






文章目录
Atomic
原子类操作。
JUC中多数类是通过volatile和CAS来实现的,CAS本质上提供的是一种无锁方案,而Synchronized和Lock是互斥锁方案; java原子类本质上使用的是CAS,而CAS底层是通过Unsafe类实现的。所以本章将对CAS, Unsafe和原子类详解。 @pdai
CAS
CAS的全称为Compare-And-Swap,直译就是对比交换。是一条CPU的原子指令,其作用是让CPU先进行比较两个值是否相等,然后原子地更新某个位置的值,经过调查发现,其实现方式是基于硬件平台的汇编指令,就是说CAS是靠硬件实现的,JVM只是封装了汇编调用,那些AtomicInteger类便是使用了这些封装后的接口。 简单解释:CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下在旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。
CAS操作是原子性的,所以多线程并发使用CAS更新数据时,可以不使用锁。JDK中大量使用了CAS来更新数据而防止加锁(synchronized 重量级锁)来保持原子更新。
相信sql大家都熟悉,类似sql中的条件更新一样:update set id=3 from table where id=2。因为单条sql执行具有原子性,如果有多个线程同时执行此sql语句,只有一条能更新成功。
CAS存在问题
- ABA问题
大致就是在操作比较前,那个值就恢复了,所以有ABA这种问题。
- 循环时间长开销大
毕竟CAS通过是通过自旋+CAS比较+volatile进行操作,所以存在空转问题。可以通过pause指令进行缓解。
- 只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i = 2,j = a,合并一下ij = 2a,然后用CAS来操作ij。
从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作
Unsafe
Unsafe提供的API大致可分为内存操作、CAS、Class相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类。
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
cmpxchg(void* ptr, int old, int new),如果ptr和old的值一样,则把new写到ptr内存,否则返回ptr的值,整个操作是原子的。在Intel平台下,会用lock cmpxchg来实现,使用lock触发缓存锁,这样另一个线程想访问ptr的内存,就会被block住。
AtomicInterger
//unsafe class
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var4));
return var5;
}
第一个是对象,字段偏移,旧值,新值。
getIntVolatile方法获取对象中offset偏移地址对应的整型field的值,支持volatile load语义。
//AtomocInterger class
public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
LockSupport
核心
在分析LockSupport函数之前,先引入sun.misc.Unsafe类中的park和unpark函数,因为LockSupport的核心函数都是基于Unsafe类中定义的park和unpark函数,下面给出两个函数的定义:
public native void park(boolean isAbsolute, long time);
public native void unpark(Thread thread);
park函数,阻塞线程,并且该线程在下列情况发生之前都会被阻塞: ① 调用unpark函数,释放该线程的许可。② 该线程被中断。③ 设置的时间到了。并且,当time为绝对时间时,isAbsolute为true,否则,isAbsolute为false。当time为0时,表示无限等待,直到unpark发生。
unpark函数,释放线程的许可,即激活调用park后阻塞的线程。这个函数不是安全的,调用这个函数时要确保线程依旧存活
说明: 调用了park函数后,会禁用当前线程,除非许可可用。在以下三种情况之一发生之前,当前线程都将处于休眠状态,即下列情况发生时,当前线程会获取许可,可以继续运行。
- 其他某个线程将当前线程作为目标调用 unpark。
- 其他某个线程中断当前线程。
- 该调用不合逻辑地(即毫无理由地)返回
class MyThread extends Thread {
public void run() {
synchronized (this) {
System.out.println("before notify");
notify();
System.out.println("after notify");
}
}
}
public class WaitAndNotifyDemo {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
synchronized (myThread) {
try {
myThread.start();
// 主线程睡眠3s
Thread.sleep(3000);
System.out.println("before wait");
// 阻塞主线程
myThread.wait();
