







问题描述
设要编码的字符集为{d1, d2, …, dn},它们出现的频率为{w1, w2, …, wn},应用哈夫曼树构造最优的不等长的由0、1构成的编码方案。
问题求解
先构建以这个n个结点为叶子结点的哈夫曼树,然后由哈夫曼树产生各叶子结点对应字符的哈夫曼编码。
哈夫曼树(Huffman Tree)的定义:设二叉树具有n个带权值的叶子结点,从根结点到每个叶子结点都有一个路径长度。从根结点到各个叶子结点的路径长度与相应结点权值的乘积的和称为该二叉树的带权路径长度,记作:
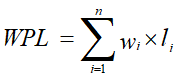
由n个叶子结点可以构造出多种二叉树,其中具有最小带权路径长度的二叉树称为哈夫曼树(也称最优树)。
构造一棵哈夫曼树的方法如下:
(1)由给定的n个权值{w1,w2,…,wn}构造n棵只有一个叶子结点的二叉树,从而得到一个二叉树的集合F={T1,T2,…,Tn}。
(2)在F中选取根结点的权值最小和次小的两棵二叉树作为左、右子树构造一棵新的二叉树,这棵新的二叉树根结点的权值为其左、右子树根结点权值之和。即合并两棵二叉树为一棵二叉树。
(3)重复步骤(2),当F中只剩下一棵二叉树时,这棵二叉树便是所要建立的哈夫曼树。
代码
int n;
struct HTreeNode
{
char data;//字符
int weight;
int parent;//双亲
int lchild;//左孩子
int rchild;//右孩子
};
HTreeNode ht[MAXN];//存放哈夫曼树
map<char, string> htcode;//存放哈夫曼编码
struct NodeType
{
int no;
char data;
int weight;
bool operator<(const NodeType &s)const
{
return weight > s.weight;
}
};
void CreateHTree()
{
NodeType e, e1, e2;
priority_queue<NodeType> qu;
for (int k = 0; k < 2 * n - 1; k++)//初始化所有的节点
ht[k].lchild = ht[k].rchild = ht[k].parent = -1;
for (int i = 0; i < n; i++)//n个节点进队
{
e.no = i;
e.data = ht[i].data;
e.weight = ht[i].weight;
qu.push(e);
}
for (int j = n; j < 2 * n - 1; j++)
{
e1 = qu.top();
qu.pop();
e2 = qu.top();
qu.pop();
ht[j].weight = e1.weight + e2.weight;
ht[j].lchild = e1.no;
ht[j].rchild = e2.no;
ht[e1.no].parent = j;
ht[e2.no].parent = j;
e.no = j;
e.weight = e1.weight + e2.weight;
qu.push(e);
}
}
void CreateHCode()
{
string code;
code.reserve(MAXN);
for (int i = 0; i < n; i++)
{
code = "";
int curno = i;
int f = ht[curno].parent;
while (f != -1)//循环到根节点
{
if (ht[f].lchild == curno)
code = '0' + code;
else
code = '1' + code;
curno = f;
f = ht[curno].parent;
}
htcode[ht[i].data] = code;
}
}
算法证明
先讨论两个命题及其证明过程。
命题1:两个最小权值字符对应的结点x和y必须是哈夫曼树中最深的两个结点且它们为兄弟。
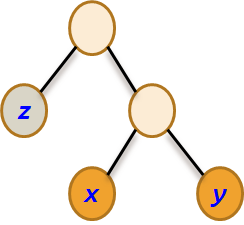
证明:假设x结点在哈夫曼树(最优树)中不是最深的,那么存在一个结点z,有wz > wx,但它比x深,即lz > lx。
此时x和z的带权和为wx×lx + wz×lz。

如果交换x和z结点的位置,其他不变
交换后的带权和为wx×lz + wz×lx。
有:wx×lz+wz×lx < wx×lx+wz×lz
这是因为 wx×lz+wz×lx - (wx×lx+wz×lz)= wx(lz-lx) - wz(lz-lx)= (wx-wz)(lz-lx) < 0
(由前面所设有wz>wx和lz>lx)。
这就与交换前的树是最优树的假设矛盾。所以上述命题成立。
命题2:设T是字符集C对应的一棵哈夫曼树,结点x和y是兄弟,它们的双亲为z,显然有wz = wx+wy,现删除结点x和y,让z变为叶子结点,那么这棵新树T1一定是字符集C1 = C - {x,y}∪{z}的最优树。

证明:设T和T1的带权路径长度分别为WPL(T)和WPL(T1),则有:WPL(T) = WPL(T1)+wx+wy
这是因为WPL(T1)含有T中除x、y外的所有叶子结点的带权路径长度和,另加上z的带权路径长度。

假设T1不是最优的,则存在另一棵树T2,有: WPL(T2) < WPL(T1)
由于z∈C1,则z在T2中一定是一个叶子结点。若将x和y加入T2中作为结点z的左、右孩子,则得到表示字符集C的前缀树T3
且有: WPL(T3) = WPL(T2)+wx+wy
由前面几个式子看到 WPL(T3) = WPL(T2)+wx + wy<WPL(T1)+wx+wy = WPL(T)
这与T为C的哈夫曼树的假设矛盾。本命题即证。
命题1说明该算法满足贪心选择性质,即通过合并来构造一棵哈夫曼树的过程可以从合并两个权值最小的字符开始。
命题2说明该算法满足最优子结构性质,即该问题的最优解包含其子问题的最优解。所以采用哈夫曼树算法产生的树一定是一棵最优树。
算法分析
上述算法采用了小根堆,因为从堆中删除两个结点(权值最小的两个二叉树根结点)和加入一个新结点的时间复杂度是O(log2n),这样修改后构造哈夫曼树算法的时间复杂度为O(nlog2n)。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









