pink JS基础语法+JavaScript核心教程+阮一峰JS基础
JS基础语法
- JS三种书写位置:行内、内嵌、引入式。
- 单行注释 ctrl+/ 多行注释 shift + alt +a
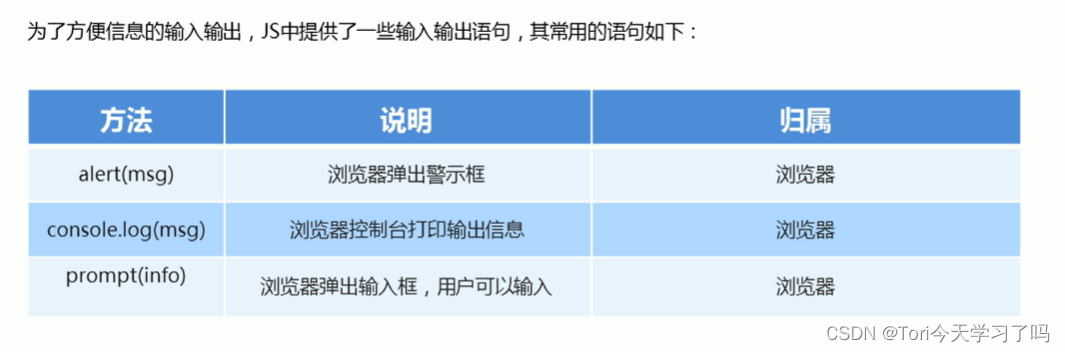
- 输入输出语句
- 声明变量 var age;变量命名规范:字母、数字、下划线、美元符号组成,区分大小写,不能数字开头,不能是关键字保留字,驼峰命名法。
- 声明变量的本质是去内存申请空间。
- JavaScript 是一种动态类型语言,也就是说,变量的类型没有限制,变量可以随时更改类型。JavaScript 内部,所有数字都是以64位浮点数形式储存,即使整数也是如此。所以,1与1.0是相同的,是同一个数。
- JS把数据类型分为两类:
- 简单数字类型(数字型<八进制前加0/十六进制前加0x、布尔型、字符串类型、undefined
- 复杂数字类型 - JavaScript 有三种方法,可以确定一个值到底是什么类型。typeof运算符/instanceof运算符/Object.prototype.toString方法
- 数字类型转换:
- 转换字符串:变量.toString()/加号拼接字符串/join(分隔符)
- 转换数字型:parseInt(var) / parseFloat(var) / Number(str) /进制转换
- eg: parseInt(‘1000’, 2) // 8
- 转换成布尔型:Boolean(var) (代表空、否定的值会被转换为false - 逻辑运算
- 逻辑与短路运算 111&& 456 (表达式1结果为真,返回表达式2)
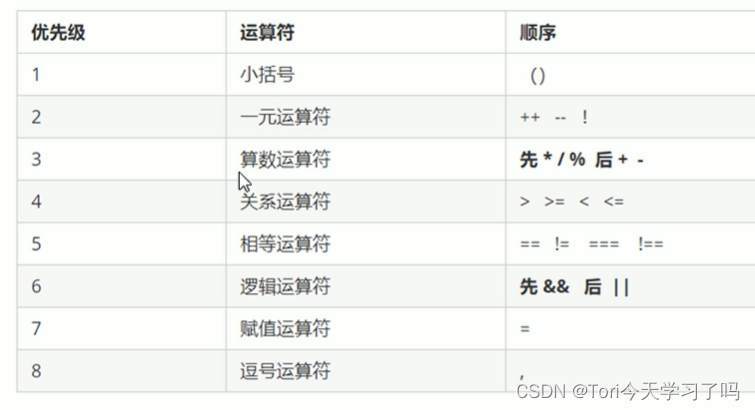
- 逻辑或短路运算 123 &&456 (表达式1结果为真,返回表达式1) - 运算符优先级
- 判断NaN更可靠的方法是,利用NaN为唯一不等于自身的值的这个特点,进行判断.
- 数组 var arr = new Array();var arr = [ ];本质上,数组属于一种特殊的对象。typeof运算符会返回数组的类型是object。数组的特殊性体现在,它的键名是按次序排列的一组整数(0,1,2…)。
- 函数
- 当我们不确定有多少个参数传递的时候,可以用arguments来获取。在JavaScript中,arguments实际上它是当前函数的一个内置对象,arguments对象中存储了传递的所有实参。伪数组
- 如果在函数内部,没有声明直接赋值的变量也属于全局变量。
- “立即调用的函数表达式”(Immediately-Invoked Function Expression),简称 IIFE
(function(){ }());
(function(){ })();
- 只对**匿名函数**使用这种“立即执行的函数表达式”。它的目的有两个:一是不必为函数命名,避免了污染全局变量;二是 IIFE 内部形成了一个单独的作用域,可以封装一些外部无法读取的私有变量。
- 函数的toString()方法返回一个字符串,内容是函数的源码。对于那些原生的函数,toString()方法返回function (){[native code]}。
- 预解析:js引擎会把js里面所有的var还要function提升到当前作用域的最前面。(变量预解析/函数预解析)
- 对象:一组无序相关属性和方法的集合,所有的事物都是对象,例如字符串、数值、数组、函数等。对象是由属性和方法组成的。var obj = new Object();
- 遍历对象for (var k in obj){ }
- 对象:自定义对象、内置对象(Math、Date、Array、String)、浏览器对象.
- Math

