






文章目录
一、降维算法介绍
sklearn中降维算法都被包括在模块decomposition中,这个模块本质是一个矩阵分解模块。在过去的十年中,如果要讨论算法进步的先锋,矩阵分解可以说是独树一帜。矩阵分解可以用在降维,深度学习,聚类分析,数据预处理,低纬度特征学习,推荐系统,大数据分析等领域。
SVD和主成分分析PCA都属于矩阵分解算法中的入门算法,都是通过分解特征矩阵来进行降维,它们也是我们今天要讲解的重点。虽然是入门算法,却不代表PCA和SVD简单:下面两张图是我在一篇SVD的论文中随意截取的两页,可以看到满满的数学公式(基本是线性代数)。要想在短短的一个小时内,给大家讲明白这些公式,我讲完不吐血大家听完也吐血了。所以今天,我会用最简单的方式为大家呈现降维算法的原理,但这注定意味着大家无法看到这个算法的全貌,在机器学习中逃避数学是邪道,所以更多原理大家自己去阅读。
二、 PCA与SVD
在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
上周的特征工程课中,我们提到过一种重要的特征选择方法:方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。
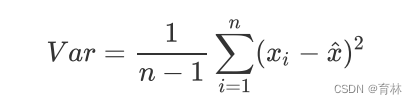
Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,xhat代表这一列样本的均值。
PCA和特征选择技术都是特征工程的一部分,它们有什么不同?
特征工程中有三种方式:特征提取,特征创造和特征选择。仔细观察上面的降维例子和上周我们讲解过的特征选择,你发现有什么不同了吗? 特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,我们依然知道这个特征在原数据的哪个位置,代表着原数据上的什么含义。而PCA,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。以PCA为代表的降维算法因此是特征创造(feature creation,或feature construction)的一种。
