








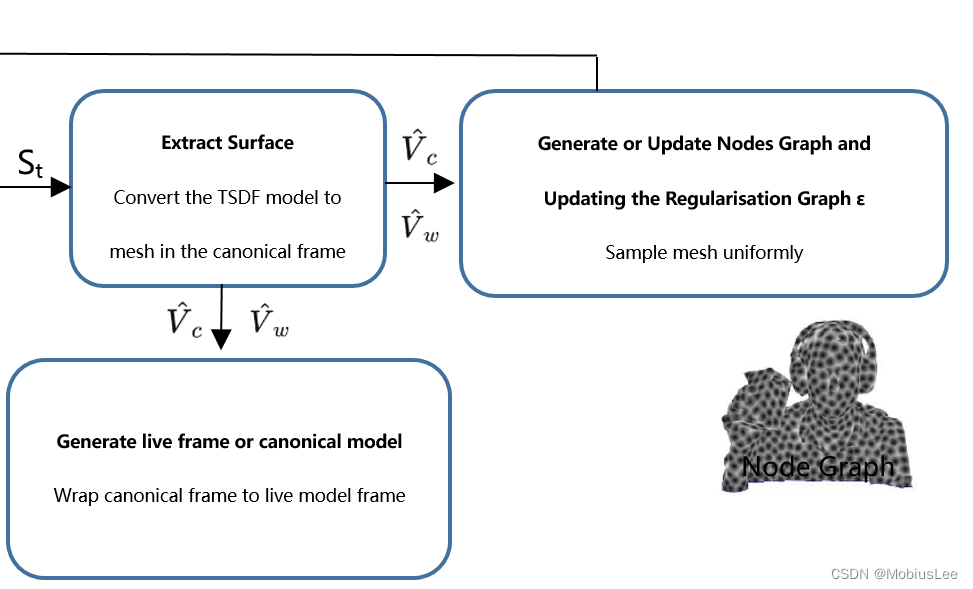


0.Overview
通过融合消费级深度摄像机扫描的RGBD图像,我们首次实现了支持非刚性形变场景的实时稠密SLAM系统。DynamicFusion能重建场景几何,同时不断估计一个密集的6维运动场,其将估计的几何结构映射到实时帧中。像KinectFusion一样,利用多种手段,我们的系统能生成不断降噪、精细化,最后完整的重建结果,同时能实时展示更新的模型。由于不需要模板或者其他先验场景模型,这个方法在移动的物体和场景中有广泛用途。
DynamicFusion将非刚性形变的场景分解为潜在的几何表面,并重构为刚性的规范空间S∈R3,每帧的体翘曲场(volumetric warp field)将该表面转化为实时帧。系统的三个核心算法组件在每个新深度帧到达时依次执行:
1.估计模型到帧的体翘曲场参数(Wrap field)
2.通过估计的翘曲场将当前帧深度图融合到规范空间(PSDF)
3.调整翘曲场结构以捕获新添加的几何特征(Update Nodes Graph)
其整体思路:首先将每帧获取到的动态变化的场景(要重建的对象)通过某种变换,转换到一个canonical model中,即在该空间中创建一个静态的物体表面模型; 而每帧都有个对应的 volumetric warp field 的东西,能够将canonical空间中的模型还原到live frame中(可想而知,这个还原过程可能经历了旋转平移和形变)。
1.Dense Non-rigid Wrap field-什么是Wrap field
先按照原文简单理解:
For each canonical point vc∈S,Tlc=W(vc) transforms that point from canonical space into the live,non-rigidly deformed frame of reference. Since we will need to estimate the warp function for each new frame,Wt,its representation must be efficiently optimisable.