System.out.println("after wait");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
把这个记录下来是因为比较震惊执行顺序,后来才明白,是首先主线程有锁,锁住了对象,然后对象执行才能执行,然后知道mythread的wait,阻塞线程,将对象锁释放了,所以才执行了synchronizd内部的操作,然后恢复了线程,把锁拿回来了。
AQS
这个应该非常重要,JDK锁的实现方式。
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配
AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
资源共享方式
AQS定义两种资源共享方式
- Exclusive(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
- Share(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
AQS 数据结构
AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。其中Sync queue,即同步队列,是双向链表,包括head结点和tail结点,head结点主要用作后续的调度。而Condition queue不是必须的,其是一个单向链表,只有当使用Condition时,才会存在此单向链表。并且可能会有多个Condition queue。
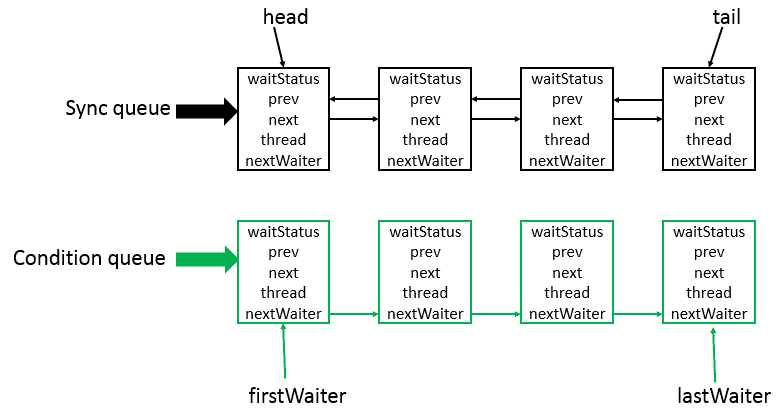
Node
static final class Node {
// 模式,分为共享与独占
// 共享模式
static final Node SHARED = new Node();
// 独占模式
static final Node EXCLUSIVE = null;
// 结点状态
// CANCELLED,值为1,表示当前的线程被取消
// SIGNAL,值为-1,表示当前节点的后继节点包含的线程需要运行,也就是unpark
// CONDITION,值为-2,表示当前节点在等待condition,也就是在condition队列中
// PROPAGATE,值为-3,表示当前场景下后续的acquireShared能够得以执行
// 值为0,表示当前节点在sync队列中,等待着获取锁
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
// 结点状态
volatile int waitStatus;
// 前驱结点
volatile Node prev;
// 后继结点
volatile Node next;
// 结点所对应的线程
volatile Thread thread;
// 下一个等待者
Node nextWaiter;
// 结点是否在共享模式下等待
final boolean isShared() {
return nextWaiter == SHARED;
}
// 获取前驱结点,若前驱结点为空,抛出异常
final Node predecessor() throws NullPointerException {
// 保存前驱结点
Node p = prev;
if (p == null) // 前驱结点为空,抛出异常
throw new NullPointerException();
else // 前驱结点不为空,返回
return p;
}
// 无参构造方法
Node() { // Used to establish initial head or SHARED marker
}
// 构造方法
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
// 构造方法
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
------
著作权归@pdai所有
原文链接:https://pdai.tech/md/java/thread/java-thread-x-lock-AbstractQueuedSynchronizer.html
核心方法
acquire
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
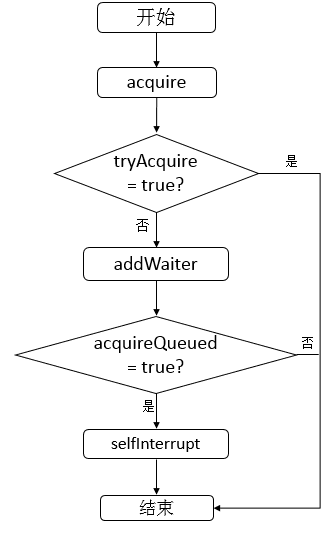
-
首先调用tryAcquire方法,调用此方法的线程会试图在独占模式下获取对象状态。此方法应该查询是否允许它在独占模式下获取对象状态,如果允许,则获取它。在AbstractQueuedSynchronizer源码中默认会抛出一个异常,即需要子类去重写此方法完成自己的逻辑。之后会进行分析。
-
若tryAcquire失败,则调用addWaiter方法,addWaiter方法完成的功能是将调用此方法的线程封装成为一个结点并放入Sync queue。
-
调用acquireQueued方法,此方法完成的功能是Sync queue中的结点不断尝试获取资源,若成功,则返回true,否则,返回false。
-
由于tryAcquire默认实现是抛出异常,所以此时,不进行分析,之后会结合一个例子进行分析。
final boolean acquireQueued(final Node node, int arg) {
// 标志
boolean failed = true;
try {
// 中断标志
boolean interrupted = false;
for (;;) { // 无限循环
// 获取node节点的前驱结点
