







上一篇:基于Transformer的路径规划 - 第二篇 合成数据
接上一篇,这几天工作很忙,模型训练好后一直没时间测试,今天抽空全面测试了一下,使用7层Transformer Decoder组成的GPT模型,生成策略采用贪心搜索,随机生成了10000条测试样本,错了94个,成功率只有99.06%左右,这个成功率还是太低了,比我预想的差很多,毕竟场景比较简单。如果简单的场景达不到99.9%以上的成功率,那复杂的场景就不用想了。部分测试结果如下:

图中红色为起始点,蓝色为目标点,绿色为模型生成的路径。第三排第一组不是最优路径。由于合成样本中障碍物的位置过于随机,看起来比较假,可能会导致模型在真实场景中表现不佳。
生成路径失败的原因几乎都是与障碍物发生了碰撞,例如:

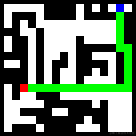
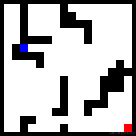
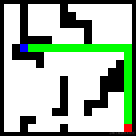
“发生碰撞”确实很不应该,因为碰撞与否是最容易学会的规则,我会在接下来的实验中对这个问题进行改进。如何让模型知道宁可绕远路,也绝对绝对不要“发生碰撞”?这个问题其实很有代表性的,不一定是因为模型学习能力不足导致的,可能是因为模型没有意识到“发生碰撞”是不可接受的。
下面说一下模型的设计:
1、词汇表
<PAD>:用于将输入补到固定的长度
<EOS>:表示生成的路径已经结束
<FREE>: 表示无障碍区域
<OBSTACLE>: 表示有障碍区域
<START>:表示起始点
<GOAL>:表示目标点
<PATH>:表示路径区域,仅用于测试
x0~x15:表示生成路径点的x坐标
y0~y15:表示生成路径点的y坐标
2、样本形式
一条训练样本包含16×16+8+128+1=393个token,由以下几部分组成:环境、起始点/目标点坐标、路径坐标。示例如下:
<FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE>
<FREE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE>
<OBSTACLE> <START> <OBSTACLE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE>
<FREE> <FREE> <OBSTACLE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE>
<OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE>
<OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE>
<OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE> <FREE>
<FREE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE>
<FREE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE>
<OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <GOAL>
<FREE> <FREE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE>
<FREE> <FREE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE>
<OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE>
<FREE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE>
<OBSTACLE> <OBSTACLE> <FREE> <OBSTACLE> <OBSTACLE> <FREE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE>
<OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <FREE> <FREE> <FREE> <FREE> <OBSTACLE> <OBSTACLE>
x1 y2 x15 y9 <PAD> <PAD> <PAD> <PAD> x1 y3 x1 y4 x1 y5 x1 y6
x1 y7 x2 y7 x3 y7 x3 y8 x4 y8 x5 y8 x6 y8 x6 y9
x7 y9 x8 y9 x9 y9 x10 y9 x11 y9 x12 y9 x13 y9 x14 y9
<EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS>
<EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS>
<EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS>
<EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS>
<EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS>
<EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS> <EOS>
生成路径的最大长度为128。
3、模型训练
训练过程中,输入前n-1个token,预测后n-1个token。在计算损失时,需要屏蔽掉路径点坐标之外的token。由于模型比较小,使用单GPU训练即可,显存不得低于6G。
这几天在研究过程中,我了解到传统的路径规划算法,例如A*,也是能够获得最优路径的,而且速度也不慢。那基于Transformer的路径规划算法有什么优势呢?这个问题等我以后对路径规划问题有更深的理解之后再来回答吧。由于在研究基于Transformer的路径规划算法之前,我对现有的路径规划算法几乎一无所知,因此文章中难免有错误之处,欢迎读者在评论区指出。

















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









