







 本文详细解读了Google的《Attention Is All You Need》论文,介绍了Transformer模型的结构,包括编码器和解码器,特别是注意力机制的运作方式,如Self-Attention和多头注意力。此外,还讨论了Transformer的优势,如并行计算和模型性能,并探讨了自注意力机制的重要性。论文的实验部分展示了模型在机器翻译任务上的高效训练和优秀表现。
本文详细解读了Google的《Attention Is All You Need》论文,介绍了Transformer模型的结构,包括编码器和解码器,特别是注意力机制的运作方式,如Self-Attention和多头注意力。此外,还讨论了Transformer的优势,如并行计算和模型性能,并探讨了自注意力机制的重要性。论文的实验部分展示了模型在机器翻译任务上的高效训练和优秀表现。
视频:Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
课程(推荐先看这个):李宏毅机器学习:self-attention(自注意力机制)和transformer及其变形
代码:https://github.com/tensorflow/tensor2tensor
The Annotated Transformer
万字逐行解析与实现Transformer iioSnail的博客-CSDN博客_transformer实战
本文主要参考博文并摘取文字和图片:李沐论文精读系列一: ResNet、Transformer、GAN、BERT_神洛华的博客
Transformer模型详解_爱编程真是太好了的博客
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
目录
7.2 缩放的点积注意力(Scaled Dot-Product Attention)
7.4 Decoder 的 Encode-Decode Attention 层
7.6 基于位置的前馈神经网络(Position-wise Feed-Forward Networks)
1 简介
主流的序列转换模型(由一个序列生成另一个序列)都是基于复杂的循环或卷积神经网络,这个模型包含一个编码器和一个解码器。论文提出了一个新的简单网络结构——Transformer,其仅仅是基于注意力机制,而完全不需要循环或卷积 。在两个机器翻译任务上的实验表明,该模型具有更好的性能,同时并行度更好,并且训练时间更少。泛化到其它任务效果也不错。
这篇文章最开始只是针对机器翻译来写的,transformer在机器翻译上效果也很好。但是随着bert、GPT等把这种架构用在更多的NLP任务上,甚至后面CV和video等也可以使用注意力机制,整个工作就火出圈了。
2 结论
本文介绍了Transformer,这是第一个完全基于注意力的序列转换模型,用多头自注意力(multi-headed self-attention)代替了 encoder-decoder 架构中最常用的循环层。对于翻译任务,Transformer可以比基于循环或卷积层的体系结构训练更快。
未来方向:将Transformer应用于文本之外的涉及输入和输出模式的问题中任务,以有效处理大型输入&输出任务,如图像、音频和视频等。让生成不那么时序化。
3 导论
序列建模和转换问题(如机器翻译)最新方法是LSTM和GRN等,后面许多研究都围绕循环语言模型和编码器-解码器体系结构进行。
循环网络模型通常是考虑了输入和输出序列的中字符位置的计算,计算限制为是顺序的。这种机制带来了两个问题:
1.时刻t的隐藏状态ht,是由上一时刻隐藏状态 ht−1和 t时刻输入共同决定的。这样可以把之前学到的历史信息都放在隐藏状态里,一个个传递下去。这种固有的时序模型难以并行化处理,无法利用GPU/TPU的并行计算功能,计算性能就很差。这些年做了一些并行化改进,但是问题依然存在。
2.存在长距离衰减问题,解码阶段越靠后的内容,翻译效果越差。如果不想丢掉,就要把ht维度设置的很高,并且在每一个时间步的信息都把它存下来,这样会造成内存开销很大。尽管 LSTM 等门控机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM 依旧无能为力。
This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples
自注意力模型的权重是动态生成的,因此可以处理变长的信息序列,优势不仅仅在于对词语进行编码时能充分考虑到词语上下文中的所有信息,还在于序列是一次性送入模型,通过矩阵运算做到并行化处理。attention在此之前,已经成功的应用在encoder-decoder 架构中,但主要是用在如何把编码器的信息有效的传递给解码器,所以是和RNN一起使用的。
本文提出的Transformer,不再使用循环神经层,而是纯基于注意力机制,来构造输入和输出之间的全局依赖关系(draw global dependencies between input and output)。Transformer可以进行更多的并行化,训练时间更短,翻译效果更好。
4 背景
使用卷积神经网络替换循环神经网络,并行计算所有输入和输出位置的隐藏表示,是扩展神经GPU,ByteNet和ConvS2S的基础,因为这样可以减少时序计算。但是CNN对长序列难以建模,因为卷积计算时,卷积核/感受野比较小,如果序列很长,需要使用多层卷积才可以将两个比较远的位置关联起来。但是使用Transformer的注意力机制的话,每次(一层)就能看到序列中所有的位置,就不存在这个问题。关联来自两个任意输入或输出位置的数据所需的操作数量,随着距离增长,对于ConvS2S呈线性,对于ByteNet呈对数,而对于Transformer是常数,因为一次就看到了。
但是卷积的好处是,一个输出可以有多个通道,每个通道可以认为是识别不同的模式,作者也想得到这种多通道输出的效果,所以提出了Multi-Head Attention多头注意力机制,去模拟卷积多通道输出效果。
Attention可以理解为一种序列聚焦方法,基本思想是对序列分配注意力权重,把注意力集中在最相关的序列上,在此之前已成功用于多种任务。但Transformer是第一个完全依靠self-attention,而不使用卷积或循环的的encoder-decoder 转换模型。
5 模型架构
大部分序列模型(neural sequence transduction models)都是encoder-decoder结构。encoder负责将一个符号表示的输入序列 (x1,...,xn) 映射为一个连续表示的序列 z=(z1,...,zn)。然后将 z作为Decoder的其中一个输入,decoder会一次一个的产生字符输出序列(output sequence of symbols) (y1,...,ym)。在每个时刻,模型都是自回归的(auto-regressive),也就是上一个时刻的产生的字符,作为写一个时刻额外的输入。
而Transformer也是这样的encoder-decoder结构.
模型特点
- Encoder 和 Decoder 的输入都是单词的 Embedding 向量 和 位置编码(Positional Encoding)。
- Encoder 的初始输入是训练集——输入序列 X(x1,...xn),对于句子而言xt表示第t个词,将X映射到一个连续的表示 z=(z1,...zn)中,其中zt是对应于xt的一个向量表示。
- Decoder 的初始输入是训练集的标签Y,并且需要整体右移(Shifted Right)一位。此外在 Decoder 中,第二子层的输入为 Encoder 的输出(key 向量和 value 向量)以及前一子层的输出(query 向量)。解码器生成输出序列 (y1,...ym),每一步生成一个元素。
- 编码器和解码器序列可以不一样长。
- 解码器是自回归(auto-regressive)模型,它在生成下一个结果时,会将先前生成的所有结果加入输入序列。自回归模型的特点:过去时刻的输出可以作为当前时刻的输入。
At each step the model is auto-regressive , consuming the previously generated symbols as additional input when generating the next.