可以想见,PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。
1、重要参数n_components
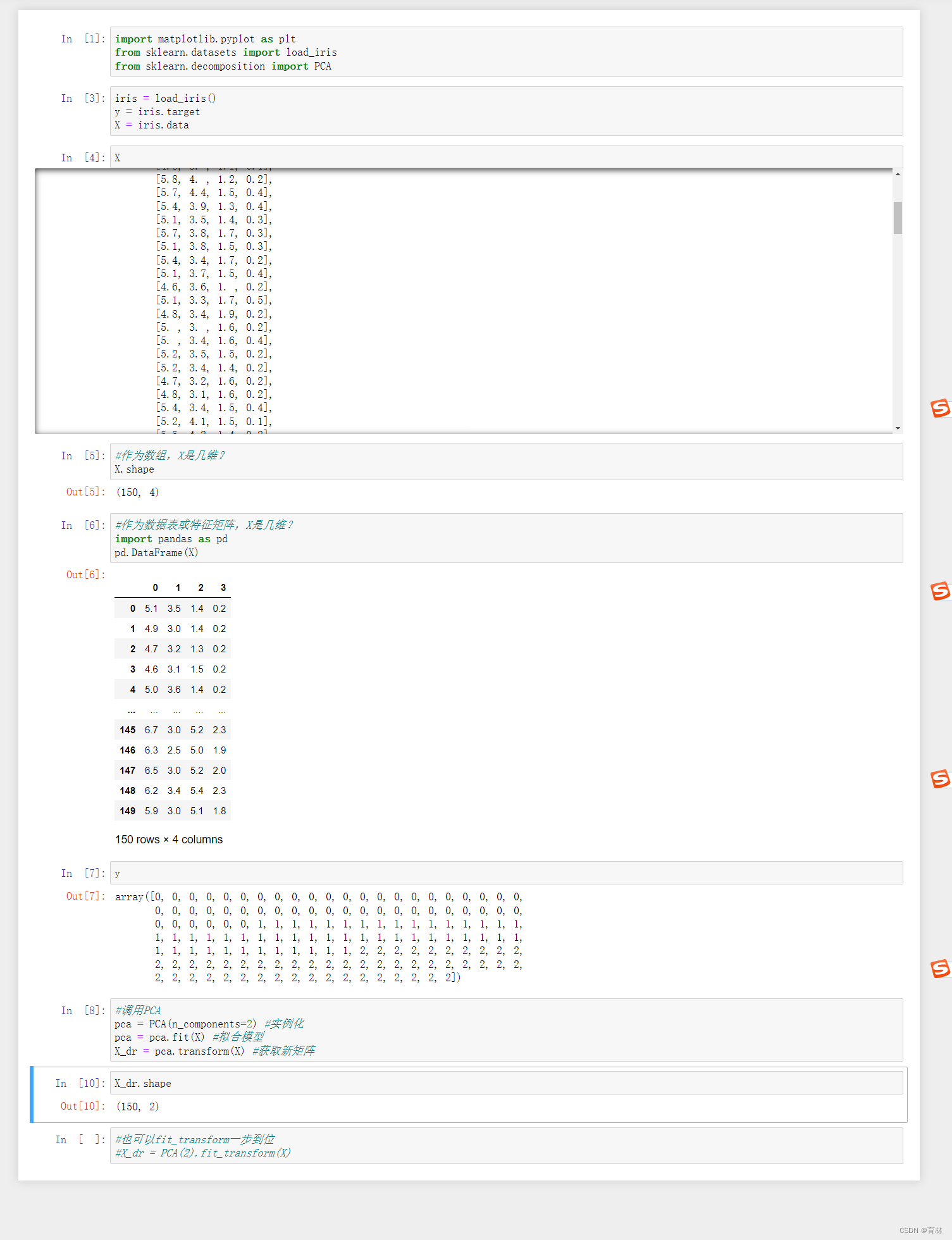
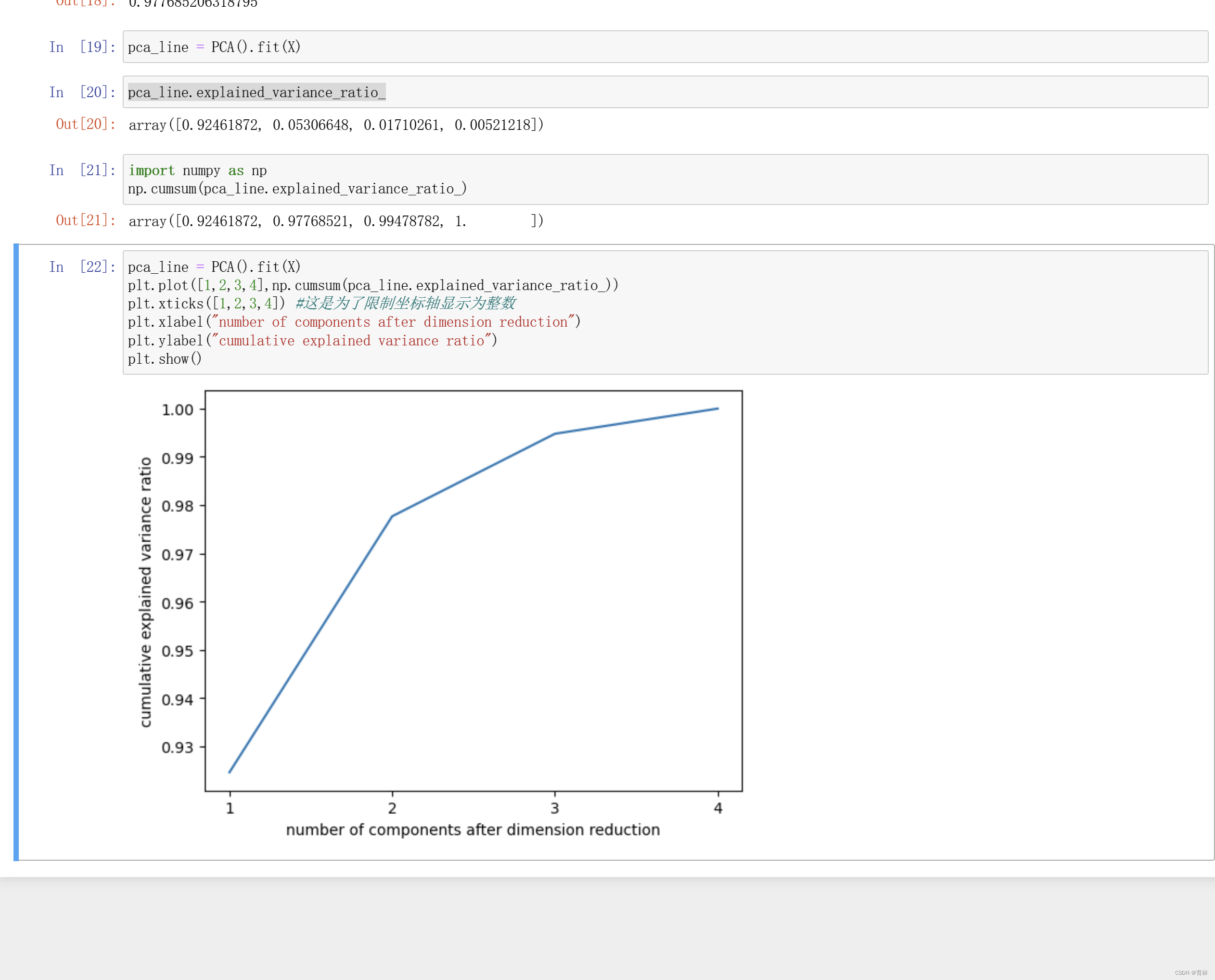
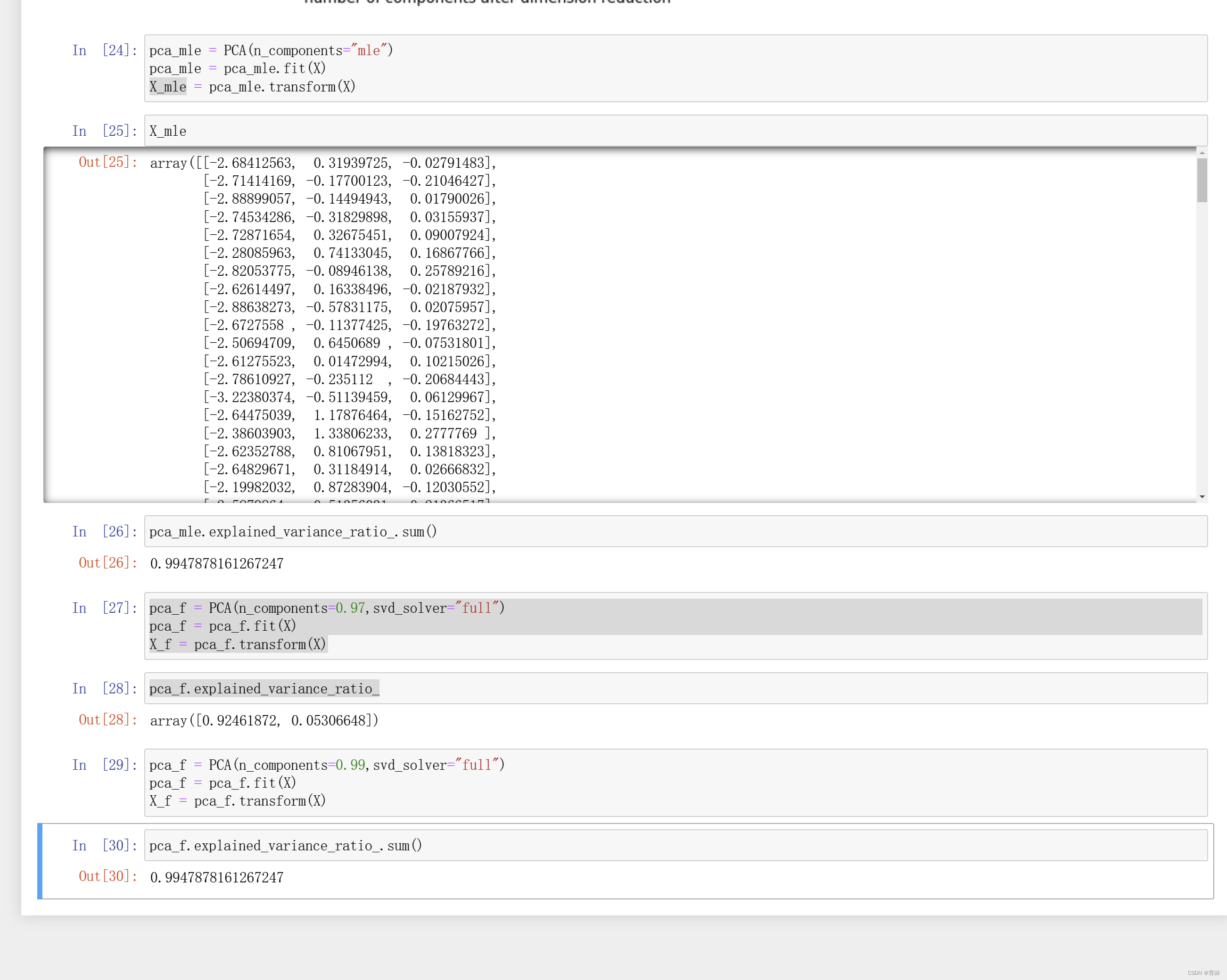
n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数。一说到K,大家可能都会想到,类似于KNN中的K和随机森林中的n_estimators,这是一个需要我们人为去确认的超参数,并且我们设定的数字会影响到模型的表现。如果留下的特征太多,就达不到降维的效果,如果留下的特征太少,那新特征向量可能无法容纳原始数据集中的大部分信息,因此,n_components既不能太大也不能太小。那怎么办呢?