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { // 前驱为头节点并且成功获得锁
setHead(node); // 设置头节点
p.next = null; // help GC
failed = false; // 设置标志
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
acquireQueued逻辑
-
判断结点的前驱是否为head并且是否成功获取(资源)。
-
若步骤1均满足,则设置结点为head,之后会判断是否finally模块,然后返回。
-
若步骤2不满足,则判断是否需要park当前线程,是否需要park当前线程的逻辑是判断结点的前驱结点的状态是否为SIGNAL,若是,则park当前结点,否则,不进行park操作。
-
若park了当前线程,之后某个线程对本线程unpark后,并且本线程也获得机会运行。那么,将会继续进行步骤①的判断。
release方法
public final boolean release(int arg) {
if (tryRelease(arg)) { // 释放成功
// 保存头节点
Node h = head;
if (h != null && h.waitStatus != 0) // 头节点不为空并且头节点状态不为0
unparkSuccessor(h); //释放头节点的后继结点
return true;
}
return false;
}
ReentrantLock
可重入锁,很重要。
sync
NonfairSync
从lock方法的源码可知,每一次都尝试获取锁,而并不会按照公平等待的原则进行等待,让等待时间最久的线程获得锁。
FairSyn
static final class FairSync extends Sync {
// 版本序列化
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
// 以独占模式获取对象,忽略中断
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
// 尝试公平获取锁
protected final boolean tryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 状态为0
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) { // 不存在已经等待更久的线程并且比较并且设置状态成功
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { // 状态不为0,即资源已经被线程占据
// 下一个状态
int nextc = c + acquires;
if (nextc < 0) // 超过了int的表示范围
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
return true;
}
return false;
}
}
从实现来说,如果有前驱节点就选择退让锁,让其他人取获得。它总是会先判断sync队列(AbstractQueuedSynchronizer中的数据结构)是否有等待时间更长的线程,如果存在,则将该线程加入到等待队列的尾部,实现了公平获取原则。说明: 可以看出只要资源被其他线程占用,该线程就会添加到sync queue中的尾部,而不会先尝试获取资源。这也是和Nonfair最大的区别,Nonfair每一次都会尝试去获取资源,如果此时该资源恰好被释放,则会被当前线程获取,这就造成了不公平的现象,当获取不成功,再加入队列尾部。
ReentrantReadWriteLock
Sync类内部存在两个内部类,分别为HoldCounter和ThreadLocalHoldCounter,其中HoldCounter主要与读锁配套使用,其中,HoldCounter源码如下。
static final class HoldCounter {
// 计数
int count = 0;
// Use id, not reference, to avoid garbage retention
// 获取当前线程的TID属性的值
final long tid = getThreadId(Thread.currentThread());
}
count和tid,其中count表示某个读线程重入的次数,tid表示该线程的tid字段的值,该字段可以用来唯一标识一个线程。
abstract static class Sync extends AbstractQueuedSynchronizer {
// 版本序列号
private static final long serialVersionUID = 6317671515068378041L;
// 高16位为读锁,低16位为写锁
static final int SHARED_SHIFT = 16;
// 读锁单位
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 读锁最大数量
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 写锁最大数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 本地线程计数器
private transient ThreadLocalHoldCounter readHolds;
// 缓存的计数器
private transient HoldCounter cachedHoldCounter;
// 第一个读线程