-
最后的输出要通过Linear层(全连接层),再通过 softmax 做预测。
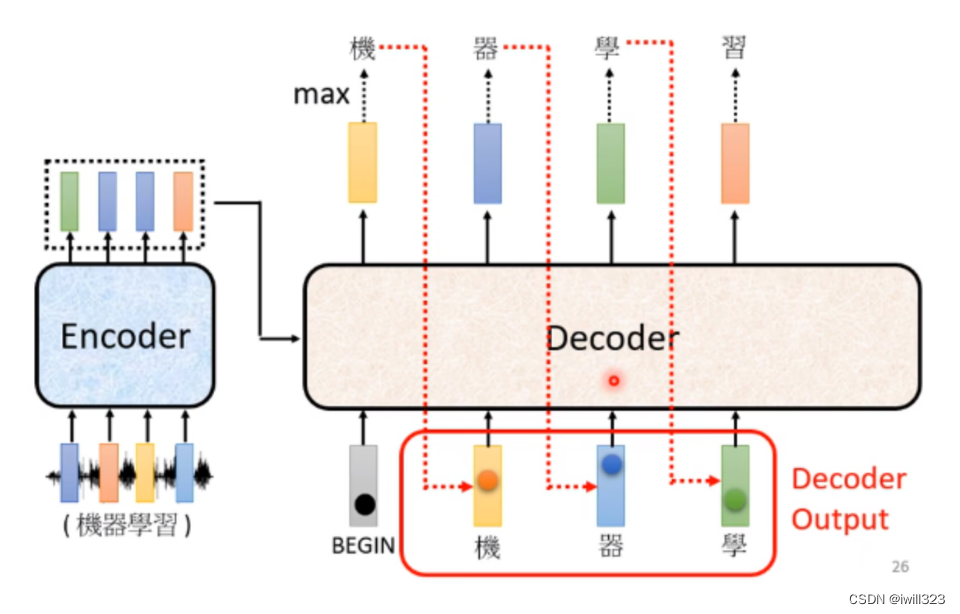
李宏毅关于自回归的解释
Decoder先输出BEGIN 这个Token产生“机”这个输出,现在Decoder的输入有 BEGIN 和“机”,根据这两个输入,输出一个蓝色的向量,根据这个蓝色的向量确定第二个输出,再作为输入,继续输出后续的文字,以此类推
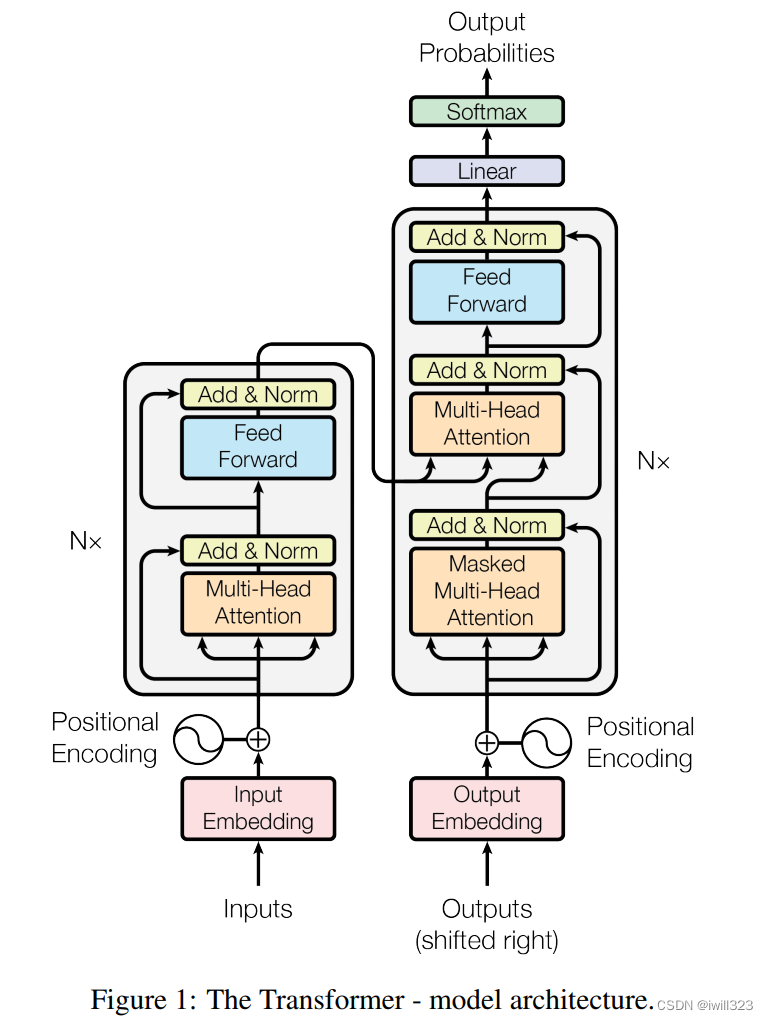
模型架构图
Transformer采用这种架构设计,对编码器和解码器使用堆叠的自注意力和全连接层,分别如下图的左半部分和右半部分所示。
整体上Transformer由四部分组成:
- Inputs : 可以理解为原始文本。等于Word Embedding(Inputs) + Positional Embedding
Word Embedding:假设我们有两个字典
[0(<bos>), 1(<eos>), 2(<pad>), 3(<unk>), 4(Love), 5(I), 6(You), ..., 100(other)]
[0(<bos>), 1(<eos>), 2(<pad>), 3(<unk>), 4(爱), 5(我), 6(你), ..., 100(其他)]
“I love you”根据字典对应的index转换为[5, 4, 6]。假设句子长度固定为7,最终转变为向量 [[ 0, 5, 4, 6, 1, 2, 2 ]],这里的Shape为(1,7),1是batch size, 7是句子长度。而向量中的0表示开始(<bos>),1表示结束(<eos>),2表示填充(<pad>),最后有两个2因为需要填充两个字符。将文字转换为向量后,就会经过Embedding层对向量进行编码,将一个字符编码成dmodel维的向量
- Outputs : Outputs是上一次Decoder的输出。等于Word Embedding(Outputs) + Positional Embedding
- Encoders stack : 由六个相同的Encoder层组成,除了第一个Encoder层的输入为Inputs,其他Encoder层的输入为上一个Encoder层的输出
- Decoders stack : 由六个相同的Decoder层组成,除了第一个Decoder层的输入为Outputs和最后一个Encoder层的输出,其他Decoder层的输入为上一个Decoder层的输出和最后一个Encoder层的输出
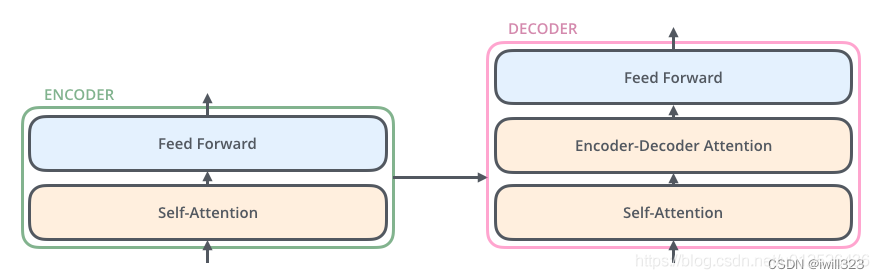
每一个 encoder 和 decoder 的内部简版结构如下图,Encoder层和Decoder层之间的差别在于Decoder中多了一个Encoder-Decoder Attention子层,而其他两个子层的结构在两者中是相同的:
代码
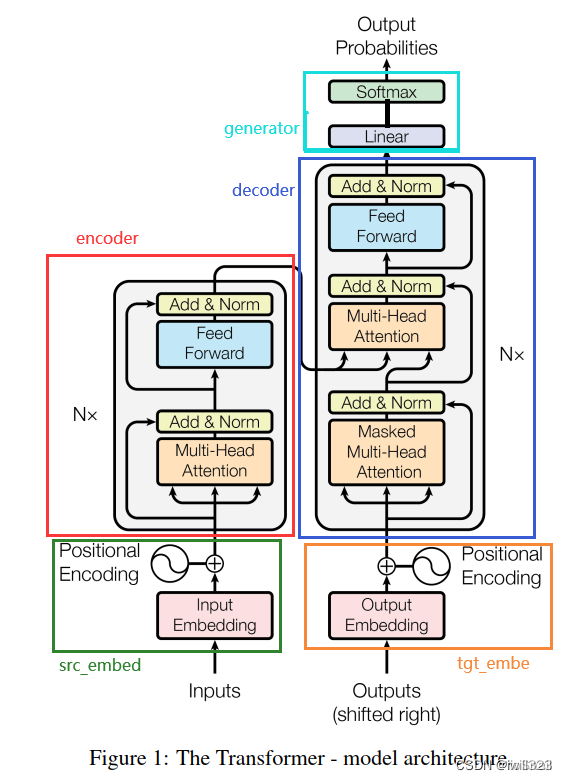
注意:
- src_embed、tgt_embed分别对encoder和decoder的输入做Embedding和Position Encoding。
- 在EncoderDecoder初始化的时候,src_embed等于nn.Sequential(Embeddings(d_model, src_vocab), c(position)),也就是分两步:先做词嵌入Embeddings,然后做PositionalEncoding,其中PositionalEncoding会产生位置编码,并与Embeddings的输出相加
- generator负责对Decoder的输出做最后的预测(Linear+Softmax),generator的调用是放在模型外面的。在推理时,generator使用的并不是decoder的所有输出,而是最后一个
out[:, -1],而在训练时,则是使用Decoder的全部输出。 - encoder的输出作为memory,输入decoder(self.decode函数)
- src: 未进行word embedding的句子,例如`[[ 0, 5, 4, 6, 1, 2, 2 ]]`,shape为(1, 7),即batch size为1,句子词数为7。其中0为bos,1为eos, 2为pad
