







基于Darknet深度学习框架训练YoloV4模型,并用自己的模型批量处理图片并保存在文件夹内
参考文章链接:
linux下配置运行YoloV4
准备Pascal VOC数据集
训练配置并开始训练
感谢大佬提供的训练方法!!!
训练YoloV4
本机系统环境
Centos8
显卡 GeForce RTX 2080 8G显存
显卡驱动版本440.82
CUDA 10.2
Cudnn 7.6.2
OpenCV 3.4.1
Python 3.7
配置运行测试YoloV4
- 下载YoloV4
git clone https://github.com/AlexeyAB/darknet.git - 编译
在darknet-master目录下打开命令行,输入:
make
PS:以下两种情况都要重新编译,重新编译步骤就是先make clean,再make
情况一 修改使用GPU、Cudnn、OpenCV等,这些内容在/darknet-master/makefile里面修改,使用设为1,不使用设为0
情况二 后期训练修改/darknet-master/src文件夹里的文件时,如/darknet-master/src/detector.c - 测试是否编译成功
./darknet
如果出现下面输出则为成功:
usage:./darknet<fuction>
- 下载YoloV4权重文件
YoloV4权重文件(需要外网)
没有外网可以留言邮箱地址
下载好后将权重文件yolov4.weights复制到/darknet-master目录下 - 测试实例
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg
如果没有使用OpenCV的话只会保存结果图片在/darknet-master目录下,使用的话会出现弹窗显示检测结果。
准备Pascal VOC数据集
- 标注
标注我使用的精灵标注,导出pascal voc格式数据
注意不要有超出图片边界的框,也不要有想xmin=0或者ymin=0的框 - 处理数据
- 按以下格式创建目录:
darknet-master
VOCdevkit
VOC2028
Annotations
JPEGImages
ImageSets
Main
注意Main文件夹在ImageSets文件夹内
- 整理数据
将所有图片放入JPEGImages文件夹中,将所有.xml标注文件放入Annotations文件夹中,然后运行
python Main_devide.py ./VOCdevkit/VOC2028
Main_devide.py内容如下:
import os
import random
import sys
if len(sys.argv) < 2:
print("no directory specified, please input target directory")
exit()
root_path = sys.argv[1]
xmlfilepath = root_path + '/Annotations'
txtsavepath = root_path + '/ImageSets/Main'
if not os.path.exists(root_path):
print("cannot find such directory: " + root_path)
exit()
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
trainval_percent = 0.9
train_percent = 0.8
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size:", tv)
print("train size:", tr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
在ImageSets/Main文件夹下就会生成四个txt文件:test.txt、train.txt、trainval.txt、val.txt。
- 生成Darknet需要的label文件
将/darknet-master/scripts目录下的voc_label.py文件复制到/darknet-master目录下,打开voc_label.py文件,修改第7行:
sets=[('2012', 'train'),('2012', 'val'),('2007', 'train'),('2007', 'val'),('2007', 'test')]
改为
sets=[('2028', 'train'),('2028', 'val'),('2028', 'test')]
修改第8行:
classes=["你自己要训练的类别","逗号隔开"]
修改最后两行:
os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
改为
os.system("cat 2028_train.txt 2028_val.txt > train.txt")
os.system("cat 2028_train.txt 2028_val.txt 2007_test.txt > train.all.txt")
运行voc_label.py文件:
python voc_label.py
运行后,在/darknet目录下会生成5个文件,分别是:2028_train.txt,2028_test.txt,2028_val.txt,train.all.txt,train.txt
将这5个txt文件复制到/darknet/VOCdevkit中
修改配置并开始训练
- 修改配置文件cfg/voc.data
classes=20
train=/home/xxx/xxx/train.txt
valid=/home/xxx/xxx/2007_test.txt
names=data/voc.names
backup=backup
修改成:
classes=x #你的类别数
train=/home/xxx/xxx/darknet-master/VOCdevkit/train.txt
valid=/home/xxx/xxx/darknet-master/VOCdevkit/2028_test.txt
names=data/voc.names
backup=/home/xxx/xxx/darknet-master/backup #在darknet-master目录下创建backup文件夹
- 修改data/voc.names
将里面的内容修改为训练的类别名,一个类型一行 - 下载backbone权重文件yolov4.conv.137
https://drive.google.com/file/d/1JKF-bdIklxOOVy-2Cr5qdvjgGpmGfcbp/view
将该文件放在/darknet-master目录下
- 修改配置文件yolo-obj.cfg
将cfg/yolov4-custom.cfg复制一份,并将复制后的文件命名为yolo-obj.cfg
修改/darknet-master/cfg/yolo-obj.cfg,如下:
将batch和subdivisions前面的#删掉
batch和subdivisions大小可按自己显存大小修改,数据都是2的倍数
width和height都修改为416,或者其他32的倍数
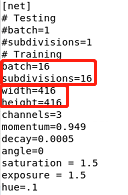
修改max_batches和steps:
max_batches=类别数量×2000
steps=0.8×max_batches,0.9×max_batches
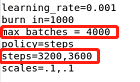
ctrl+F搜索yolo,一共出现三处,修改yolo上面的fliters和下面的classes:
fliters=(类别数+5)×3
classes=类别数