private transient Thread firstReader = null;
// 第一个读线程的计数
private transient int firstReaderHoldCount;
}
说明: 该属性中包括了读锁、写锁线程的最大量。本地线程计数器等。类的构造函数// 构造函数
Sync() {
// 本地线程计数器
readHolds = new ThreadLocalHoldCounter();
// 设置AQS的状态
setState(getState()); // ensures visibility of readHolds
}
直接将state右移16位,就可以得到读锁的线程数量,因为state的高16位表示读锁,对应的低十六位表示写锁数量。
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }//读锁计算数目
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }//写锁计算数目
写锁部分
tryRelease: 此函数用于释放写锁资源,首先会判断该线程是否为独占线程,若不为独占线程,则抛出异常,否则,计算释放资源后的写锁的数量,若为0,表示成功释放,资源不将被占用,否则,表示资源还被占用。
tryAcquire逻辑:
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
// 写线程数量
int w = exclusiveCount(c);
if (c != 0) { // 状态不为0
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread()) // 写线程数量为0或者当前线程没有占有独占资源
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT) // 判断是否超过最高写线程数量
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
// 设置AQS状态
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires)) // 写线程是否应该被阻塞
return false;
// 设置独占线程
setExclusiveOwnerThread(current);
return true;
}
说明: 此函数用于获取写锁,首先会获取state,判断是否为0,若为0,表示此时没有读锁线程,再判断写线程是否应该被阻塞,而在非公平策略下总是不会被阻塞,在公平策略下会进行判断(判断同步队列中是否有等待时间更长的线程,若存在,则需要被阻塞,否则,无需阻塞),之后在设置状态state,然后返回true。若state不为0,则表示此时存在读锁或写锁线程,若写锁线程数量为0或者当前线程为独占锁线程,则返回false,表示不成功,否则,判断写锁线程的重入次数是否大于了最大值,若是,则抛出异常,否则,设置状态state,返回true,表示成功。
读锁逻辑
protected final int tryAcquireShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current) // 写线程数不为0并且占有资源的不是当前线程
return -1;
// 读锁数量
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) { // 读线程是否应该被阻塞、并且小于最大值、并且比较设置成功
if (r == 0) { // 读锁数量为0
// 设置第一个读线程
firstReader = current;
// 读线程占用的资源数为1
firstReaderHoldCount = 1;
} else if (firstReader == current) { // 当前线程为第一个读线程
// 占用资源数加1
firstReaderHoldCount++;
} else { // 读锁数量不为0并且不为当前线程
// 获取计数器
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
// 获取当前线程对应的计数器
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0) // 计数为0
// 设置
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
首先判断不存在写锁,然后首先判断写锁是否为0并且当前线程不占有独占锁,直接返回;否则,判断读线程是否需要被阻塞并且读锁数量是否小于最大值并且比较设置状态成功,若当前没有读锁,则设置第一个读线程firstReader和firstReaderHoldCount;若当前线程线程为第一个读线程,则增加firstReaderHoldCount;否则,将设置当前线程对应的HoldCounter对象的值。
读锁释放资源
protected final boolean tryReleaseShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
if (firstReader == current) { // 当前线程为第一个读线程
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1) // 读线程占用的资源数为1
firstReader = null;
else // 减少占用的资源
firstReaderHoldCount--;
} else { // 当前线程不为第一个读线程