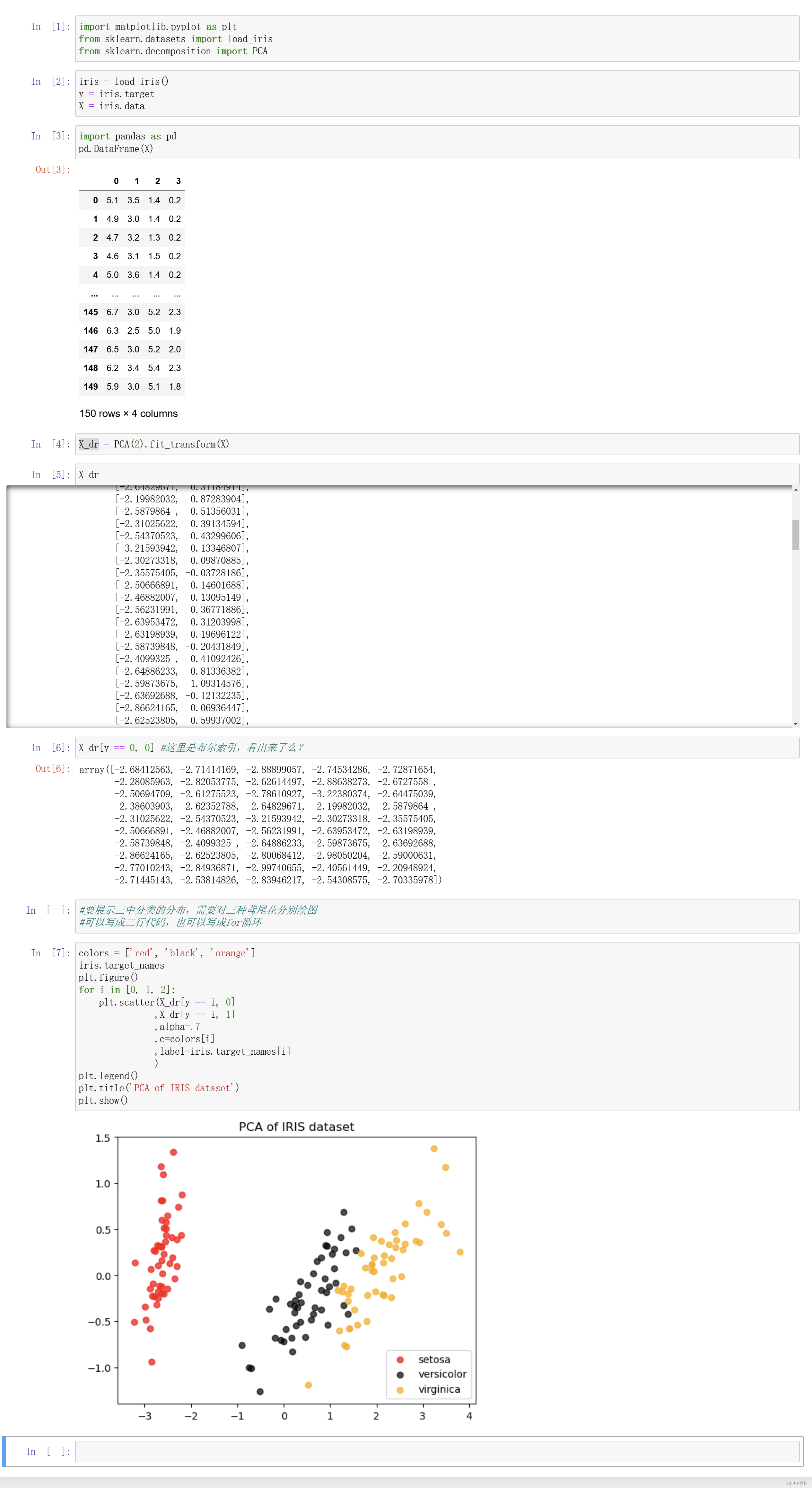
可以先从我们的降维目标说起:如果我们希望可视化一组数据来观察数据分布,我们往往将数据降到三维以下,很多时候是二维,即n_components的取值为2。