- tgt: 未进行word embedding的目标句子,例如`[[ 0, 7, 6, 8, 1, 2, 2 ]]`
- src_mask
- 用于对encoder的多头注意力,盖住非句子的部分,例如`[[True, True, True, True, True, False, False]]`。 相当于对上面`[[ 0, 5, 4, 6, 1, 2, 2 ]]`中最后的`2,2`进行掩盖。
[True,False,False,False,False,False,False], # 从该行开始,每次多一个True
[True,True,False,False,False,False,False],
[True,True,True,False,False,False,False],
[True,True,True,True,False,False,False],
[True,True,True,True,True,False,False], # 由于该句一共5个词,所以从该行开始一直都只是5个True
[True,True,True,True,True,False,False],
[True,True,True,True,True,False,False],
- decoder每一层的corss attention做掩码
- tgt_mask用于对decoder每一层的Mask Attention做掩码
- shape为(N, L, L),其中N为batch size, L为target的句子长度。例如(1, 7, 7),对于上面的例子,一个下三角矩阵,右上三角全为false,对角线及左下三角为true
- 当完成decoder的计算后,接下来可以使用self.generator(nn.Linear+Softmax)来进行最后的预测。Output Probabilities是线性层后经过Softmax的概率分布。最大的值对应的index,然后再去字典中查询,就知道预测的词是什么了。
class EncoderDecoder(nn.Module):
"""标准的Encoder-Decoder架构"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed # 源序列embedding
self.tgt_embed = tgt_embed # 目标序列embedding
self.generator = generator # 生成目标单词的概率
def forward(self, src, tgt, src_mask, tgt_mask):
"""接收和处理原序列,目标序列,以及他们的mask"""
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)6 编码器和解码器
6.1 编码器
假设句子长度为n,那么编码器的输入是n个长为d的 embedding 向量与位置编码进行结合后的向量。
编码器由N=6个相同encoder层堆栈组成。下面是克隆encoder层用到的函数
def clones(module, N):
"""产生N个相同的层"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)]) 下面的代码将encoder层克隆之后,最后一层结果经过LayerNorm,输出
初始化用到的layer就是下文的EncoderLayer。
x: 进行过Embedding和位置编码后的输入inputs。Shape为(batch_size, 词数,词向量维度)。例如(1, 7, 512),batch_size为1,7个词,每个词512维
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)每层有两个子层:
1.multi-head self-attention
2.FFNN层(前馈神经网络层,Feed Forward Neural Network),其实就是MLP,为了fancy一点,就把名字起的很长。
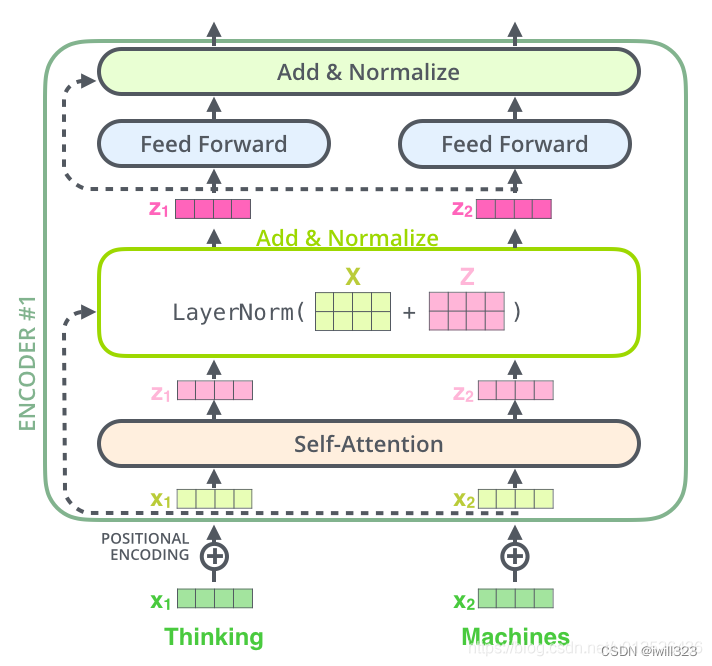