// 获取缓存的计数器
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
// 获取当前线程对应的计数器
rh = readHolds.get();
// 获取计数
int count = rh.count;
if (count <= 1) { // 计数小于等于1
// 移除
readHolds.remove();
if (count <= 0) // 计数小于等于0,抛出异常
throw unmatchedUnlockException();
}
// 减少计数
--rh.count;
}
for (;;) { // 无限循环
// 获取状态
int c = getState();
// 获取状态
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc)) // 比较并进行设置
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
此函数表示读锁线程释放锁。首先判断当前线程是否为第一个读线程firstReader,若是,则判断第一个读线程占有的资源数firstReaderHoldCount是否为1,若是,则设置第一个读线程firstReader为空,否则,将第一个读线程占有的资源数firstReaderHoldCount减1;若当前线程不是第一个读线程,那么首先会获取缓存计数器(上一个读锁线程对应的计数器 ),若计数器为空或者tid不等于当前线程的tid值,则获取当前线程的计数器,如果计数器的计数count小于等于1,则移除当前线程对应的计数器,如果计数器的计数count小于等于0,则抛出异常,之后再减少计数即可。无论何种情况,都会进入无限循环,该循环可以确保成功设置状态state。
锁降级
public void processData() {
readLock.lock();
if (!update) {
// 必须先释放读锁
readLock.unlock();
// 锁降级从写锁获取到开始
writeLock.lock();
try {
if (!update) {
// 准备数据的流程(略)
update = true;
}
readLock.lock();
} finally {
writeLock.unlock();
}
// 锁降级完成,写锁降级为读锁
}
try {
// 使用数据的流程(略)
} finally {
readLock.unlock();
}
}
锁降级中读锁的获取是否必要呢? 答案是必要的。主要是为了保证数据的可见性,如果当前线程不获取读锁而是直接释放写锁,假设此刻另一个线程(记作线程T)获取了写锁并修改了数据,那么当前线程无法感知线程T的数据更新。如果当前线程获取读锁,即遵循锁降级的步骤,则线程T将会被阻塞,直到当前线程使用数据并释放读锁之后,线程T才能获取写锁进行数据更新。
ConcurrentHashMap
看完脑子要炸掉了,gggg。
1.7还是很容易的毕竟只是桶内进行同步操作,1.8直接宕机。
version 1.8
首先我还没弄清这个,但是我觉得弄清这个但先清楚几个关键变量
fwd标志位,如果处理过的数据就是将其设置为标志位。标志位的hash值为MOVED也就是-1,就可以确定这个桶已经完成扩容了。
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
sc
//第一条扩容线程设置的某个特定基数
U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
//后续线程加入扩容大军时每次加 1
U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)
//线程扩容完毕退出扩容操作时每次减 1
U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)
作用:sizeCtl 用于记录当前扩容的并发线程数情况,此时 sizeCtl 的值为:((rs << RESIZE_STAMP_SHIFT) + 2) + (正在扩容的线程数) ,并且该状态下 sizeCtl < 0 。
transfer源码。
能够知道的时他第一次进入必定是null,这个时候确定的transferIndex,然后从后往前通过stride来分配任务。bound 指向了 transferIndex-stride,也就是完成位置。简单理解结局: i 指向了 transferIndex,bound 指向了 transferIndex-stride。可以理解为第一个bound在分配边界任务。
那么在扩容时sizeCtl值的意义:高15位为容量n ,低16位为并行扩容线程数+1。其他地方如果碰到了sizeCtl为复数,说明正在扩容,就需要线程帮助。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16
// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,
// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 如果 nextTab 为 null,先进行一次初始化
// 前面我们说了,外围会保证第一个发起迁移的线程调用此方法时,参数 nextTab 为 null
// 之后参与迁移的线程调用此方法时,nextTab 不会为 null
if (nextTab == null) {
try {
// 容量翻倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable 是 ConcurrentHashMap 中的属性