2、PCA中的SVD

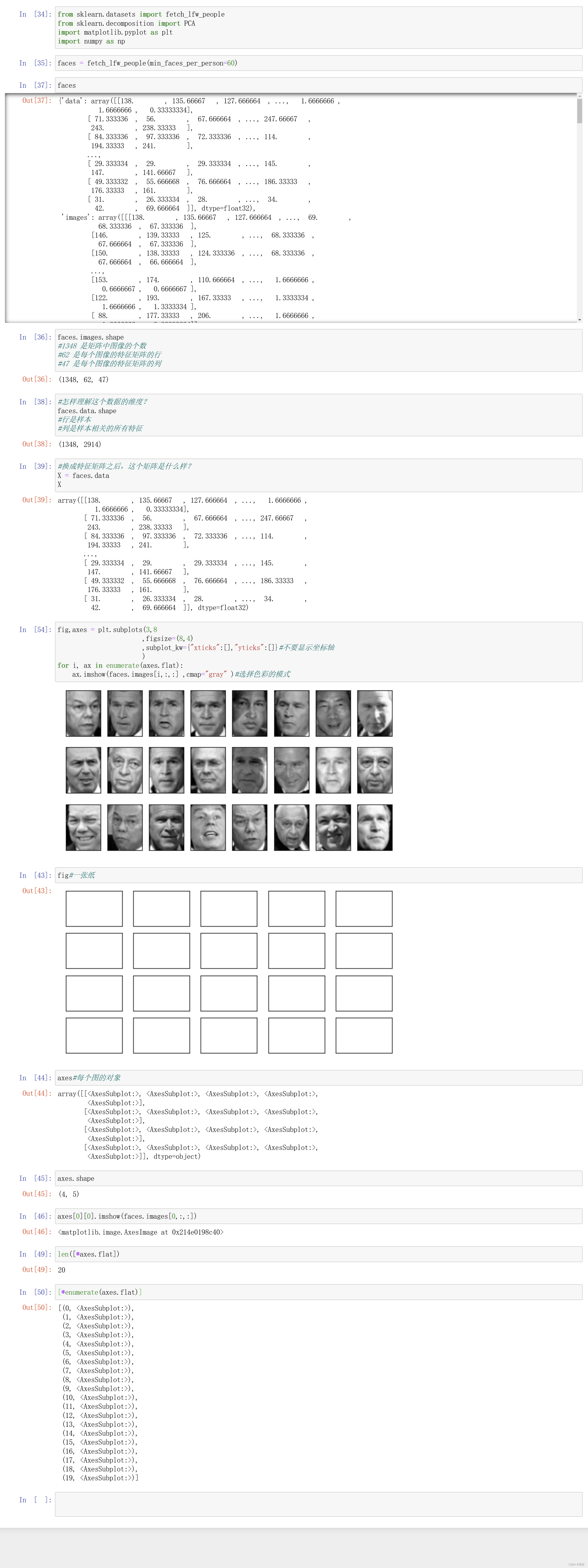
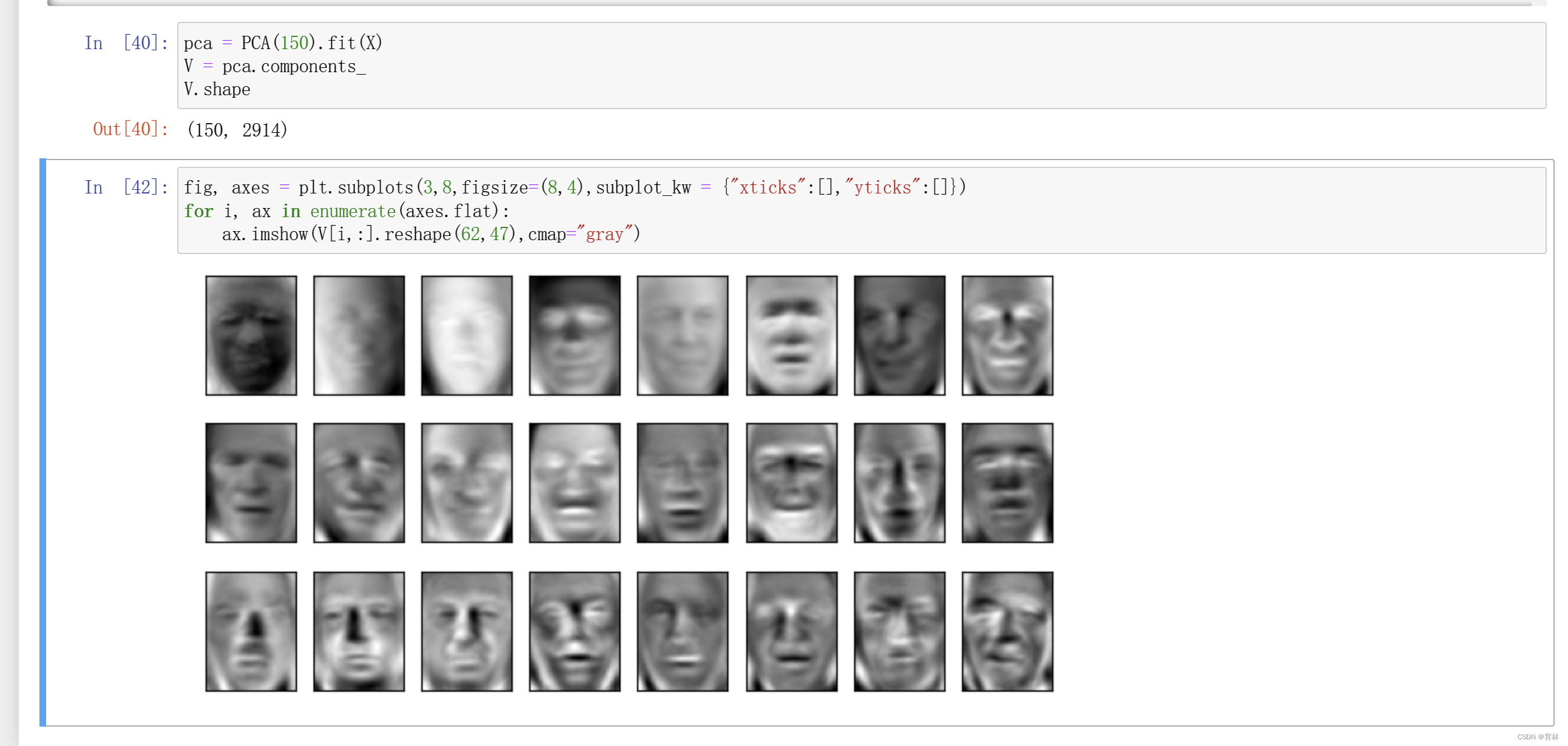
