







 该博客介绍了如何进行五类花卉的识别,包括数据集的处理、划分,网络结构的构建,损失函数和学习率的设定,模型训练与存储,效果评估以及使用QT界面进行结果展示。
该博客介绍了如何进行五类花卉的识别,包括数据集的处理、划分,网络结构的构建,损失函数和学习率的设定,模型训练与存储,效果评估以及使用QT界面进行结果展示。
花卉识别–五个类别的检测
文章目录
一、数据集的观察与查看
一个五个类别,每个
 在这里插入图片描述
在这里插入图片描述




在这里插入图片描述
每个类别大概有650张图片,则将每个图片对应的文件夹按照七三或者八二分成训练集合测试集
注意对于,每张图片的大小都是不同的,所以要先对图片的尺寸进行**resize(),**使得每张图片的大小都一样
对于数据的扩展,可以将图片进行旋转、图片亮度的调节、图片模糊处理等,这样的可以使得你在测试的时候不管你属于的图片质量怎么样,你都能够正确识别出图片的内容
二、将数据集分为data_train(训练集)和data_test(测试集)
#path 图片文件夹的路径
def read_img(path):
cate=[path+x for x in os.listdir(path) if os.path.isdir(path+x)]
imgs=[]
labels=[]
for idx,folder in enumerate(cate):
for im in glob.glob(folder+'/*.jpg'):
print('reading the images:%s'%(im))
img=io.imread(im)
img=transform.resize(img,(w,h))
imgs.append(img)
labels.append(idx)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
data,label=read_img(path)
#打乱顺序
#将图片的保存的顺序打乱
num_example=data.shape[0]
arr=np.arange(num_example)
np.random.shuffle(arr)
data=data[arr]
label=label[arr]
#这里将文件八二分,对文件进行处理
#将所有数据分为训练集和验证集
ratio=0.8
s=np.int(num_example*ratio)
x_train=data[:s]
y_train=label[:s]
x_val=data[s:]
y_val=label[s:]
缺点:
-
上述代码并没有图片保存到我们自己建立的数据集中,只是存放在内存中也就是说我们每次运行程序都需要重新制作我们的数据集,这样非常的耗费时间,但是如果我们将我们的数据集存到一个文件当中,我们每次直接读取文件就可以,无需再重新设置标签、打乱顺序等繁琐操作。我们直接可以从文件中读取到一个矩阵
-
我们在制作数据集的时候,很少会将图片和标签进行分开的储存,通常我们会直接保存在一个data_train、data_test。我们将数据的标签和特征储存在一个列表当中,并不分开储存
[ [[img1],lable1] [[img2],lable2] [[img3],lable3] [[img4],lable4] [[img5],lable5] [[img6],lable6] ]
三、明确网络流程、建立网络结构
我们推荐的参考链接的代码流程
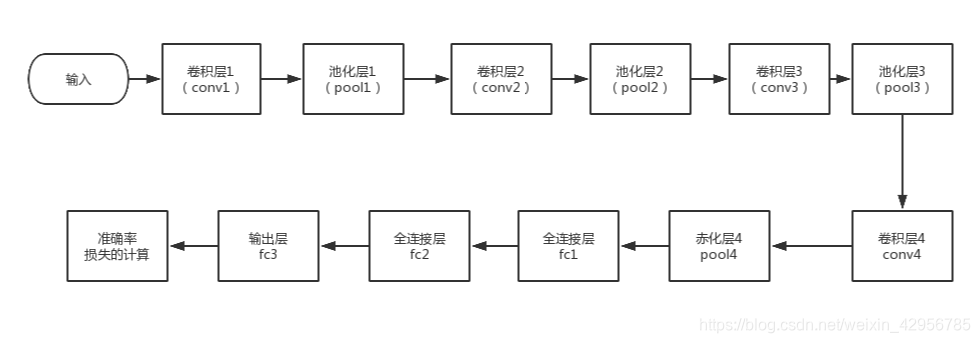
则这个网络基本上就是整个网络的流程,但在代码中,有一些对数据进行非线性激活函数activation function、正则化(BN)等操作并没有列在上面,在大家答辩的时候,最好要弄懂每一步的维度变化
#占位符
x=tf.placeholder(tf.float32,shape=[None,w,h,c],name='x')
y_=tf.placeholder(tf.int32,shape=[None,],name='y_')
def inference(input_tensor, train, regularizer):
with tf.variable_scope('layer1-conv1'):
#-----卷积核kernel的权重的初始化----------
conv1_weights = tf.get_variable("weight",[5,5,3,32],initializer=tf.truncated_normal_initializer(stddev=0.1))
#-------偏置项的初始化-----------------------
conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0))
#----------卷积函数-----------------------
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
#-------------------激活函数----------------
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("layer2-pool1"):
#--------------------池化函数----------------
pool1 = tf 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