nextTable = nextTab;
// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
/*
* 下面这个 for 循环,最难理解的在前面,而要看懂它们,应该先看懂后面的,然后再倒回来看
*
*/
// i 是位置索引,bound 是边界,注意是从后往前
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 下面这个 while 真的是不好理解
// advance 为 true 表示可以进行下一个位置的迁移了
// 简单理解结局: i 指向了 transferIndex,bound 指向了 transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// 将 transferIndex 值赋给 nextIndex
// 这里 transferIndex 一旦小于等于 0,说明原数组的所有位置都有相应的线程去处理了
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// 看括号中的代码,nextBound 是这次迁移任务的边界,注意,是从后往前
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// 所有的迁移操作已经完成
nextTable = null;
// 将新的 nextTab 赋值给 table 属性,完成迁移
table = nextTab;
// 重新计算 sizeCtl: n 是原数组长度,所以 sizeCtl 得出的值将是新数组长度的 0.75 倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,
// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 任务结束,方法退出
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,
// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 该位置处是一个 ForwardingNode,代表该位置已经迁移过了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 对数组该位置处的结点加锁,开始处理数组该位置处的迁移工作
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// 头节点的 hash 大于 0,说明是链表的 Node 节点
if (fh >= 0) {
// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,
// 需要将链表一分为二,
// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的
// lastRun 之前的节点需要进行克隆,然后分到两个链表中
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 其中的一个链表放在新数组的位置 i
setTabAt(nextTab, i, ln);
// 另一个链表放在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
else if (f instanceof TreeBin) {
// 红黑树的迁移
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果一分为二后,节点数小于等于6,那么将红黑树转换回链表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 将 ln 放置在新数组的位置 i
setTabAt(nextTab, i, ln);
// 将 hn 放置在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
}
}
}
}
}
1.7 version
时真的累,1.7采用的方式不用于1.8的数组链表红黑树。采用segment+数组。这样就可以多线程进行,segment不可以变化,其他的扩容都是基于segment内的。
插入过程如下。先上锁。
这个方法有两个出口,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
tryLock() ? null :scanAndLockForPut(key, hash, value)就是看似复杂,但是其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往该 segment 写入前,需要先获取该 segment 的独占锁
// 先看主流程,后面还会具体介绍这部分内容
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 这个是 segment 内部的数组
HashEntry<K,V>[] tab = table;
// 再利用 hash 值,求应该放置的数组下标
int index = (tab.length - 1) & hash;
// first 是数组该位置处的链表的表头
HashEntry<K,V> first = entryAt(tab, index);
// 下面这串 for 循环虽然很长,不过也很好理解,想想该位置没有任何元素和已经存在一个链表这两种情况