三、降维算法人脸识别案例

二级标题
在这里插入代码片
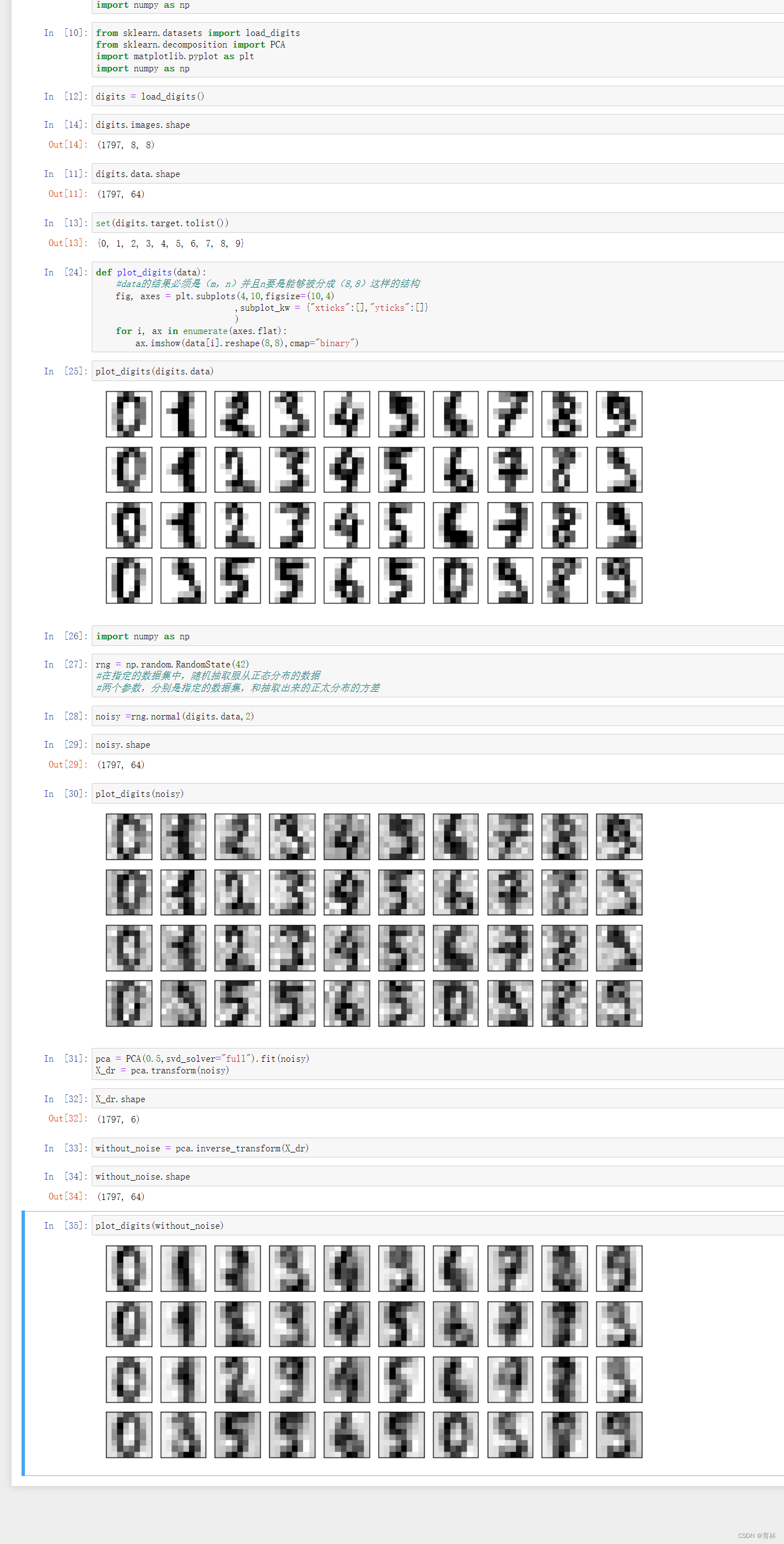
四、手写数据降噪案例
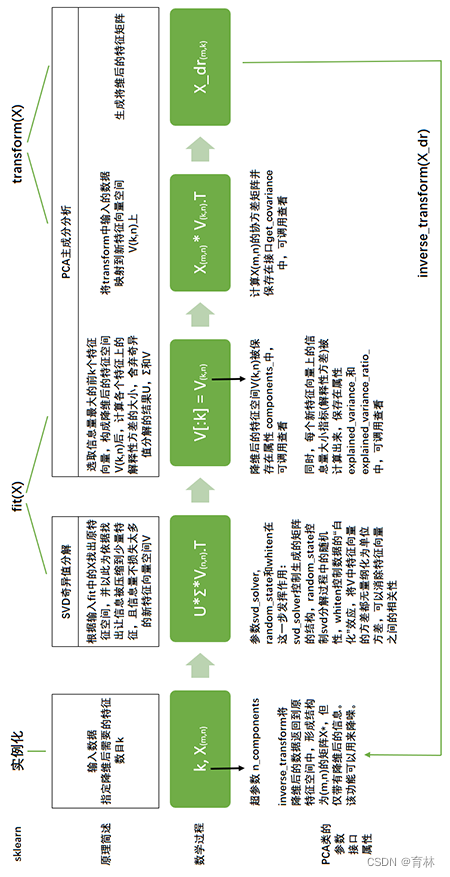
