






1、数据集拆分
拿到数据集,训练出模型,在交付实际场景之前,需要对模型的使用效果进行评价,那么就需要一部分拥有标识的数据集,而训练模型所用到的模型再进行测试的话,意义不大,因为模型就是使用这部分数据训练出来的。
所以就需要对原有数据集进行拆分,拆分方法有很多种:
1.1 经验
将数据集按照8:2的比例分为训练集和测试集,使用训练集训练出模型,用测试集进行模型测试
1.2 留出法
西瓜书第二章,将数据集分为两个互斥子集,一般将2/3~4/5的数据用于训练,剩余的用作测试。
要点:
1、划分尽量保持数据分布的一致性。
2、单次留出法得到的估计方法不可靠,一般采用若干次随机划分重复进行实验评估去平均值作为留出法的评估结果
1.3 交叉验证法
统计学习方法,S折交叉验证
将数据随机分为S个互不相交,大小相同的自己,利用S-1个数据训练,余下的数据进行测试;重复S次,最后选取S次测评中平均误差最小的模型
极端情况下,S=m
1.4 自助法
西瓜书第三章
2 模型的评价
分为两种,分类模型与回归模型
2.1 分类模型的评价
2.1.1 分类准确率
即返回被正确分类的样本比例或数量,定义清洗、计算方法比较简单。但并不一定是评价分类模型的最佳工具
2.1.2 查准率、查全率
对于数据极度偏斜的数据,仅使用分类准确度不能衡量,如预测癌症
首先引入混淆矩阵

1、TN: 预测是0,实际为0,预测对了
2、FP: 预测是1,实际为0,预测错了
3、FN: 预测是0,实际为1,预测错了
4、TP: 预测是1,实际为1,预测对了
后一个字母,P是预测正确(positive),N是预测错误(nagetive)
前一个字母,判断正确是T(true),判断错误是F(false)
套入真实场景,判断10000人是否患癌症

真反例(TN):9978人,预测为0,实际为0
假正例(FP):12人,预测为1,实际为0
假反例(FN):2人,预测为0,实际为1
真正例(TP):8人,预测为1,实际为1
查准率(精准率)即预测准确的样本占到所有预测样本的比例
precision = TP/TP+FP
查全率(召回率)即预测准确的样本找到所有准确样本的比例
recall = TP/TP+FN
2.1.3 F1 score
评价分类结果时需要在精准率与召回率之间做取舍
根据实际应用场景而定。
如:股票预测系统,注重精准率,希望系统筛选的股票中真正上涨的股票更多
医疗系统,注重查全率,希望更多的病患被筛选出来
在综合考虑查准率与查全率时,可能会想到平均值
F1score即精准率与召回率的调和平均值
什么是调和平均值,为什么使用调和平均值。
调和平均值的特点是如果两者极度不平衡,某一只特别高,某一值特别低,则调和平均值也特别低;只有两者都特别高,调和平均值才会高

2.1.4 ROC曲线
首先引入分类阈值、TPR、FPR
2.1.4.1 分类阈值
即判断样本为整理的阈值thr
精准率与召回率两个指标有内在的联系且互相冲突
precision(精准率)随thr增加而增加
recall(召回率)随thr增加而降低

2.1.4.1 TPR
TPR就是召回率,预测为1,且实际为1的样本占实际为1的样本的比例
2.1.4.2 FPR
FPR为预测为1,但预测错了的样本占真实值不为1的样本的比例。
于是有了ROC曲线,描述TPR和FPR之间的关系。x轴是FPR,y轴是TPR。
我们已经知道,TPR就是所有正例中,有多少被正确地判定为正;FPR是所有负例中,有多少被错误地判定为正。 分类阈值取不同值,TPR和FPR的计算结果也不同,最理想情况下,我们希望所有正例 & 负例 都被成功预测 TPR=1,FPR=0,即 所有的正例预测值 > 所有的负例预测值,此时阈值取最小正例预测值与最大负例预测值之间的值即可。
TPR越大越好,FPR越小越好,但这两个指标通常是矛盾的。为了增大TPR,可以预测更多的样本为正例,与此同时也增加了更多负例被误判为正例的情况。
2.1.5 AUC
一般在ROC曲线中,我们关注是曲线下面的面积, 称为AUC(Area Under Curve)。这个AUC是横轴范围(0,1 ),纵轴是(0,1)所以总面积是小于1的。
ROC和AUC的主要应用:比较两个模型哪个好?主要通过AUC能够直观看出来。
ROC曲线下方由梯形组成,矩形可以看成特征的梯形。因此,AUC的面积可以这样算:(上底+下底)* 高 / 2,曲线下面的面积可以由多个梯形面积叠加得到。AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样,模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
2.2 回归模型的评价
首先认知线性回归算法的衡量标准,通俗来讲,就是尽可能让实际值与预测值的差的平方和最小。
引入均方误差,均方根误差,平均绝对误差,R square
2.2.1 均方误差
测试集中m不同,有累加操作,随着数据的增加,误差会积累,因此衡量标准与m有关,为抵消误差,可以除去m
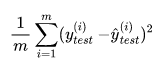
2.2.2 均方根误差
均方误差收到量纲的影响,如衡量房产是,y的单位为(万元)那么衡量结果为万元平方
为解决量纲问题,将其开方
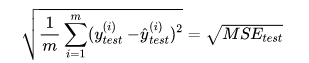
2.2.3 平均绝对误差
对于线性回归算法还有另外一种非常朴素评测标准。要求真实值 与 预测结果 之间的距离最小,可以直接相减做绝对值,加m次再除以m,即可求出平均距离,被称作平均绝对误差MAE(Mean Absolute Error):
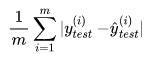
2.2.4 R square
分类准确率,就是在0~1之间取值。但RMSE和MAE没有这样的性质,得到的误差。因此RMSE和MAE就有这样的局限性,比如我们在预测波士顿方差,RMSE值是4.9(万美元) 我们再去预测身高,可能得到的误差是10(厘米),我们不能说后者比前者更准确,因为二者的量纲根本就不是一类东西。
其实这种局限性,可以被解决。用一个新的指标R Squared。
R方这个指标为什么好呢?
对于分子来说,预测值和真实值之差的平方和,即使用我们的模型预测产生的错误。
对于分母来说,是均值和真实值之差的平方和,即认为“预测值=样本均值”这个模型(Baseline Model)所产生的错误。
我们使用Baseline模型产生的错误较多,我们使用自己的模型错误较少。因此用1减去较少的错误除以较多的错误,实际上是衡量了我们的模型拟合住数据的地方,即没有产生错误的相应指标。
我们根据上述分析,可以得到如下结论:
R^2 <= 1
R2越大也好,越大说明减数的分子小,错误率低;当我们预测模型不犯任何错误时,R2最大值1
当我们的模型等于基准模型时,R^2 = 0
如果R^2 < 0,说明我们学习到的模型还不如基准模型。此时,很有可能我们的数据不存在任何线性关系。
总结:
本周学习内容主要为了解分类模型与回归模型的不同评价方式,引入概念较多,需要理解各个概念的由来,优点及局限性,了解推导过程,码代码,数据代码实现过程。















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









