






python使用TensorRT引擎
安装pycuda (注意和自己的python和cuda版本匹配)
F:\Python38\python.exe F:\Python38\Scripts\pip.exe install pycuda -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install pycuda -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装tensorrt
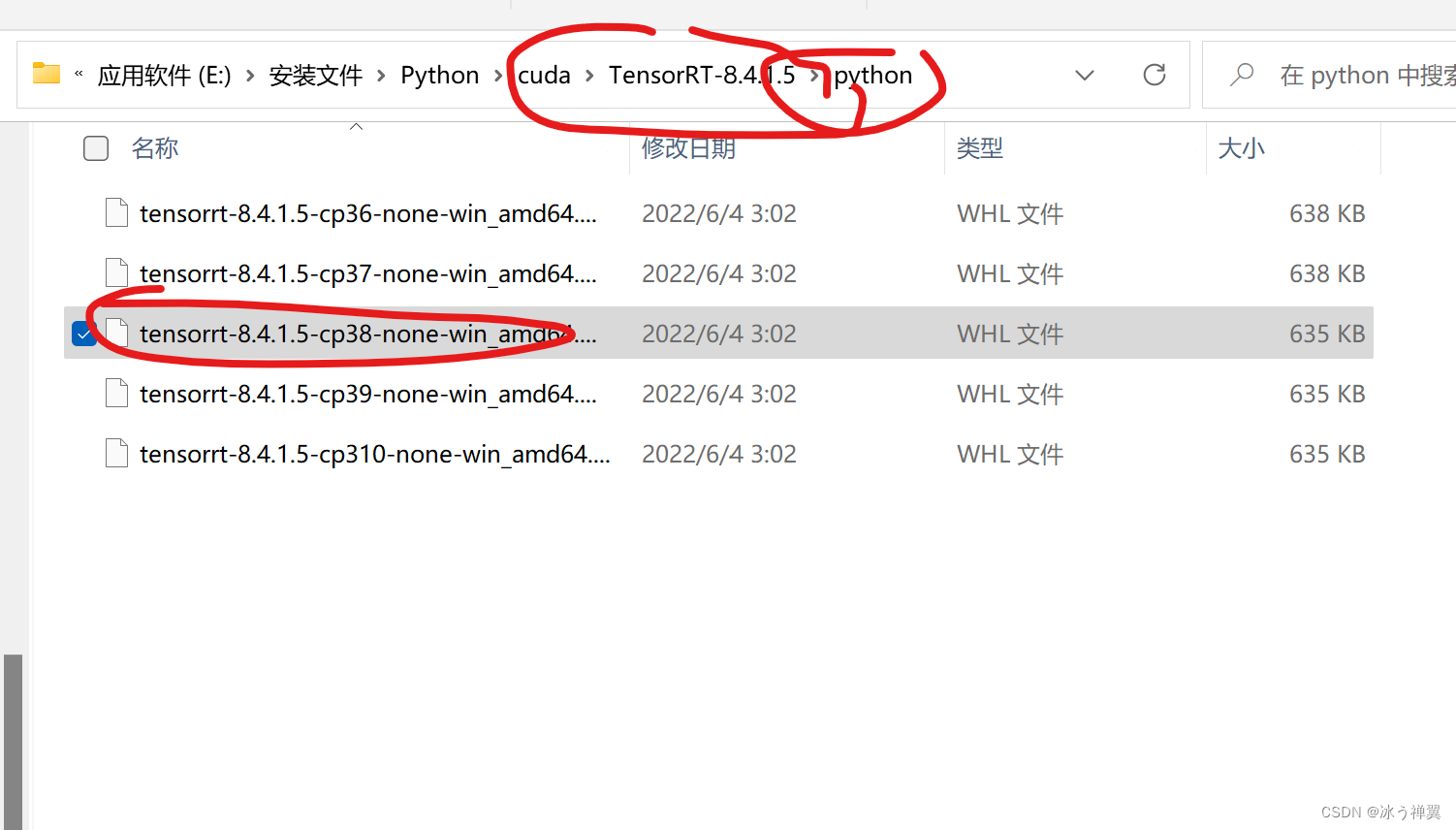
pip install E:\安装文件\Python\cuda\TensorRT-8.4.1.5\python\tensorrt-8.4.1.5-cp38-none-win_amd64.whl
把tensorrt库放到环境变量里
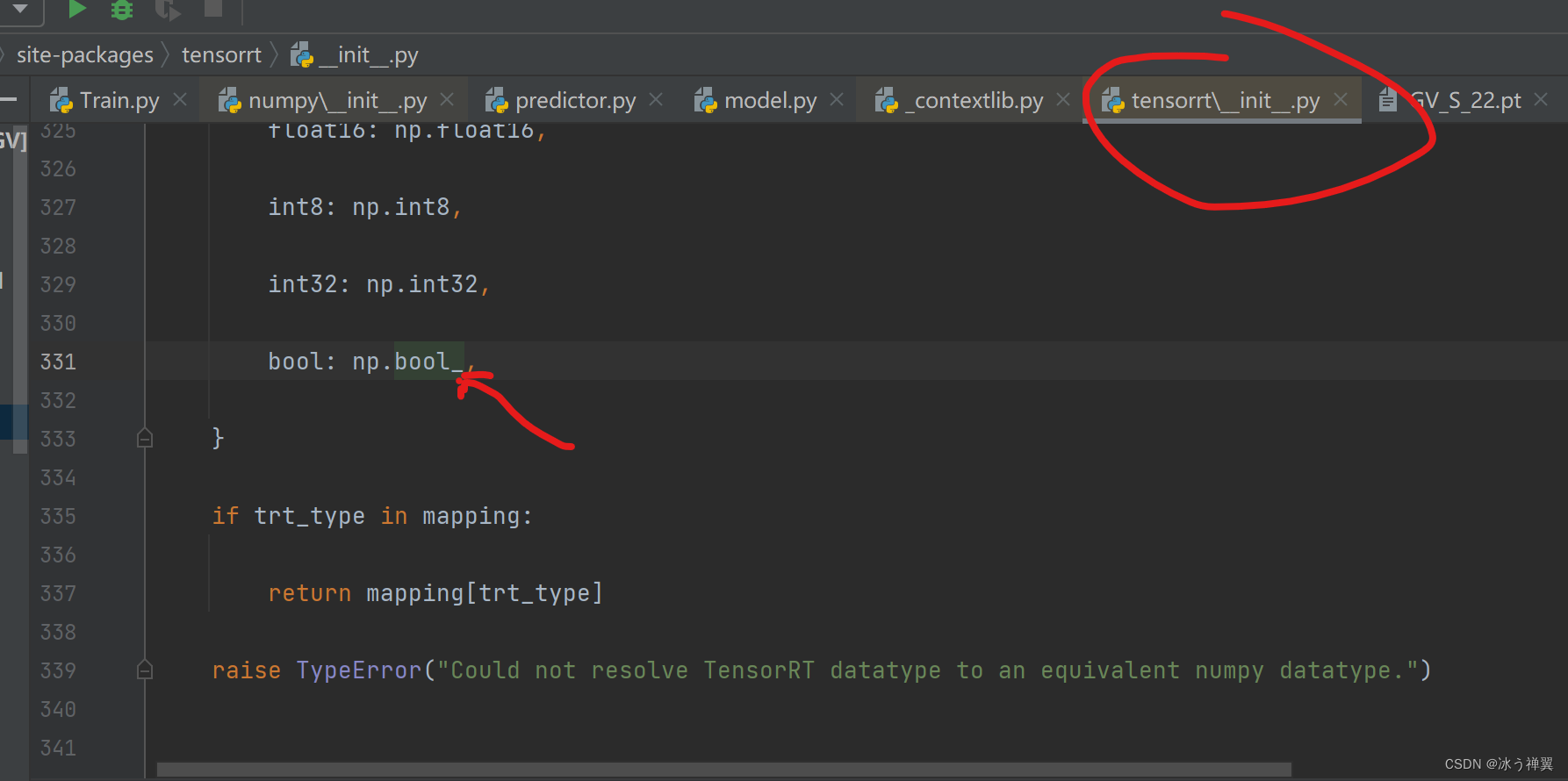
如果安装了最新版numpy,需要修改bool为bool_
# import time
# from ultralytics.yolo.engine.model import YOLO
from ultralytics import YOLO
import cv2
if __name__ == '__main__':
# from ultralytics import YOLO
# import threading
# open_train = threading.Thread(target=test_train)
# open_train.start()
#
# print_train = threading.Thread(target=test_predict)
# print_train.start()
# 1 加载模型
# model = YOLO(r'D:\ACC_AI\python_GV_20230722\test_m\GV\weights\best.pt')
# model = YOLO(r'yolov8s.pt')
model = YOLO(r'D:\AI_AOI\GV\Python\python_GV_20230725\test_m\GV_S_22.engine')
# 2 训练模型
# model.train(data='GV.yaml', epochs=9999, imgsz=450, batch=12, workers=0, project="./test_m", name="GV",
# patience=100,
# rect=True, #原图模式,去掉以后就是拼接模式。优先拼接模式训练到不能提升,再用原图模式训练10轮
# exist_ok=True)
#
img = cv2.imread(r"F:\Python_Dataset\GVIMAGES_Data\josn_20\train\images\20230710175650502_7.jpg")
res = model.predict(source=img,imgsz=(224,480),device=0)
print(res)
# #
# # 坐标
# xy_xy = result1.boxes.cpu().numpy().xyxy
# # 类别
# cls = result1.boxes.cpu().numpy().cls # Masks object for segmentation masks outputs
# # 置信度
# conf = result1.boxes.cpu().numpy().conf # Class probabilities for classification outputs
#
model.export(format='engine',imgsz=(224,480),dynamic=True,device=0)
支持多图输入的导出
dynamic=True :表示dynamic axes,即表示可以任意多图输入模型引擎中
model.export(format='engine',dynamic=True,imgsz=(480,224),device=0)















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