对照上图,进行层内连接
size: 就是d_model,也是词向量的维度。
self_attn: MultiHead Self-Attention模型
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2) # 克隆两个SublayerConnection,第一个给Attention用,第二个给Feed Forward用
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 自注意力,残差连接
return self.sublayer[1](x, self.feed_forward) # 前馈网络,残差连接
特点:
- 两个子层都使用残差连接(residual connection),即每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是当前子层的函数。
- 注意,下面残差连接的代码是先做LayerNorm,然后再送入子层,和论文不太一样
- 最后一个EncoderLayer层Add后并没有Norm,所以要补一个,这也就是为什么在Encoder类的返回是
return self.norm(x)而不是直接return x。
class SublayerConnection(nn.Module):
"""Add+Norm"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size) # 实现见后文
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""add norm"""
norm = self.dropout(sublayer(self.norm(x)))
return x + norm- 然后进行层归一化(layer normalization)
dmodel的设置:
- 为了简单起见,模型中的所有子层以及嵌入层的输出向量维度都是dmodel= 512(如果输入输出维度不一样,残差连接就需要做投影,将其映射到统一维度)。这和之前的CNN或MLP做法是不一样的,比如CNN会改变空间维度和通道维度
- 各层统一维度使得模型比较简单,只有N和 dmodel两个参数需要调。这个也影响到后面一系列网络,比如bert和GPT等等。
-
6.2 解码器
-
结构
-
解码器同样由 N=6个相同的decoder层堆栈组成。
-
初始化用到的layer就是下文的decoder
-
x: 进行过Embedding和位置编码后的“输入outputs”。Shape为(batch_size, 词数,词向量维度)。 例如(1, 7, 512),batch_size为1,7个词,每个词512维。在预测时,x的词数会不断变化,x的shape第一次为(1, 1, 512),第二次为(1, 2, 512),以此类推。
-
class Decoder(nn.Module): "Generic N layer decoder with masking." def __init__(self, layer, N): super(Decoder, self).__init__() self.layers = clones(layer, N) self.norm = LayerNorm(layer.size) def forward(self, x, memory, src_mask, tgt_mask): for layer in self.layers: x = layer(x, memory, src_mask, tgt_mask) return self.norm(x) -
每个层有三个子层。
-
1.masked multi-head self-attention:做预测的时候,接受encoder 的输入,和自己之前的输出,决定接下来输出的一个向量
-
2.Encoder-Decoder Attention :编码器输出最终向量,将会输入到每个解码器的Encoder-Decoder Attention层,用来帮解码器把注意力集中输入序列的合适位置。
-
3. FFNN
-
与编码器类似,每个子层都使用残差连接,最后进行层归一化。
