







 本文系统调查了基于深度学习的3D点云分类方法,涵盖多视图、体素、点云和多态融合方法,讨论了各种方法的优缺点,强调了直接处理原始点云的潜力和挑战,如局部和全局特征的捕获,以及未来研究方向,包括点云数据的复杂性和噪声处理,以及在效率和准确性之间的平衡。
本文系统调查了基于深度学习的3D点云分类方法,涵盖多视图、体素、点云和多态融合方法,讨论了各种方法的优缺点,强调了直接处理原始点云的潜力和挑战,如局部和全局特征的捕获,以及未来研究方向,包括点云数据的复杂性和噪声处理,以及在效率和准确性之间的平衡。
基于深度学习的三维点云分类:系统调查与展望 - ScienceDirectDeep learning-based 3D point cloud classification: A systematic survey and outlook基于深度学习的三维点云分类:系统调查与展望 - ScienceDirect
突出
• 我们首先对3D数据进行详细介绍,并对点云进行更深入的解释,供读者理解,然后给出用于点云分类的数据集及其获取方法。
• 我们总结了最近发表的关于点云分类评论的研究,在此基础上补充了最先进的研究方法。
• 我们根据分类讨论方法子类别的优点和局限性。这种分类更适合研究人员根据实际需要探索这些方法。
• 我们给出了评估指标和方法的性能比较,然后分析了该领域的一些当前挑战和未来趋势。
抽象
近年来,点云表示已成为计算机视觉领域的研究热点之一,并已广泛应用于自动驾驶、虚拟现实、机器人等多个领域。尽管深度学习技术在处理常规结构化 2D 网格图像数据方面取得了巨大成功,但在处理不规则、非结构化点云数据方面仍然存在巨大挑战。点云分类是点云分析的基础,许多基于深度学习的方法已广泛应用于这项任务。因此,本文的目的是为该领域的研究人员提供最新的研究进展和未来趋势。首先,我们介绍点云获取、特征和挑战。其次,我们回顾了3D数据表示,存储格式和用于点云分类的常用数据集。然后,我们总结了基于深度学习的点云分类方法,并补充了最近的研究工作。接下来,我们比较和分析主要方法的性能。最后,我们讨论了点云分类的一些挑战和未来方向。
关键字:深度学习;点云;三维数据;分类
1 引言
机器学习的分类器(支持向量机(SVM),AdaBoost,随机森林(RF))
↓ 通过综合上下文信息解决了噪声问题
机器学习的分类器(随机场(CRF)、马尔可夫随机场(MRF))
↓ 直接处理点云
深度学习Pointnet
点云数据的稀疏性和无序性使得难以获得点云的局部或全局特征。直接处理原始点云的方法不能局限于过去的卷积、图或注意力机制的分类机制。因此,我们在原始点云的基础上探索了局部特征和全局特征机制,并对基于点的方法进行了更具体的分析,重点介绍了近年来最新的研究方法,涵盖了该领域的研究热点。




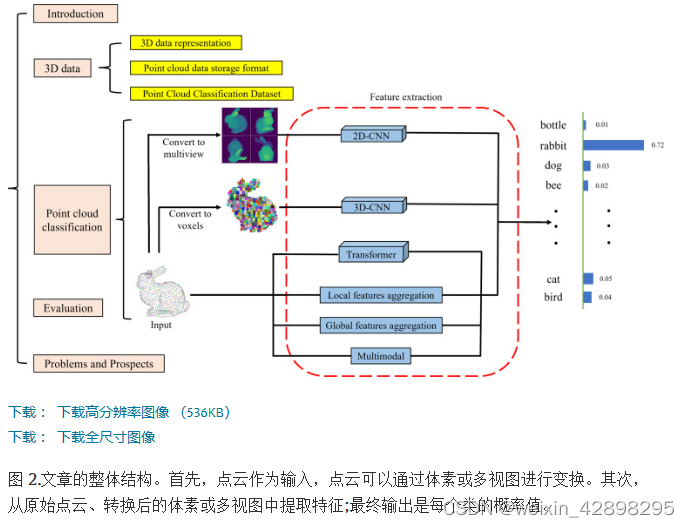
2. 研究方法
3. 3D数据
3.1 3D 数据表示
3D 数据有多种表示形式,例如点云、网格和体素。

3.2 点云的应用
a. 自动驾驶
b.医学领域
c. 三维重建
3.3 点云数据存储格式
有数百种3D文件格式可用于点云,不同的扫描仪可以生成多种格式的原始数据。点云数据文件之间的最大区别是使用ASCII和二进制。二进制系统直接以二进制代码存储数据。
常见的点云二进制格式包括 FLS、PCD、LAS 等。
其他几种常见的文件类型可以同时支持 ASCII 和二进制格式。这些包括PLY,FBX。
E57 以二进制和 ASCII 格式存储数据,将两者的许多优点结合在一个文件类型中。
3.4 3D点云公共数据集
如今,有许多由行业和大学提供的点云数据集。不同方法在这些数据集上的性能反映了方法的可靠性和准确性。这些数据集由虚拟或真实场景组成,可以为训练网络提供真实标签。本节将介绍一些常用的点云分类数据集。
ModelNet40 [26]:该数据集由普林斯顿大学视觉与机器人实验室开发。ModelNet40 数据集由合成 CAD 对象组成。作为使用最广泛的点云分析基准,ModelNet40 因其多样化的类别、清晰的形状和结构良好的数据集而广受欢迎。数据集由 40 个类别的对象组成(例如飞机、汽车、植物、灯),其中 9843 个用于训练,2468 个用于测试。相应的点从网格表面均匀采样,然后通过移动到原点并缩放到单位球体来进一步预处理。下载链接: Princeton ModelNet
ModelNet-C [27]:ModelNet-C 集包含 185,000 个不同的点云,基于 ModelNet40 验证集创建。该数据集主要用于对3D点云识别的损伤鲁棒性进行基准测试,每种损伤类型有15种损伤类型和5个严重性级别,如噪声、密度等。帮助了解模型的稳健性。下载链接: https://sites.google.com/umich.edu/modelnet40c
ModelNet10 [26]: ModelNet10:ModelNet10是ModelNet40的子集,数据集仅包含10个类,分为3991个训练形状和908个测试形状。下载链接: Princeton ModelNet
悉尼城市对象 [28]:该数据集收集在悉尼中央商务区,包含各种常见的城市道路对象,包括车辆、行人、标志和树木类别中的 631 个扫描对象。下载链接: Sydney Urban Objects Dataset - ACFR - The University of Sydney
ShapeNet [29]:ShapeNet 是由斯坦福大学、普林斯顿大学和美国芝加哥丰田理工学院的研究人员开发的 3D CAD 模型的大型存储库。该存储库包含超过 300 亿个模型,其中 220,000 个模型被分类为 3,135 个类,使用 WordNet 超名-次级关系排列。ShapeNetCore 是 ShapeNet 的一个子集,包括近 51,300 个独特的 3D 模型。它提供了 55 个常见的对象类别和注释。ShapeNetSem也是ShapeNet的一个子集,其中包含12,000个模型。它的规模较小,但覆盖范围更广,包括270个类别。下载链接: ShapeNet
ScanNet [30]:ScanNet 是一个包含 2D 和 3D 数据的实例级室内 RGB-D 数据集。它是标记体素的集合,而不是点或对象。截至目前,最新版本的ScanNet v2已经收集了1513个带注释的扫描,表面覆盖率约为90%。在语义分割任务中,此数据集标有 20 类带注释的 3D 体素化对象。下载链接:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