这里的Tlc或W(vc)即为wrap field(是针对每个canonical点而言的),其物理含义是非刚性地(non-rigidly)将canonical model中每个点变换到live frame的相机坐标系。而对每一帧都对应一个W(t时刻:Wt)(它是所有wrap field的集合)称为wrap function,即Wt中每个值是将canonical model对应的点变换到live frame中。
2.处理第一帧图像(初始化canonical model,之后不断迭代更新)
1.由图像中每一点的深度信息和像素坐标(Input)计算相机坐标系下像素点对应的3d点初始化TSDF模型体素点St(Surface Fusion)
2.然后用PSDF(相机坐标系下求解TSDF,后面会详细讲)提取表面信息![]() 作为canonical model的初始化(Extract Surface、Generate canonical model)
作为canonical model的初始化(Extract Surface、Generate canonical model)
3.将canonical model中的vertexes进行类似的聚类操作,得到Nodes Graph,其中一个Node的表示为(t=0):(Generate Nodes Graph)
![]()
分别记录了其在canonical model中位置-dgv,其影响权重-dgw,以及其warp field-dgse3
前一帧形成的Nodes Graph就是用来计算后一帧 W 的(wrap function) 我们计算W,若是对canonical空间中的每一个点去采样,计算量过于庞大,几乎不可能做到实时构建表面。故而作者通过采样一组稀疏变换作为基础,通过对Nodes Graph插值去定义这个 W 。文中采用对偶四元数混合插值法(dual-quaternion bleding DQB)来定义 wrap field 从而构成wrap function :
4.用dual-quaternion bleding DQB(对偶四元数混合插值法)计算每一个体素xc的Wrap field:
W(xc)≡SE3(DQB(xc))
注意:这里的W(xc)并不是我们最后的结果,这里的SE(3)可以理解为校正物体运动和形变的矩阵,随后还有处理模型其他刚性变换(例如相机位姿)的矩阵。
![]()
这里的![]() 为单位对偶四元数(可有nodes的dgse3转化得到);N(xc)为对于点 xc 的 k 个最临近nodes,Wk为权重,用于调整对应节变化的影响(径向)范围,具体计算:
为单位对偶四元数(可有nodes的dgse3转化得到);N(xc)为对于点 xc 的 k 个最临近nodes,Wk为权重,用于调整对应节变化的影响(径向)范围,具体计算:
![]() i就是上式的k
i就是上式的k
5.故我们的wrap function,还包括了除了物体形变外的另一个刚性变换(因为上述步骤都没考虑刚性变换,上面注意中也提了),例如把物体从canonical空间转换到相机空间的变换,把其他所有刚性变换记为Tlw,则最终的 wrap function应该为(t=0)(Estimating the wrap field):
![]()
故我们对于第一帧的进行算法步骤是:Surface Fusion、Extract Surface、Generate canonical model、Generate Nodes Graph、Estimating the wrap field(并不是先开始的Estimating the wrap field,不同于后面帧,也可以理解为第一帧的Wt为“1”)
3. Dense Non-Rigid Surface Fusion
第一帧处理结束,我们进入正常的算法流程。
我们先介绍Surface Fusion,所以我们这一步是基于本帧的Wt已经在算法上一步Estimating the wrap field中求出的情况下。
同Kinect-Fusion,在Dynamic-Fusion中我们的canonical model也是用TSDF表示(每个x对应于V(x)→[v(x)∈R,w(x)∈R],其中v(x)表示TSDF值,w(x)表示权值),但是他的计算求解过程不在同于我们的标准TSDF的求解法,而是引入了一种称为Projective TSDF的方法,其实原理和TSDF里的是一样的,不同的在于我们这里是在相机坐标系进行的,而TSDF里的是在世界坐标系,详细请看我的TSDF和PSDF区别一文。详细步骤如下:
1.在时刻t,将canonical model中的每个体素中心xc通过Wt(算法流程上一步求的),转换到实时相机坐标系(live frame)中:
![]()
2.PSDF:
![]()
其中 [·]z 表示该表面点的深度值;
减号右边表示cannonical model中体素投影到live frame在相机坐标系下的深度值;
减号左边表示xt反投影回成像平面对应的像素点再投影到Surface对应的表面点信息,即:
![]()
为什么不像Kinect-Fusion里那样在世界坐标系下求解TSDF值?文中给予的说法是:
This allows the TSDF for a point in the canonical frame to be updated by computing the projective TSDF in the deforming frame(live frame 实时帧) without having to resample a warped TSDF in the live frame.