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// 覆盖旧值
e.value = value;
++modCount;
}
break;
}
// 继续顺着链表走
e = e.next;
}
else {
// node 到底是不是 null,这个要看获取锁的过程,不过和这里都没有关系。
// 如果不为 null,那就直接将它设置为链表表头;如果是null,初始化并设置为链表表头。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果超过了该 segment 的阈值,这个 segment 需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 扩容后面也会具体分析
else
// 没有达到阈值,将 node 放到数组 tab 的 index 位置,
// 其实就是将新的节点设置成原链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 解锁
unlock();
}
return oldValue;
}
ThreadLocal
本地线程
总结而言:ThreadLocal是一个将在多线程中为每一个线程创建单独的变量副本的类; 当使用ThreadLocal来维护变量时, ThreadLocal会为每个线程创建单独的变量副本, 避免因多线程操作共享变量而导致的数据不一致的情况。
self总的来说就是一个变量多次出现,可能需要贯穿单个线程的整体时刻,但是又不想浪费锁资源去处理它。
原理
这个本质上是一个全局map,key为线程,value则是各自储存。
所以就是全局map的增删改查。
ThreadLocal造成内存泄露的问题
如果用线程池来操作ThreadLocal 对象确实会造成内存泄露, 因为对于线程池里面不会销毁的线程, 里面总会存在着<ThreadLocal, LocalVariable>的强引用, 因为final static 修饰的 ThreadLocal 并不会释放, 而ThreadLocalMap 对于 Key 虽然是弱引用, 但是强引用不会释放, 弱引用当然也会一直有值, 同时创建的LocalVariable对象也不会释放, 就造成了内存泄露; 如果LocalVariable对象不是一个大对象的话, 其实泄露的并不严重, 泄露的内存 = 核心线程数 * LocalVariable对象的大小;
所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法
线程池
futureTask
FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务(cancel)等。如果任务尚未完成,获取任务执行结果时将会阻塞。一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。FutureTask 的线程安全由CAS来保证。
属性
//内部持有的callable任务,运行完毕后置空
private Callable<V> callable;
//从get()中返回的结果或抛出的异常
private Object outcome; // non-volatile, protected by state reads/writes
//运行callable的线程
private volatile Thread runner;
//使用Treiber栈保存等待线程
private volatile WaitNode waiters;
//任务状态
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
run方法
public void run() {
//新建任务,CAS替换runner为当前线程
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);//设置执行结果
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);//处理中断逻辑
}
}
ThreadPoolExecutor
why
线程池能够对线程进行统一分配,调优和监控:
- 降低资源消耗(线程无限制地创建,然后使用完毕后销毁)
- 提高响应速度(无须创建线程)
- 提高线程的可管理性
如何进行
从JDK 5开始,把工作单元与执行机制分离开来,工作单元包括Runnable和Callable,而执行机制由Executor框架提供。
其实java线程池的实现原理很简单,说白了就是一个线程集合workerSet和一个阻塞队列workQueue。当用户向线程池提交一个任务(也就是线程)时,线程池会先将任务放入workQueue中。workerSet中的线程会不断的从workQueue中获取线程然后执行。当workQueue中没有任务的时候,worker就会阻塞,直到队列中有任务了就取出来继续执行
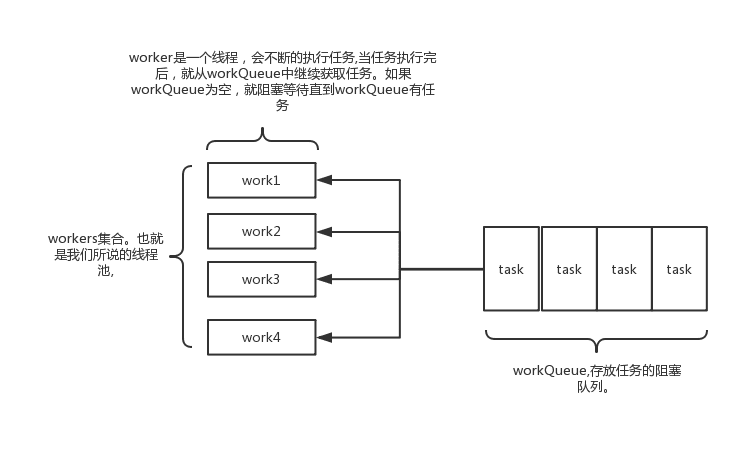
execute原理
当一个任务提交至线程池之后:
- 线程池首先当前运行的线程数量是否少于corePoolSize。如果是,则创建一个新的工作线程来执行任务。如果都在执行任务,则进入2.
- 判断BlockingQueue是否已经满了,倘若还没有满,则将线程放入BlockingQueue。否则进入3.
- 如果创建一个新的工作线程将使当前运行的线程数量超过maximumPoolSize,则交给RejectedExecutionHandler来处理任务。
当ThreadPoolExecutor创建新线程时,通过CAS来更新线程池的状态ctl.