-
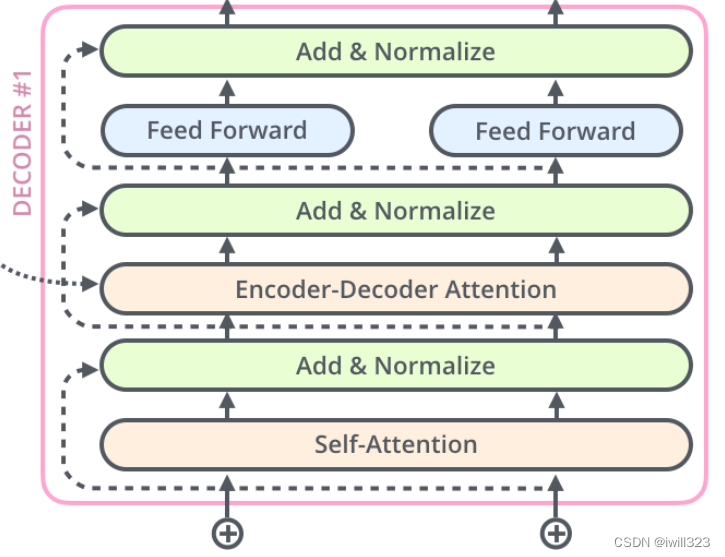
下面对三个子层进行连接。
-
size: d_model,也就是词向量的维度。
-
encoder-decoder-attention层中,q向量来自上一层的输入,k和v向量是encoder最后层的输出向量memory
-
class DecoderLayer(nn.Module): "Decoder is made of self-attn, src-attn, and feed forward (defined below)" def __init__(self, size, self_attn, src_attn, feed_forward, dropout): super(DecoderLayer, self).__init__() self.size = size self.self_attn = self_attn self.src_attn = src_attn self.feed_forward = feed_forward self.sublayer = clones(SublayerConnection(size, dropout), 3) def forward(self, x, memory, src_mask, tgt_mask): m = memory x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # DecoderLayer的第二个Attention(中间那个),attention的key和value使用的是memory x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) return self.sublayer[2](x, self.feed_forward)decoder端的输入
- Encoder的输入是原句子(即要被翻译的句子),而Decoder的输入是目标句子(即翻译后的句子)。decoder在运行的时候,t 时刻的预测需要之前所有时刻的输出作为输入。
举例说明:我爱中国 → I Love China
位置关系:
- 0-“I”
- 1-“Love”
- 2-“China”
操作:整体右移一位(Shifted Right)
- 0-</s>【起始符】目的是为了预测下一个Token
- 1-“I”
- 2-“Love”
- 3-“China”
具体步骤:
Time Step 1
- 初始输入: 起始符
</s> - 中间输入:(
我爱中国)Encoder Embedding - Decoder:产生预测
I
Time Step 2
- 初始输入:起始符
</s>+I - 中间输入:(
我爱中国)Encoder Embedding - Decoder:产生预测
Love
Time Step 3
- 初始输入:起始符
</s>+I+Love - 中间输入:(
我爱中国)Encoder Embedding - Decoder:产生预测
China
-
decoder端的输入在训练和推理阶段是不同的。
- 在推理的时候,Decoder是一遍一遍的执行,每次的输入都是之前的所有输出
- 在训练的时候,一次将目标句子(训练集的标签)全部送给Decoder,通过掩码(mask)的方式来得到和推理一个一个同样的结果。
- 掩码效果相当于Decoder的输入整体右移(Shifted Right)一位。
-
6.3 编码器和解码器结构图
-
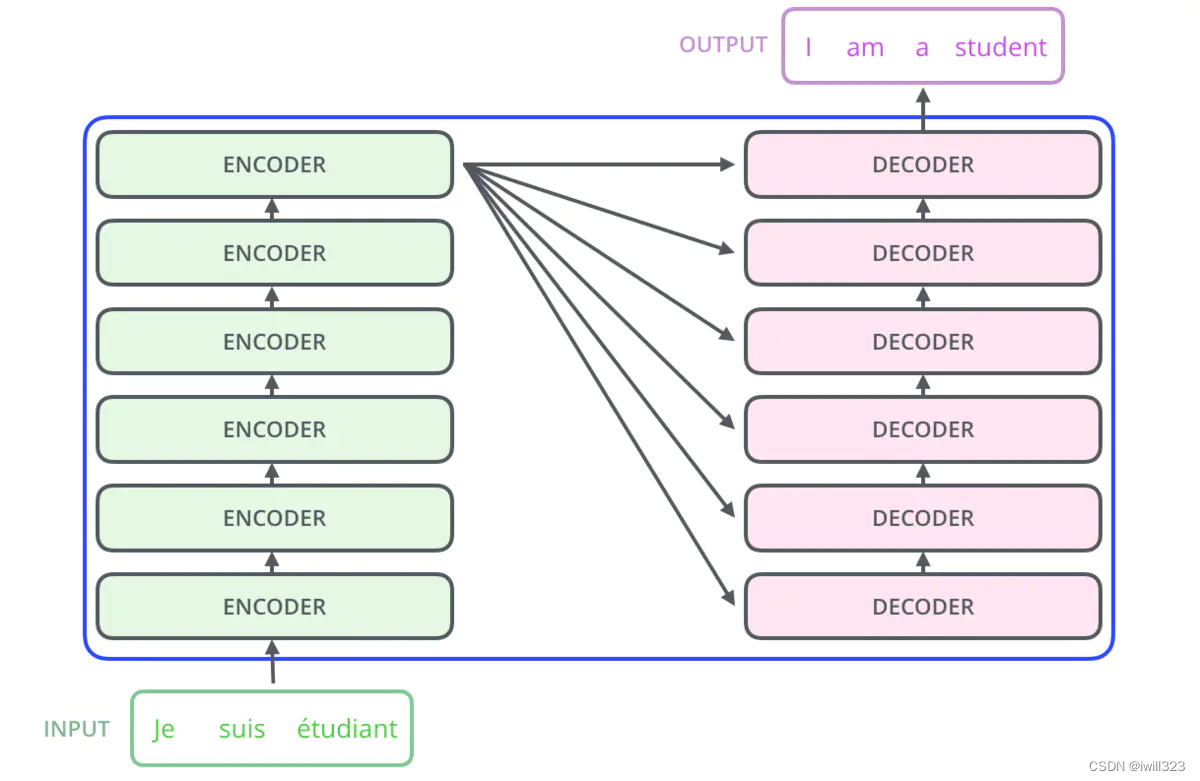
假设一个 Transformer 是由 2 层编码器和两层解码器组成的,那么结构如下图所示:
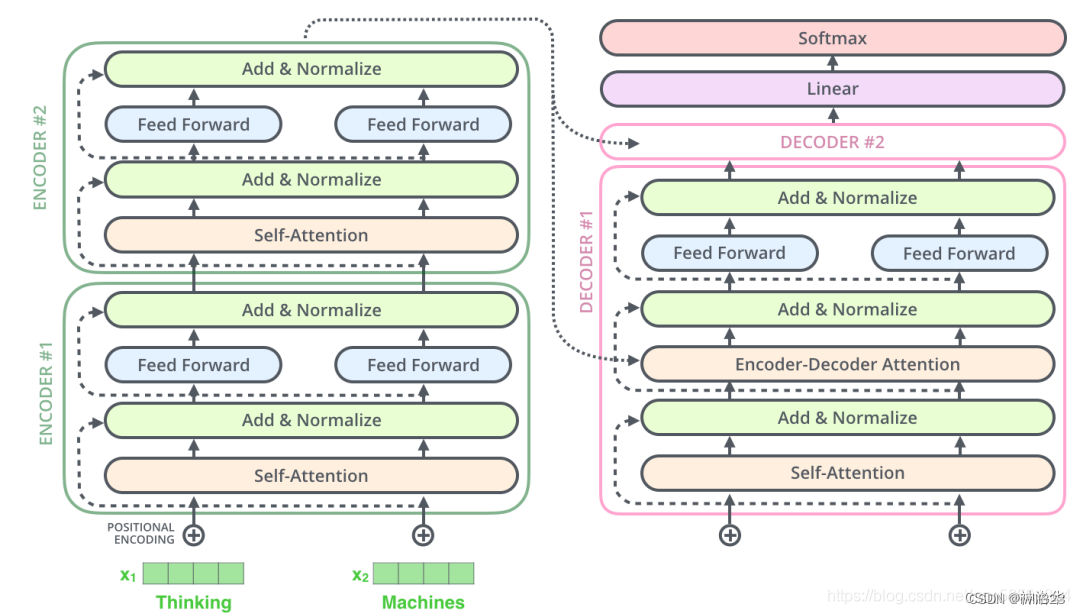
decoder 有很多层 self-attention,Transformer 论文中,每一层 self-attention 的输出都是与 encoder 最后的输出 sequence 做 cross attention。但是也可以用不同的设计,比如Decoder可以连接Encoder中的许多层而不一定只是最后一层。
6.4 为什么使用LN而不是BN?