即这样的好处是,不用每一帧都去重采样新的TSDF体素,重构新的TSDF并提取新的Surface,而是将caninical frame里的直接用Wt 变换过来,对其进行迭代跟新就行了,减小了计算量。
3.上面求出的psdf值,还没结束,不是用它直接去更新TSDF模型,因为还没对其进行截断和权值修饰,这部分基本同Kinect-Fusion,具体如下:
![]()
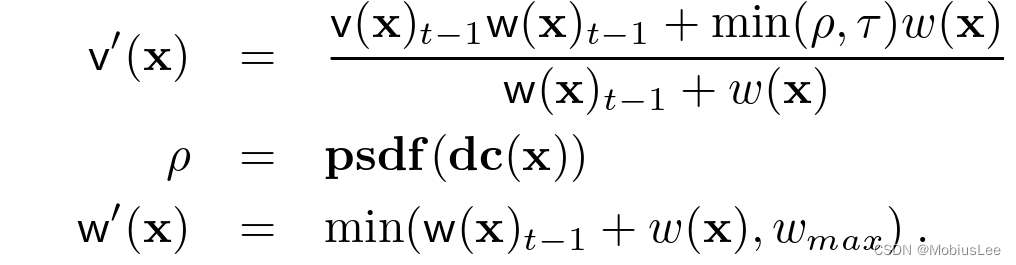
其中[![]() ]对应的就是我们本帧求得的TSDF更新值,就是下一帧对应于上述式子中的
]对应的就是我们本帧求得的TSDF更新值,就是下一帧对应于上述式子中的![]() 和
和![]()
另外dc(.) : transforms a discrete voxel point intothe continuous TSDF domain.The truncation distance τ>0(不太懂)
与kinect-fusion对w(x)赋值不同的是:
![]()
![]()
原文给予的解释:Unlike the static fusion scenario where the weight w(x) encodes the uncertainty of the depth value observed at the projected pixel in the depth frame,we also account for uncertainty associated with the warp function at xc. In the case of the single rigid transformation in original TSDF fusion,we are certain that observed surface regions,free space,and unobserved regions transform equivalently. our non-rigid case,the further away the point xc is from an already mapped and observable surface region,the less certain we can be about its transformation.
即不像我们静态重建一样,我们权值是对深度不确定的度量,因为静态重建中我们对于观察表面区域是确定的,而在动态重建中我们的权值还需要再对xc 的wrap function进行度量,因为在动态重建中,我们xc离已经了观察和映射的cononical model中的体素点越远,我们约不确定xc的变换
4. Extract Surface、Generate canonical model、Generate live frame
关于怎么在TSDF模型中提取表面信息原理和Kinect-Fusion中无太大区别,从TSDF模型中提取出零水平集存储为点法对作为Surface也就是我们的canonical model:
![]()
Generate canonical model就是在第一帧的时候将TSDF模型提取出来的表面点信息![]() 转化成mesh格式,并在后续帧中不断的迭代优化
转化成mesh格式,并在后续帧中不断的迭代优化
Generate live frame则是依据Wt (wrap field function)将canonical model(![]() )转化到实时帧(live frame)中:
)转化到实时帧(live frame)中:
![]()
5. Estimating the wrap field(Wt)
![]()
求解Wt和Kinect-Fusion中求解相机位姿的原理都是用的ICP,但在我们Dynamic-Fusion中的误差项由两部分构成:
1.Dense Non-Rigid ICP Data-term
2.a regularisation term Reg(Wt, ε) that penalises non-smooth motion fields,and ensures as-rigid-as-possible deformation between transformation nodes connected by the edge set ε
5.1 Dense Non-Rigid ICP Data-term
这里的V是当前的重建的模型表面。Data()是model-to-frame的ICP cost function,直观理解可能要做个差,具体怎么构建这个cost function就是下面我们讨论的内容:
1. 将![]() 渲染到图像空间下,记为 Ω ,这样就获取了我们所预测出来的模型可见区域(currently predicted to be visible)。意思就是说,如果按照 Wt 变换后,那么当前帧下我们看到的应当就是这个 Ω 图像;
渲染到图像空间下,记为 Ω ,这样就获取了我们所预测出来的模型可见区域(currently predicted to be visible)。意思就是说,如果按照 Wt 变换后,那么当前帧下我们看到的应当就是这个 Ω 图像;
2. 这里的可见区域图像 Ω 中,像素 u 对应的canonical中的体素点就是在实时空间下预测出来的可见的点,该体素点记为 v(u) 。可以看到,这实际上是一个匹配点的筛选过程;
3.在Wt中得到对应于v(u)的变换:
![]()
所以预测到的canonical model在实时帧中的可见部分对应的点法对为:
![]()
![]()
而深度图映射出的对应相机空间下的点 vl(u) 方法为(我们有Wt变换过的点法对,再知道由我们实时帧的深度图求得的点法对,通过两者求个loss就是Data)
![]() (*)
(*)
4.则我们的Data项表示如下:
![]()
其中:
![]()
![]() 就是按照公式(*)计算得到的
就是按照公式(*)计算得到的
![]() 它是一个鲁棒回归方法,定义为:
它是一个鲁棒回归方法,定义为:
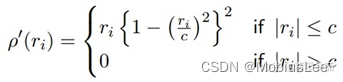
5.2 Wrap Field Regularization
以上我们约束的都是当前可见区域的点,那么对于canonical空间中,那些当前不可见的点就没有以上描述的关联约束了,意味着缺失了一些数据,而当前缺失的那些数据,可能在随后的帧中,作为新观察到的数据出现。如何去为那些当前看不到的节点添加约束呢?为变形节点之间添加类似一个边约束,然后作为整体的cost加到能量方程里去。并用Huber Penalty (ψreg() )构建:
![]()
αij是一个描述点 i 和 j 之间构成的边所对应的权重,有 αij=max(dgwi,dgwj) 。
Huber Penalty定义:
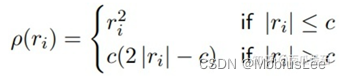
这里的 ρ 指的就是 ψreg。
很显然,理解这个公式的关键是这里出现的新参数 ε,它指连接分级变形节点之间的边集。前面有说到,对于当前帧观测不到的点,怎么去建立约束,文中提出通过对每一帧变形节点集Nwrap 的更新,去构建一个层级正则节点集,记为: Nreg={rv,rse3,rw} ,当level为0,即是 Nwrap本身 ,那么这个边集 ε 就是从level为0(即Nwrap 本身中的点)开始,到其k个最邻近的下个level(即 Nreg )中的点连接所形成的边。
知道了 ε,如何构建并更新这个Nreg?继续往下看。
6. Update Nodes Graph Nwrap and Updating the Regularisation Graph ε
6.1 Update Nodes Graph Nwrap
由于每一帧的变化, Nwrap 是保持持续更新的,总会由新的变形节点加入到其中,对于当前帧中,不支持的物体表面顶点(本帧没有观察到的canonical model中的表面点),按照 ϵ (这和我们的边集ε不一样!)的距离为半径进行采样得到的点集![]() ,DBQ混合初始化后与上一帧的形变点集合并就是新的Nwrap:
,DBQ混合初始化后与上一帧的形变点集合并就是新的Nwrap:
![]()
6.2 Updating the Regularisation Graph ε
Nreg 实际上是对当前形变点集 ![]() 的二次采样,采样半径为:
的二次采样,采样半径为:![]() ,即ϵ和
,即ϵ和![]() 相乘,其中β是参数>1(表示总层级数),l表示当前层级。
相乘,其中β是参数>1(表示总层级数),l表示当前层级。
所以这里的边集 ε 就是开始于level = 0 的点到 level = 1的最邻近k个点构成的边,重复至完成所有层级间边的添加。
原论文:
参考:
DynamicFusion: Reconstruction and Tracking of Non-rigid scenes in real-time
本文若有错误或疏漏之处,请批评指正















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