- 获得现在距离1970-1-1总的毫秒数
var data1 = +new Data();
console.log(data1);
- 判断是不是数组 instanceof Array/ Array.isAaary
- 添加删除数组

- 数组排序
arr1.sort(function(a,b){
return b-a;
});
- 数组索引:arr.indexOf();数组中查找给定元素的第一个索引;arr.lastIndexOf();数组中最后一个的索引;
- 数组去重
function unique(arr){
var newArr = [];
for (var i=0;i<arr.length;i++){
if(newArr.indexOf(arr[i] ===-1){
new.Arr.push(arr[i]);
}
}
return newArr;
}
- 根据位置返回字符


Web APIs
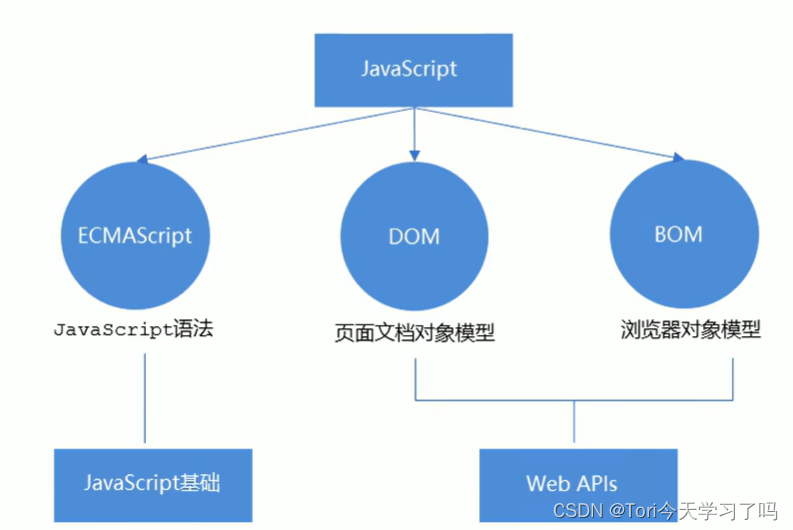
- JS的组成
- 获取页面元素
- 根据id获取:getElementByld()
- 根据标签名获取:getElementsByTagName('标签名‘);
- 通过HTML5新增的方法:document.getElementsByClassName('类名‘);document.querySelector('选择器’);document.querySelectorAll('选择器’);

- 事件三元素:事件源、事件类型、事件处理程序。执行事件步骤1.获取事件源2.绑定事件 注册事件3.添加事件处理程序。
- innerText不识别Html标签 非标准 去除空格和换行;innerHTML识别html标签,W3C标准,保留空格和换行;两个属性可读写,可以获取元素里面的内容。
- 阻止链接跳转,链接地址那里写:javascript:;
- 动态创建元素的区别