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0,方差为1的数据。我们在把数据送入激活函数之前进行 Normalization,因为我们不希望输入数据落在激活函数的饱和区。
三维表示
输入可以看成3维向量:
- 对于CV任务,N是样本数,C是通道数,高是图片的H×W
- 对于NLP任务,N是样本数,C是序列长度,高是每个词的向量长度(512)
Batch Normalization和Layer Normalization可以用下图表示。图中要在蓝色的区域内做Normalization
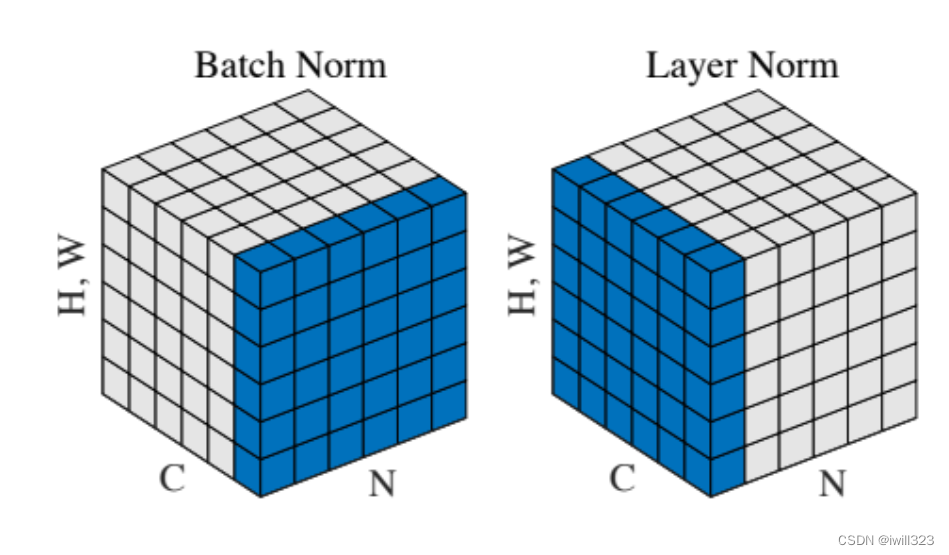
二维表示
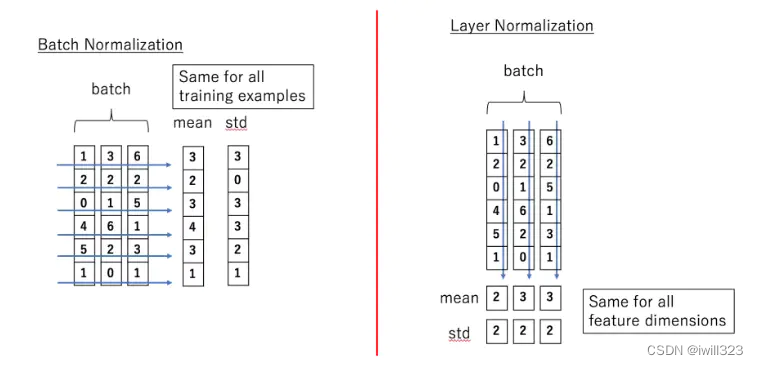
Batch Normalization:在特征/通道维度做归一化,即归一化不同样本的同一特征。
- 计算不定长序列时,不够长的序列后面会pad 0,这样做特征维度归一化缺少实际意义。
- 输入序列长度变化大时,不同 batch 计算出来的均值和方差抖动很大。
- 预测时使用训练时记录下来的全局均值和方差。如果预测时新样本特别长,超过训练时的长度,那么超过部分是没有记录的均值和方差的,预测会出现问题。
Layer Normalization:在每一个样本上计算均值和方差,进行归一化,即归一化一个样本所有特征。
- NLP任务中一个序列的所有token都是同一语义空间,进行LN归一化有实际意义
- 因为是在每个样本内做的,序列变长时,相比BN计算的数值更稳定。
- 不需要存一个全局的均值和方差,预测样本长度不影响最终结果。
Batch Normalization和Layer Normalization的实现细节,可以参考Batch Normalization和Dropout_iwill323的博客
下面`torch.nn.BatchNorm2d`的作用一致。官方文档BatchNorm2d — PyTorch 1.13 documentation
features: int类型,含义为特征数。也就是一个词向量的维度,一般和dmodel一致。
x: 为Attention层或者Feed Forward层的输出。Shape和Encoder的输入一样。(其实整个过程中,x的shape都不会发生改变)。例如,x的shape为(1, 7, 512),即batch_size为1,7个单词,每个单词是512维度的向量。
class LayerNorm(nn.Module):