关键参数
- 核心数目corePoolSize
- 最大数目线程数maximumPoolSize
- workQueue工作缓存队列
流程是先判断count小于1,直接允许,否则看wordQueue数目,如果workQueue数目满了,则判断是否超过2的数目,在决定是否扩容。
小demo
public class SimpleThreadPool {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
Runnable worker = new WorkerThread("" + i);
executor.execute(worker);
}
executor.shutdown(); // This will make the executor accept no new threads and finish all existing threads in the queue
while (!executor.isTerminated()) { // Wait until all threads are finish,and also you can use "executor.awaitTermination();" to wait
}
System.out.println("Finished all threads");
}
}
三种策略
- newFixedThreadPool
- newSingleThreadExecutor
- newCachedThreadPool
代码分析
execute()方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
//workerCountOf获取线程池的当前线程数;小于corePoolSize,执行addWorker创建新线程执行command任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// double check: c, recheck
// 线程池处于RUNNING状态,把提交的任务成功放入阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// recheck and if necessary 回滚到入队操作前,即倘若线程池shutdown状态,就remove(command)
//如果线程池没有RUNNING,成功从阻塞队列中删除任务,执行reject方法处理任务
if (! isRunning(recheck) && remove(command))
reject(command);
//线程池处于running状态,但是没有线程,则创建线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 往线程池中创建新的线程失败,则reject任务
else if (!addWorker(command, false))
reject(command);
}
addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
// CAS更新线程池数量
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 线程池重入锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 线程启动,执行任务(Worker.thread(firstTask).start());
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
线程启动之后,通过unlock方法释放锁,设置AQS的state为0,表示运行可中断;
Worker执行firstTask或从workQueue中获取任务:
- 进行加锁操作,保证thread不被其他线程中断(除非线程池被中断)
- 检查线程池状态,倘若线程池处于中断状态,当前线程将中断。
- 执行beforeExecute
- 执行任务的run方法
- 执行afterExecute方法
- 解锁操作
getTask
获取work queue中的任务。
allowCoreThreadTimeOut为false,线程即使空闲也不会被销毁;倘若为ture,在keepAliveTime内仍空闲则会被销毁。
如果线程允许空闲等待而不被销毁timed == false,workQueue.take任务: 如果阻塞队列为空,当前线程会被挂起等待;当队列中有任务加入时,线程被唤醒,take方法返回任务,并执行;
如果线程不允许无休止空闲timed == true, workQueue.poll任务: 如果在keepAliveTime时间内,阻塞队列还是没有任务,则返回null;
为什么线程池不允许使用Executors去创建? 推荐方式是什么?
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors各个方法的弊端:
- newFixedThreadPool和newSingleThreadExecutor: 主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
- newCachedThreadPool和newScheduledThreadPool: 主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM
美团学习部分
线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ThreadPoolExecutor的运行状态有5种,分别为:

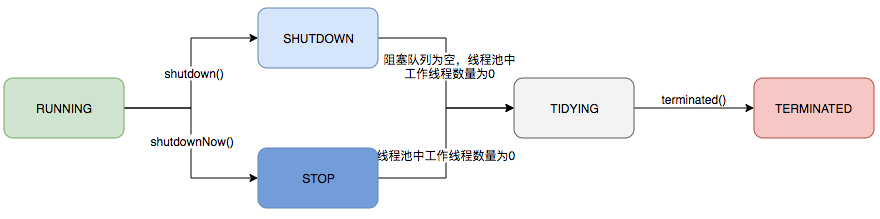 运行可中断;
运行可中断;
Worker执行firstTask或从workQueue中获取任务:
- 进行加锁操作,保证thread不被其他线程中断(除非线程池被中断)
- 检查线程池状态,倘若线程池处于中断状态,当前线程将中断。
- 执行beforeExecute
- 执行任务的run方法
- 执行afterExecute方法
- 解锁操作
getTask
获取work queue中的任务。
allowCoreThreadTimeOut为false,线程即使空闲也不会被销毁;倘若为ture,在keepAliveTime内仍空闲则会被销毁。
如果线程允许空闲等待而不被销毁timed == false,workQueue.take任务: 如果阻塞队列为空,当前线程会被挂起等待;当队列中有任务加入时,线程被唤醒,take方法返回任务,并执行;
如果线程不允许无休止空闲timed == true, workQueue.poll任务: 如果在keepAliveTime时间内,阻塞队列还是没有任务,则返回null;
为什么线程池不允许使用Executors去创建? 推荐方式是什么?
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors各个方法的弊端:
- newFixedThreadPool和newSingleThreadExecutor: 主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
- newCachedThreadPool和newScheduledThreadPool: 主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM
美团学习部分
线程池内部使用一个变量维护两个值:运行状态(runState)和线程数量 (workerCount)。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ThreadPoolExecutor的运行状态有5种,分别为:















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