五、重要接口,参数和属性总结
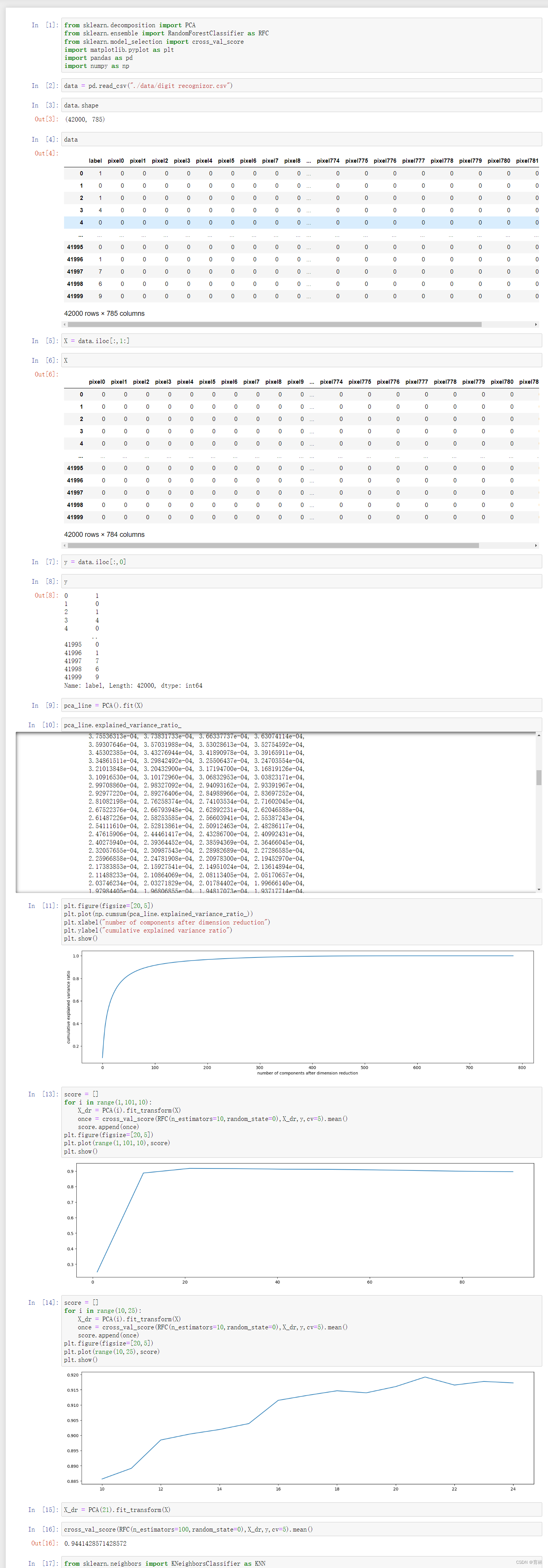
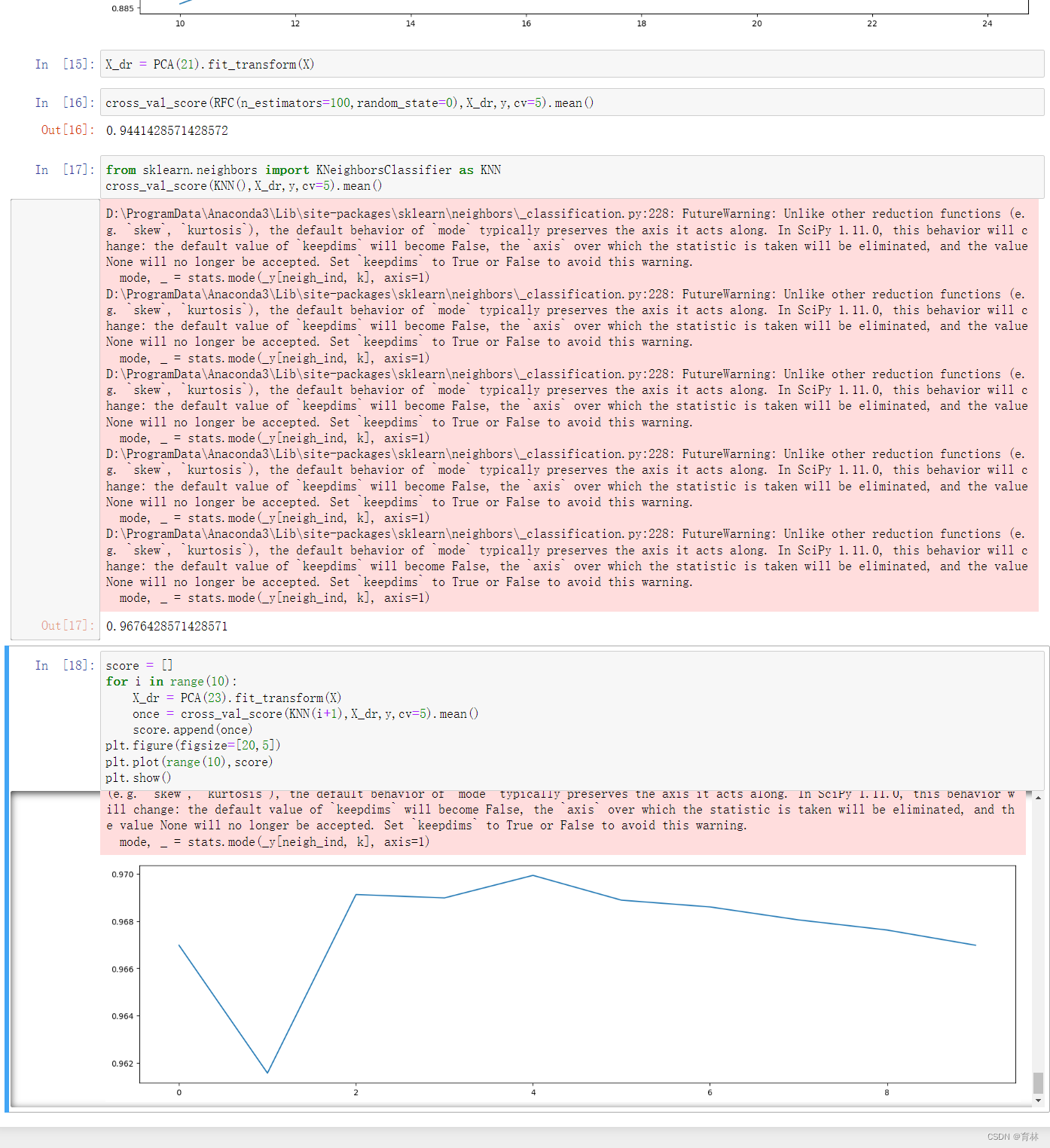
六、手写数据降维案例














 1707
1707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