"""构造一个layernorm模块"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
"""Norm"""
mean = x.mean(-1, keepdim=True) # 按最后一个维度求均值。mean的shape为 (1, 7, 1)
std = x.std(-1, keepdim=True) # 按最后一个维度求方差。std的shape为 (1, 7, 1)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_27 注意力机制
7.1 Self-Attention
Attention 和 Self-Attention 的区别:
- 1.以 Encoder-Decoder 框架为例,输入 Source 和输出 Target 内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention 发生在 Target 的元素 Query 和 Source 中的所有元素之间。
- 2.Self Attention是 Source 内部元素之间发生的Attention 机制,也可以理解为 Target=Source 这种特殊情况下的 Attention。
所谓self-attention自注意力机制,就是探索当前序列(self)中每一个元素对当前元素(self)的影响程度(相关程度),而传统attention的注意力概率分布来自外部。两者具体计算过程是一样的,只是计算对象发生了变化而已。
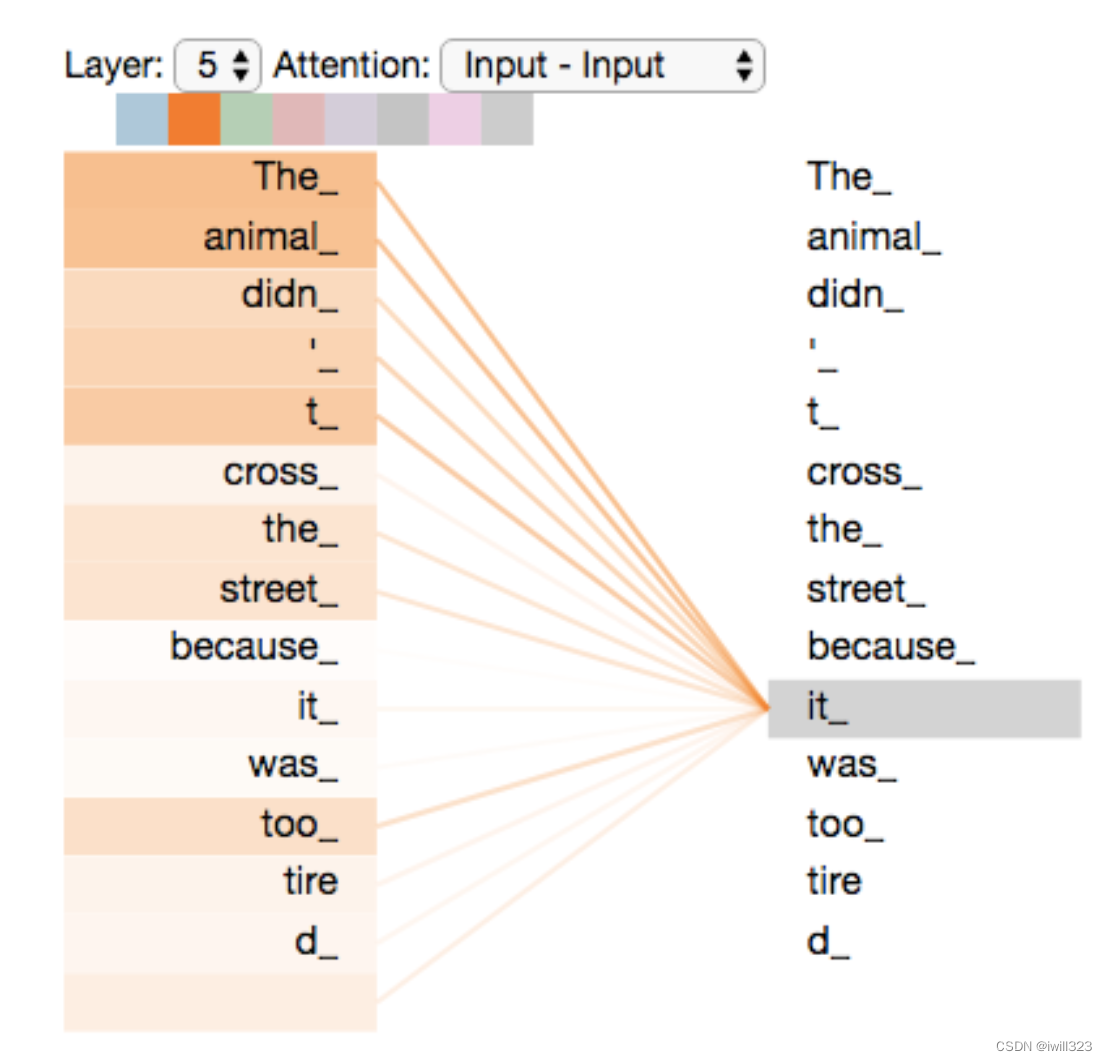
比如我们当前要翻译的句子为The animal didn’t cross the street because it was too tired。在翻译it时,它究竟指代的是什么呢,street还是animal?要确定it指代的内容,毫无疑问我们需要同时关注到这个词的上下文语境中的所有词。下图是模型的最上一层(下标0是第一层,5是第六层)Encoder的Attention可视化图。可以看到,在编码it的时候有一个Attention Head注意到了Animal,因此编码后的it有Animal的语义。
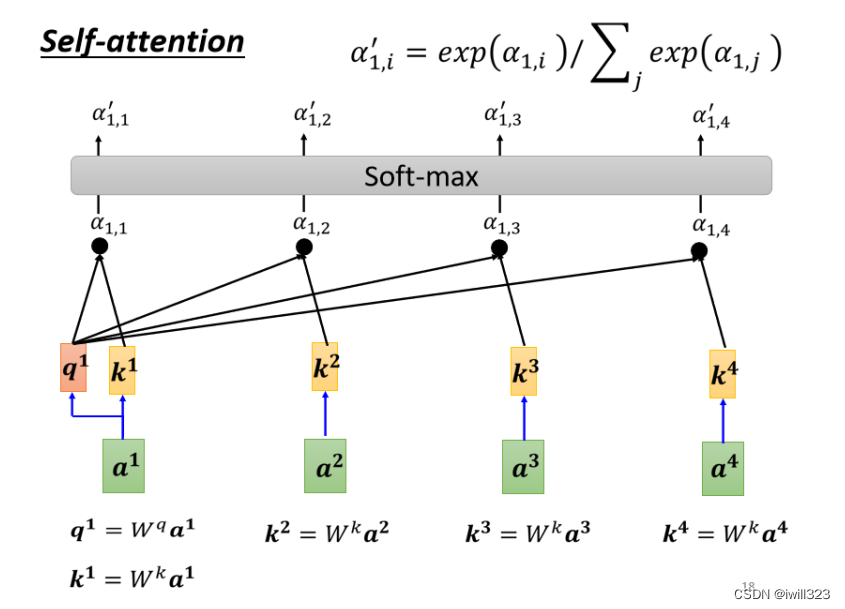
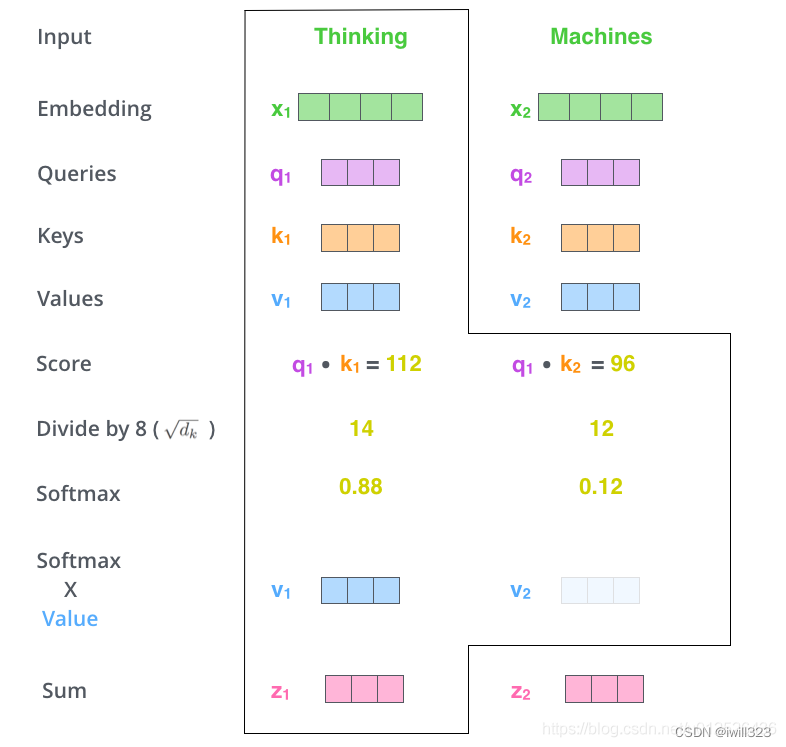
