







上周从 语雀迁移到了 Obsidian 的过程中拿到了个人的所有文档,发现也写了不少东西,但很多笔记实际上都没什么印象了,没有利用起来,想起前段时间非常火的基于 LLM + 外挂知识库的知识库问答系统,于是想尝试搭建一个个人知识库,通过 LLM 的推理和归纳能力,将这些吃灰的笔记回收利用 。
外挂知识库是什么
在介绍外挂知识库前,我们先来看看 ChatGPT 的特点:
- 可以生成高质量的文本,并且语义连贯、流畅度高。
- 可以根据输入的上下文信息,推理和归纳,针对问题生成更相关的回答。
我们希望 ChatGPT 的回答能根据自己本地的文档,或者其他的一些数据源来回答,但 ChatGPT 回答的数据来自于训练时的数据(比如现在是截止到 2022 的数据),不能使用其他的数据。那我们可以将数据和问题一起输入,比如给出这样的 prompt
text复制代码【这里是某些数据源...】
请根据上面的信息,回答我的问题,如果上面的信息得不出答案,请回答:”没有足够的信息“,那么我的问题是:xxxxx
这样的方案是可行的,但前提是数据源的数据不能太多,ChatGPT 携带的上下文有限,假设我们希望将一本书的内容作为上下文,然后让其根据书中的内容来回答是不行,ChatGPT 一次能支持输入的长度有限。而且每次提问将一大段内容贴进去,也不现实。
那么是否可以只将和问题相关的内容提取出来作为上下文输入呢?这样既可以减少数据源,还能让 ChatGPT 根据这些内容取分析总结出想要的回答。
那么问题就变成了如何根据想要问的问题,从书中检索出相关的内容,这其实就是搜索引擎做的事情。具体的做法就是将这本书的内容通过某些格式保存到数据库中,然后每次提问的时候,先取数据库检索相关的内容,然后将内容和问题按照类似上面的 prompt 提交给 ChatGPT,经过 ChatGPT 来生成高质量的回答。而这个保存了书内容的数据库就是外挂知识库。
其中保存到数据库的过程是对原文本进行 Tokenizer(分词) + Embedding(向量化),数据库则称为 Vector Store (向量数据库)
整个过程如下: 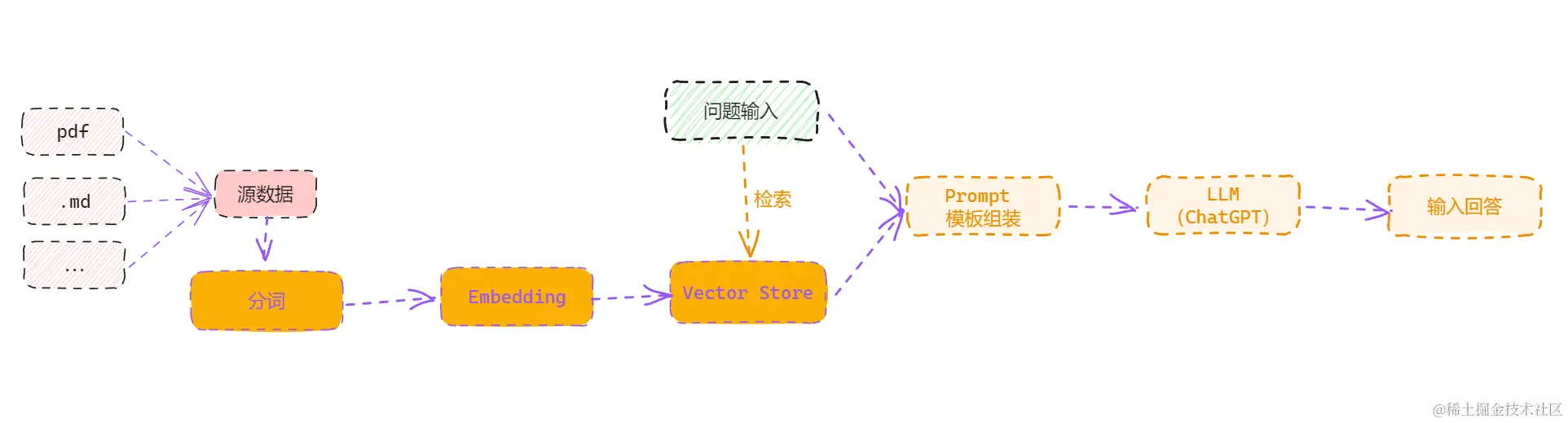
名词解释:
- 分词(Tokenizer): 将文本拆分成单个单词或词语,结构化为计算机可以处理的结构化形式,,比如 我每天六点下班 可以拆分为 “我”,“每天”,“六点下班”,常见的分词器有 markdown 分词器 MarkdownTextSplitter
- 向量化(Embedding):将文本数据转换为向量的过程。计算机无法直接处理文本,因此需要将文本转换为数学向量形式,以便算法能够理解和处理。文本和数学向量之间互相映射,但数学向量更便于计算机运算。对中文比较友好的向量模型库有 shibing624/text2vec-base-chinese
- 向量数据库(Vector Store): 存储和管理向量化后的文本数据的数据库,能快速检索相似文本或进行文本相似性比较。 比如 FAISS 这个库
方案选择
目前已经有许多开源的方案,也有许多商业化的方案&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









