









End-to-end Lane Shape Prediction with Transformers
这篇文章是由西安交通大学和首都师范大学合作的成果,
原论文的链接如下:https://arxiv.org/pdf/2011.04233.pdf
摘要
摘要中主要说明了以下几个问题:
(1)针对什么应用场景提出的? 这篇论文解决的是车道线检测上的车道线预测问题,在车道线偏离预警和自适应巡航控制上起到了很大的作用。
(2)有什么创新? 之前的车道线检测大多数是在二阶段方法上做的,即特征处理+后处理的步骤,但是这种方法存在两个问题:一个是很难获取车道线全局信息,一个是在车道线狭长的结构难以学习。所以本文提出的transformer模型,可以使用self attention机制来捕获细长结构和全局上下文,并且输出模型的参数还具有物理可解释性。
(3)做了什么实验? 在TuSimple数据集上进行实验,并取得了准确率的SOTA,同时是最轻量的模型,最快的速度。同时,还在自我收集的车道线数据集上进行了实验,展示其在实际应用中的强大部署潜力。
引言
挑战是什么? 车道线形状狭长,而且车道线的类型不同,遮挡情况不一样,需要利用全局信息进行预测和推断。而且在可移动设备上,算法必须具有高运行效率和迁移适应性。
以前的方法——使用基于CNN能提取车道线的特征的表征能力来提高车道线检测的性能,远远超过传统的基于霍夫变换等的手工提取特征的方式。但是这种CNN的方法仍然面临上述挑战。而在CNN基础上的变体,比如说进行分段聚类和曲线拟合的方法,这也无法解决全局信息问题;或者加入额外的场景标注等方法,在时间和数据上都造成了大的成本浪费。当然也存在一些单阶段方法,比如使用自注意力蒸馏的CNN方法,但是这种加权映射只考虑特征的重要性而限制了使用;使用目标检测pipeline法不需要分割和后处理,而是依赖于复杂的锚点设计和非极大值抑制方法,但是速度很慢;通过多项式回归方法来直接拟合,但是缺乏上下文信息所以准确度较差。
本文的方法提出将车道检测输出重构为车道形状模型的参数,每一个车道线的输出都是一组参数,这些参数通过从道路结构和相机姿态导出的显式数学公式来逼近车道线。然后使用transformer模型从视觉特征中总结信息,使其能够捕捉到细长结构和全局环境。
结论
在本研究中,我们提出一种端到端的车道检测器,它可以直接输出车道形状模型的参数。车道形状模型反映了道路结构和相机状态,增强了输出参数的可解释性。
方法
文章的方法部分从车道线形状建模、匈牙利拟合损失、模型结构三个步骤展开。
车道线形状建模:
车道形状的先验模型定义为道路上的多项式。通常,车道线近似为一条三次曲线

(X,Z)为地平面上的点,当摄像头的光轴平行于地平面时,曲线从道路投影到图片上是:
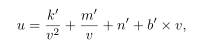
(u,v)为图片上的一个像素点。
当摄像头的光轴与地平线成一定的角度时,其公式又变为

f代表以像素为单位的焦距。
可将上式变为
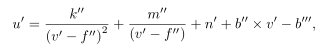
除此之外,垂直起点和终点α、 β用于参数化各车道线。这两个参数提供了描述车道线上下边界的基本定位信息线。
在实际路况中,车道通常具有全局一致的形状。因此,从左至右车道,近似圆弧的曲率相等。下面这四个参数是共享的(检测到的车道线里面的这四个参数是共享的)
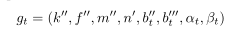
而对于不同车道线,仅在偏差项和上下边界方面有所不同(即gt后面的四个参数)。
以上公式的变换我不是很懂,有一篇博客写的很详细:
世界坐标系、图像坐标系、相机坐标系之间的变换
匈牙利损失
匈牙利拟合损失在预测和真实之间进行二部分匹配,以找出正负。匈牙利算法有效地解决了匹配问题。然后利用匹配结果对特定车道的回归损失进行优化。
本文预测N条固定的曲线(N大于典型数据集中车道线数量的最大值),预测的曲线为H,真实曲线的像素排列为s ,真实曲线为L。下面公式求的是预测曲线与真实曲线之间的距离,目标是使得距离之和最少。
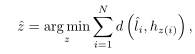

回归损失计算的是上一步匹配的所有对车道线的误差之和。

模型的结构:

上图所示的结构包括一个主干网、一个简化的transformer网络、几个用于参数预测的前馈网络和匈牙利损失计算。
对于一张输入图片,进入backbone里提取底层特征,然后平铺成一个序列S,加上位置编码Sq进入transformer的encoder层,输出一个表征序列Se,接下来,解码器生成输出序列Sd,最后,几个FFNs直接预测输出的参数。
backbone是基于一个简化的resnet18提出的,encoder和decoder都有两个标准层,每一层由自注意力+前向反馈构成。
FFNs由三个部分组成,生成预测的车道线曲线参数集。一个简单的线性操作直接将Sd投射到N × 2中,然后一个softmax层在最后一个维度对其进行操作,以得到预测标签(背景或车道)ci, i∈{1,…N}。同时,一个具有ReLU激活和隐藏维C的三层感知器将Sd投射到N × 4中,其中维4表示四组特定于lane的参数。另一个三层感知器首先将一个特征投射到N × 4,然后在第一个维度上取平均值,得到四个共享参数。
实验
在TuSimple上做的实验,是白天晴朗的高速公路上的数据集,包含6408张720×1280高分辨率图像,分成训练集(3268)、验证集(358)和测试集(2782)。
参数设置:
输入分辨率设置为360 × 640
学习速率设置为0.0001
每45k次迭代衰减10次
batch size设为16
损耗系数ω1、ω2、ω3设为3、5、2
固定预测曲线个数N设为7
训练迭代次数设为500k
并在复杂的有城市和高速公路、白天和晚上、各种交通和天气状况的数据集FVL上做了实验,52970张720 × 1280分辨率的图像。
实验结果:
本文的方法比PolyLaneNet准确率高2.82%,参数少5倍,运行速度快3.6倍。与最先进的Line-CNN方法相比,我们的准确率仅低0.69%,但运行速度比它快14倍。
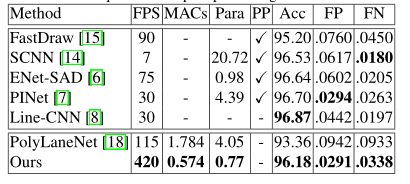
然后作者做了一些实验,实验发现三次曲线比二次曲线的效果要好,而且做了一系列消融实验。















 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









