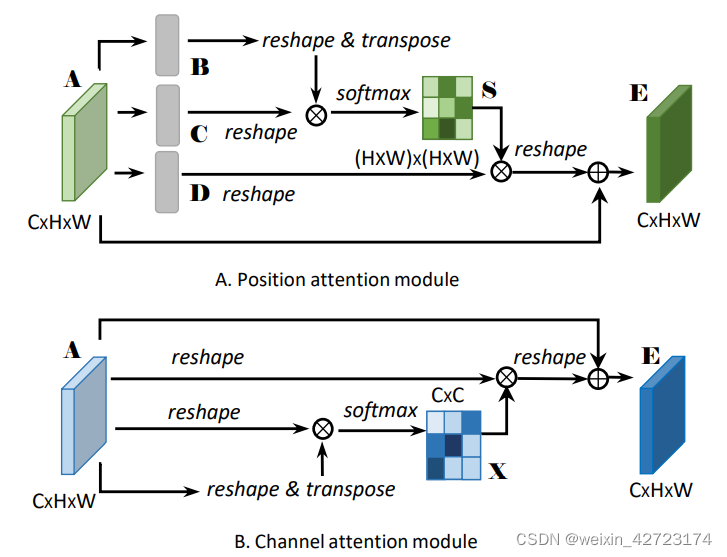
二、代码
1.PAM
代码(Pytorch):
class PAM_Module(Module):
""" Position attention module"""
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
代码(keras):
import tensorflow as tf
form keras.layers import *
def PAM_Module(x):
gamma = tf.Variable(tf.ones(1))
x_origin = x
batch_size, H, W, Channel = x.shape
proj_query = Conv2D(kernel_size=1, filters=Channel // 8, padding='same')(x)
proj_key = Conv2D(kernel_size=1, filters=Channel // 8, padding='same')(x)
proj_value = Conv2D(kernel_size=1, filters=Channel, padding='same')(x)
proj_query, proj_key, proj_value = tf.transpose(proj_query, [0, 3, 1, 2]), tf.transpose(proj_key, [0, 3, 1, 2]), tf.transpose(proj_value, [0, 3, 1, 2])
proj_key = tf.reshape(proj_key, (-1, Channel//8, H*W))
proj_query = tf.transpose(tf.reshape(proj_query, (-1, Channel//8, H*W)), [0, 2, 1])
energy = tf.matmul(proj_query, proj_key)
attention = tf.nn.softmax(energy)
proj_value = tf.reshape(proj_value, (-1, Channel, H*W))
out = tf.matmul(proj_value, tf.transpose(attention, [0, 2, 1]))
out = tf.reshape(out, (-1, Channel, H, W))
out = tf.transpose(out, [0, 2, 3, 1])
out = add([out*gamma, x_origin])
return out
2.CAM
代码(Pytorch):
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
energy = torch.bmm(proj_query, proj_key)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1)
out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
代码(keras):
def CAM_Module(x):
"""
通道注意力 Channel Attention Moudle
:param x: 输入数组[B, H, W, C]
:return: 输出数组[B, H, W, C]
"""
gamma = tf.Variable(tf.ones(1))
x_origin = x
batch_size, H, W, Channel = x.shape
x = tf.transpose(x, [0, 3, 1, 2])
proj_query = tf.reshape(x, (-1, Channel, H*W))
proj_key = tf.transpose(proj_query, [0, 2, 1])
energy = tf.matmul(proj_query, proj_key)
energy_new = tf.reduce_max(energy, axis=-1, keepdims=True)
energy_new = tf.repeat(energy_new, Channel, axis=-1)
energy_new = energy_new - energy
attention = tf.nn.softmax(energy_new)
proj_value = proj_query
out = tf.matmul(attention, proj_value)
out = tf.reshape(out, (-1, Channel, H, W))
out = tf.transpose(out, [0, 2, 3, 1])
out = add([out*gamma, x_origin])
return out
总结
感觉现在学术界用Tensorflow和keras的人比较少,代码多靠第三方复现。自己还在用tf的主要原因是比较菜,从高度封装的keras入的门。
有没有做医学图像分割的大佬或组织,介绍我认识认识TAT,救救孩子。


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











