







step 1:下载猫狗图片数据集
1.数据集链接:cats and dogs

下载完成的文件夹名为PetImages,共25000张照片(猫12500,狗12500),注:因为数据集原因,在数据集cat子目录下的666.jpg和数据集dog子目录下的11702.jpg是无法显示的,需要你从网上随便找张猫的图片替换666.jps和一张狗的图片替换11702.jpg(图片尺寸无限制)!!
2.然后进行下一步重要的处理-分割训练集和验证集(或称作测试集):
在你的本地PetImages目录下新建train文件夹,将原先的cat、dog文件夹剪切进tarin,然后在train同级目录创建validation文件夹,再在validation内创建两个新的文件夹-cat和dog,架构如图:
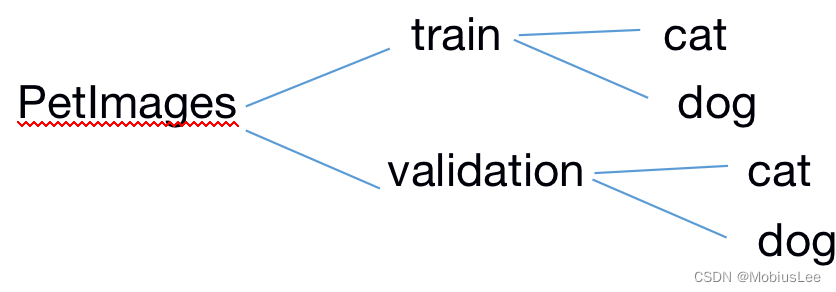
然后运行脚本(8:2划分训练集和验证集):
import os, shutil
import random
def mymovefile(srcfile, dstfile):
if not os.path.isfile(srcfile):
print("src not exist!")
else:
fpath, fname = os.path.split(dstfile) # 分离文件名和路径
if not os.path.exists(fpath):
os.makedirs(fpath) # 创建路径
shutil.move(srcfile, dstfile) # 移动文件
test_rate = 0.2 # 训练集和测试集的比例为8:2。
img_num = 12500 #猫和狗分别都是12500张
test_num = int(img_num * test_rate)
test_index = random.sample(range(0, img_num), test_num)
# print(test_index)
file_path = "//Users//Administrator//Desktop//Projects//ResNet//data"
tr = "train"
te = "validation"
cat = "cat"
dog = "dog"
# 将上述index中的文件都移动到/test/Cat/和/test/Dog/下面去。
for i in range(len(test_index)):
# 移动猫
srcfile = os.path.join(file_path, tr, cat, str(test_index[i]) + ".jpg")
# print(srcfile)
dstfile = os.path.join(file_path, te, cat, str(test_index[i]) + ".jpg")
mymovefile(srcfile, dstfile)
# 移动狗
srcfile = os.path.join(file_path, tr, dog, str(test_index[i]) + ".jpg")
# print(srcfile)
dstfile = os.path.join(file_path, te, dog, str(test_index[i]) + ".jpg")
mymovefile(srcfile, dstfile)然后猫和狗的各12500张照片中的随机各2500张照片就会被分配到validation目录下的cat、dog文件夹中用于后续测试验证。
step 2:训练网络&测试网络
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models
from torch.autograd import Variable
# 设置超参数
BATCH_SIZE = 16
EPOCHS = 10
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 数据预处理
transforms = transforms.Compose([
transforms.RandomResizedCrop(150),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 读取数据
dataset_train = datasets.ImageFolder('data/train', transforms)
dataset_test = datasets.ImageFolder('data/val', transforms)
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
modellr = 1e-4
# 实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
model = torchvision.models.resnet18(pretrained=False) # ****
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
model.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model.parameters(), lr=modellr)
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
modellrnew = modellr * (0.1 ** (epoch // 50))
print("lr:", modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print('epoch:{},loss:{}'.format(epoch, ave_loss))
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
# 训练
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model, DEVICE, train_loader, optimizer, epoch)
val(model, DEVICE, test_loader)
torch.save(model, 'model.pth')训练完成可能需要耗费一段时间,在我的机器上最后测试准确率大概为83%














 3445
3445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