self-attention 会使用每个输入向量计算出三个新的向量,分别称为Query、Key、Value,这三个向量是用 embedding 向量(包含位置编码)与不同的矩阵相乘得到的结果,矩阵是随机初始化的。输出被计算为value的加权求和,其中每个value的权重由query与对应key计算所得,其实就是query与对应key相似度,该分数值决定了在某个位置 encode 一个词时,对输入句子的其他部分的关注程度(也即其他部分对该位置元素的贡献程度)。输出也是向量,由于是加权平均,所以输出和value的维度一致。
不同的相似函数导致不一样的注意力版本,有两个最常用的attention函数:
- 加法attentionhttps://arxiv.org/abs/1409.0473
使用具有单个隐层的前馈网络计算,q和k维度不一致也可以进行;
- 点积(乘法)attention
实现细节见下文。虽然理论上点积attention和加法attention复杂度相似,但在实践中,点积attention可以使用高度优化的矩阵乘法来实现,因此点积attention计算更快、更节省空间。
比较:当向量维度(下文的dk)的值比较小的时候,这两个机制的性能相差相近,当dk比较大时,加法attention比点积attention性能好。
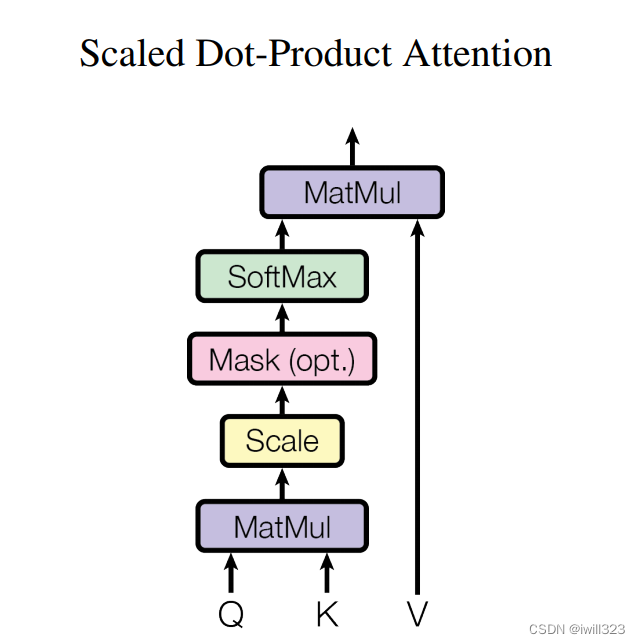
transformer用的是缩放的点积注意力Scaled Dot-Product Attention
7.2 缩放的点积注意力(Scaled Dot-Product Attention)
步骤
- 输入为query、key(维度都是dk,一般512)以及values(维度是dv)。
- 计算query和所有key的点积,得到两个向量的相似度(结果越大相似度越高);然后对每个点积结果除以sqrt(dk)
- 点积结果输入softmax函数,对每一行做softmax,行与行之间独立,结果就是value的权重。
- 对value进行加权求和
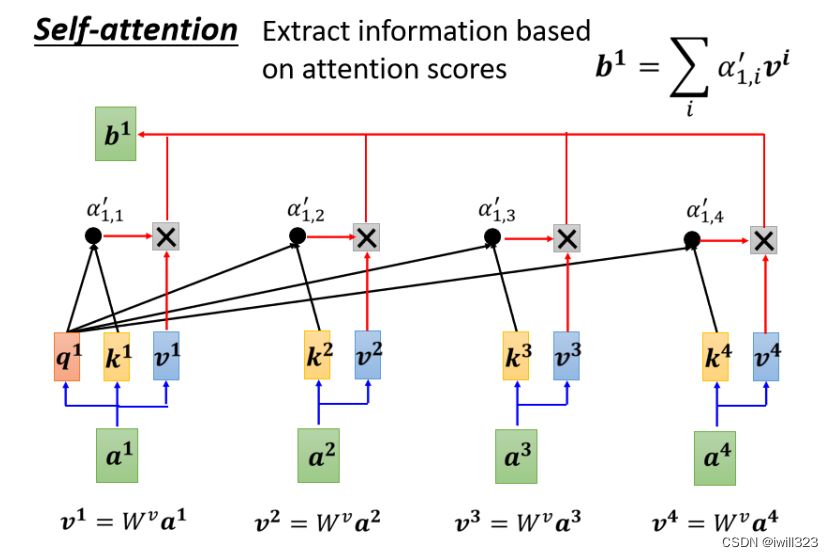
下图中α带有'上标,代表经过了softmax处理

也可以参考下图,thinking machines是输入序列
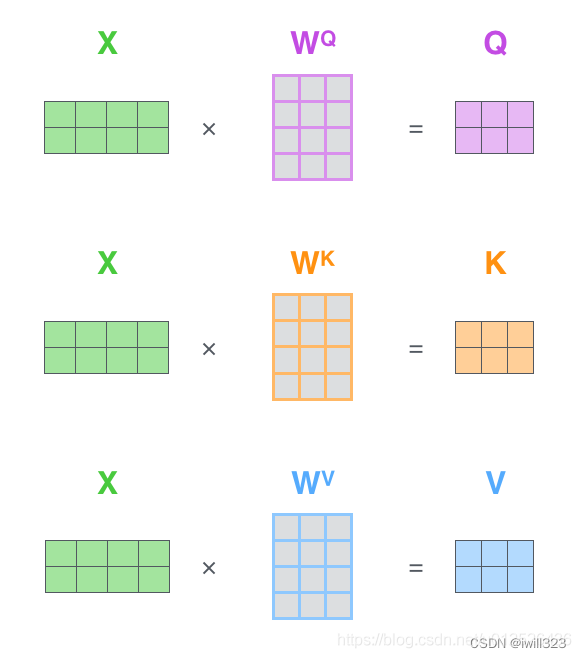
矩阵实现
在实际的应用场景,需要把上面的向量计算变为矩阵的运算。下图所示为矩阵运算的形式。其中X为输入对应的词向量矩阵,WQ、WK、WV为相应的线性变换矩阵,Q、K、V为X经过线性变换得到的Query向量矩阵、Key向量矩阵和Value向量矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









