







MobileNet出现原因
在真实应用场景或嵌入式设备中,需要延迟较低,响应速度较快的模型。
实现目的的两个方向:
- 对训练好的复杂模型进行压缩得到小模型。
- 直接设计小模型并进行训练。
MobileNet属于第二种实现方式。
MobileNet网络结构
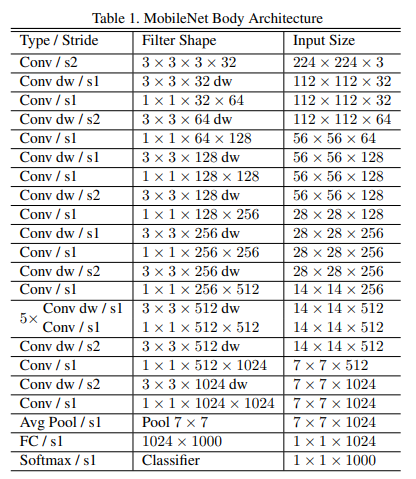
以上为MobileNet的整体结构,总体是由Conv结构于Conv dw结构堆叠而成。
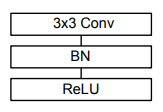
以上为Conv结构。

以上为Conv dw结构。
MobileNet首先是经过一个3 × 3的标准卷积,然后堆叠depthwise separable convolution结构,最后通过平均池化将feature变成1 × 1,进行全连接,最后连接上一个softmax。
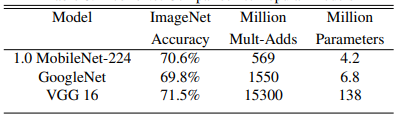
相比其他网络,其虽然准确率有所降低,但参数量明显降低。
以下是我仿照实现的MobileNet:
def relu6(x): return K.relu(x=x, max_value=6) def conv(inputs, filters, kernel_size=3, strides=1, layer_num=0): x = Conv2D(filters=filters, kernel_size=kernel_size, strides=strides, padding='same', use_bias=False, name="conv_%d"%layer_num)(inputs) x = BatchNormalization(name="conv_batchnormalization_%d"%layer_num)(x) x = Activation(relu6, name="conv_activation_%d"%layer_num)(x) return x, layer_num + 1 def conv_ds(inputs, pointwise_conv_filters, depth_multiplier=1, strides=1, layer_num=0): x = DepthwiseConv2D(kernel_size=3, depth_multiplier=depth_multiplier, strides=strides, padding='same', use_bias=False, name="dp_conv_%d"%layer_num)(inputs) x = BatchNormalization(name="dp_conv_batchnormalization_%d"%layer_num)(x) x = Activation(relu6, name="dp_conv_activation_%d"%layer_num)(x) x, layer_num = conv(inputs=x, filters=pointwise_conv_filters, kernel_size=1, strides=1, layer_num=layer_num + 1) return x, layer_num def MobileNet(inputs, embedding=128, dropout_keep_prob=0.4, depth_multiplier=1, layer_num=0): # 160,160,3 -> 80,80,32 x, layer_num = conv(inputs, filters=32, strides=2, layer_num=layer_num) # 80,80,32 -> 80,80,64 x, layer_num = conv_ds(x, pointwise_conv_filters=64, depth_multiplier=depth_multiplier, layer_num=layer_num) # 80,80,64 -> 40,40,128 x, layer_num = conv_ds(x, pointwise_conv_filters=128, depth_multiplier=depth_multiplier, strides=2, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=128, depth_multiplier=depth_multiplier, layer_num=layer_num) # 40,40,128 -> 20,20,256 x, layer_num = conv_ds(x, pointwise_conv_filters=256, depth_multiplier=depth_multiplier, strides=2, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=256, depth_multiplier=depth_multiplier, layer_num=layer_num) # 20,20,256 -> 10,10,512 x, layer_num = conv_ds(x, pointwise_conv_filters=512, depth_multiplier=depth_multiplier, strides=2, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=512, depth_multiplier=depth_multiplier, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=512, depth_multiplier=depth_multiplier, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=512, depth_multiplier=depth_multiplier, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=512, depth_multiplier=depth_multiplier, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=512, depth_multiplier=depth_multiplier, layer_num=layer_num) # 10,10,512 -> 5,5,1024 x, layer_num = conv_ds(x, pointwise_conv_filters=1024, depth_multiplier=depth_multiplier, strides=2, layer_num=layer_num) x, layer_num = conv_ds(x, pointwise_conv_filters=1024, depth_multiplier=depth_multiplier, layer_num=layer_num) # cbam = cbam_block(x) # x = Concatenate(axis=3, name="attention_concatenate_%d"%layer_num)([x, cbam]) # layer_num = layer_num + 1 # 1024 Pooling x = GlobalAveragePooling2D(name="global_average_pooling_%d"%layer_num)(x) # dropout x = Dropout(1 - dropout_keep_prob, name="mobile_net_dropout_%d"%(layer_num+1))(x) # 全连接 x = Dense(embedding, use_bias=False, name="mobilenet_dense_%d"%(layer_num+2))(x) x = BatchNormalization(momentum=0.99, epsilon=10e-6, scale=False, name="mobile_net_batchnormal_%d"%(layer_num+3))(x) # 创建模型 model = Model(inputs, x) return model















 1631
1631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









