






第6章 MAML
-
基本思想:找到在多个相关任务中共同最优参数,使得在新任务时能快速到达最优。
方法:在内循环中,通过对n个训练任务训练找到n个最优参数;外循环中,计算n个元训练任务(不同于刚刚训练任务)相对于最优参数的梯度,更新初始化参数。 -
tensorflow实现
看代码的时候有过一个问题,为什么求梯度是:
gradient = np.matmul(XTrain.T, (YHat - YTrain)) / self.num_samples
后来发现,是因为使用了交叉熵损失函数和sigmoid函数,二者组合,再求偏导,会得到非常elegant的结果:
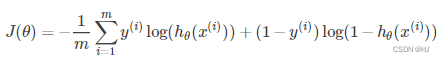
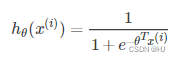

-
对抗式元学习ADML
·对抗学习是为了增强模型的鲁棒性。比如在视觉场景中,对输入图片增加一点点扰动,对于人来说,输入是没有发生改变,但是机器却打上了不同的标签,这种情况下是不合理的。因此,对抗学习使用干净样本和对抗样本同时训练,来增强稳健性。
·快速梯度符号法FGSM:该方法认为攻击就是添加扰动使得模型的loss增大,所以沿着梯度方向生成攻击样本应该是最佳的
为了得到对抗样本,计算相对于图像输入(x,而不是θ)的损失梯度。计算梯度后,取sign值。
·ADML:分别对干净样本和对抗样本进行元学习参数更新,最后的参数结果用θ同时-两个结果
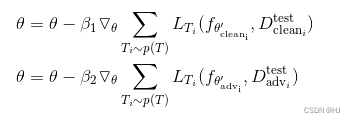
-
CAML
·将模型参数一分为二:上下文参数(context)和共享参数(shared)。
上下文参数在内循环中根据任务变化,而共享参数任务之间共享并用于外循环的元训练。可避免对特殊任务过度拟合,激素学习,提高存储器使用效率。















 1758
1758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