- 开始训练
./darknet detector train cfg/voc.data cfg/yolo-obj.cfg yolov4.conv.137
训练结束后,训练的模型会放在darknet-master/backup中。
PS:训练时碰到一个issue
mosaic=1 -compile Darknet with OpenCV for using mosaic=1
free():corrupted unsorted chunks段错误
此问题github作者已解决段错误(核心已转储)
- 测试训练的模型
./darknet detector test cfg/voc.data cfg/yolo-obj.cfg backup/yolo-obj_xxxx.weights
批量处理图片并保存在文件夹内
训练完模型后,在实际运用自己训练的模型时,希望能实现批量处理,并且将检测结果显示在图片上并将结果图片保存在指定文件夹中。
代码修改
- 修改darknet-master/src/detector.c文件
打开darknet-master/src/detector.c文件,添加*GetFilename(char *p)函数,如下:
#include "darknet.h"
#include <sys/stat.h>
#include<stdio.h>
#include<time.h>
#include<sys/types.h>
static int coco_ids[] = {1,2,3,4,5,6,7,8,9,10,11,13,14,15,16,17,18,19,20,21,22,23,24,25,27,28,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,67,70,72,73,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90};
char *GetFilename(char *p)
{
static char name[20]={""};
char *q = strrchr(p,'/') + 1;
strncpy(name,q,3); #这里3是文件名长度,比如001.jpg,要修改成你自己的文件名长度,文件名不统一的话可以通过文件名修改软件修改成统一的,这一点是比较鸡肋,凑合用吧
return name;
}
搜索“save_image(im, “predictions”)”,大概在1600多行,将其替换为以下代码:
// save_image(im, "predictions");
char b[512];
sprintf(b,"output/%s", GetFilename(input));
save_image(im, b);
修改完后重新make。
准备一个包含所有需要检测图片路径的txt文件
运行以下代码(路径改为自己的):
import os
paths = "./test" # 测试图片的路径
f = open('test.txt', 'w') # 最后得到的图片路径txt文件
filenames = os.listdir(paths)
filenames.sort()
for filename in filenames:
out_path = "/home/yolov4/darknet-master/test/" + filename # 引号内为测试图片文件夹的绝对路径
print(out_path)
f.write(out_path + '\n')
f.close()
运行完后在darknet-master目录下会生成一个test.txt文件。
在cmd下用指令运行
在darknet-master目录下创建一个output文件夹,运行以下命令:
./darknet detector test <data/voc.data> <cfg/yolo-voc.cfg> <yolo-voc.weights> -ext_output -dont_show < <data/train.txt> > <result.txt>
其中用“< >”尖括号框出来的地方需要修改:
data/voc.data:检测用模型的voc.data文件的地址。
cfg/yolo-voc.cfg:检测用模型的cfg文件的地址。
yolo-voc.weights:检测用模型的weights文件的地址。
data/train.txt :步骤2中准备的txt文件地址。ps:注意前后有’< ‘和’ >'
result.txt:输出文本格式的检测结果的文件名
我的运行命令如下:
./darknet detector test data/voc.data cfg/yolo-obj.cfg backup/yolo-obj_xxxx.weights -ext_output -dont_show test.txt result.txt
用自己的模型检测视频并保存
请见另一篇文章CentOS8编译OpenCV4.3.0 with ffmpeg(YoloV4处理视频并保存)
以上。















 4309
4309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