- 注册事件/绑定事件:传统方式(唯一性)and方法监听注册方式(addEventListen())
- DOM事件流分为三个阶段:捕获阶段-当前目标阶段-冒泡阶段 ,实际开发中很少用事件捕获,更关注事件冒泡。有些事件是没有冒泡的,比如onblur、onfocus、onmouseenter、onmouseleave
- e.target返回的是触发事件的对象(元素),this返回的是绑定事件的对象(元素)。
- 事件委托原理不是每个子节点单独设置事件监听器,而是事件监听器设置在其父节点上,然后利用冒泡原理影响设置每个子节点。
- BOM ( Browser Object Model )即浏览器对象模型,它提供了独立于内容而与浏览器窗口进行交互的对象,其核心对象是 window。BOM由一系列相关的对象构成,并且每个对象都提供了很多方法与属性。
- 两种定时器:window.setTimeout();setInterval();(serInterval—每隔ns重复调用)清除定时器:clearTimeout(timeoutId);
- 立即执行函数:不需要调用,立马能够自己执行的函数。(function(){})()
- mouseenter和mouseover的区别

移动端网页
- 移动端touch触摸:touchstart/移动:touchmove/离开:touchend/拖动坐标:targetTouches[0]里面的PageX 和PageY
- 插件 swiper/superslide/iscroll 视频插件:zy.media.js
- 本地存储sessionStorage.setItem/getItem/removeItem/clear || localStorage
- 数据可视化:ECharts.js/Highcharts.js
- 边框图片:border-image-slice/border-image-repeat
《你不知道的JavaScript》
作用域是什么
- 编译一般会经历三个步骤:
- 分词/词法分析:将字符串分解成有意义的代码块。分词(tokenizing)和词法分析(Lexing)之间的区别是非常微妙、晦涩的,主要差异在于词法单元的识别是通过有状态还是无状态的方式进行的。分词(tokenizing)和词法分析(Lexing)之间的区别是非常微妙、晦涩的,主要差异在于词法单元的识别是通过有状态还是无状态的方式进行的。(?不太懂,有空查下)
- 解析/语法分析(Parsing):这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树。这个树被称为“抽象语法树”(Abstract Syntax Tree, AST)。
- 代码生成:将AST转换为可执行代码的过程被称为代码生成。这个过程与语言、目标平台等息息相关。
- LHS和RHS的含义是“赋值操作的左侧或右侧”并不一定意味着就是“=赋值操作符的左侧或右侧”。【赋值操作还有其他几种形式,因此在概念上最好将其理解为“赋值操作的目标是谁(LHS)”以及“谁是赋值操作的源头(RHS)”。】
换句话说,**当变量出现在赋值操作的左侧时进行LHS查询,出现在右侧时进行RHS查询。**讲得更准确一点,RHS查询与简单地查找某个变量的值别无二致,而LHS查询则是试图找到变量的容器本身,从而可以对其赋值。 - 然而还有一个重要的细微差别,编译器可以在代码生成的同时处理声明和值的定义,比如在引擎执行代码时,并不会有线程专门用来将一个函数值“分配给”foo。因此,将函数声明理解成前面讨论的LHS查询和赋值的形式并不合适。
- 为什么区分LHS和RHS是一件重要的事情?
因为在变量还没有声明(在任何作用域中都无法找到该变量)的情况下,这两种查询的行为是不一样的。如果RHS查询在所有嵌套的作用域中遍寻不到所需的变量,引擎就会抛出ReferenceError异常。值得注意的是,ReferenceError是非常重要的异常类型。相较之下,当引擎执行LHS查询时,如果在顶层(全局作用域)中也无法找到目标变量,全局作用域中就会创建一个具有该名称的变量,并将其返还给引擎,前提是程序运行在非“严格模式”下。ReferenceError同作用域判别失败相关,而TypeError则代表作用域判别成功了,但是对结果的操作是非法或不合理的。
词法作用域
























 1269
1269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









