






文献来源:A. Sharma, E. Vans, D. Shigemizu, K.A. Boroevich, T. Tsunoda, DeepInsight: A methodology to transform a non-image data to an image for convolution neural network architecture, Sci. Rep. 9 (1) (2019) 1–7.
此文为3.5的参考文献[23]
代码
数据集
摘要
捕捉基因组或其他区分表型或类别的数据中的微小变异是至关重要的,但也是困难的。有大量的数据可用,但其基因或元素的信息是任意分布的,这使得提取相关细节以进行鉴定具有挑战性。然而,将相似的基因排列成簇使得这些差异更容易接近,并且允许对隐藏机制(例如途径)的强大识别,而不是单独处理元素。在这里,我们提出了DeepInsight,它将非图像样本转换为组织良好的图像形式。因此,卷积神经网络(CNN)的力量,包括GPU的利用率,可以在非图像样本中实现。此外,DeepInsight通过应用CNN对非图像样本进行特征提取,以获取必要的信息,并显示出令人满意的结果。据我们所知,这是第一次将CNN同时应用于不同类型的非图像数据集:RNA-seq、元音、文本和人工数据集。
1 Introduction
在后基因组时代,尽管大量数据是可访问的,但这些信息不分青红皂白地分布在高维数据空间中,这使得区分表型变得具有挑战性。 将相关特征与类标签相关联的问题同样存在于其他类型的数据(例如元音、文本)中。以适当的方式排列元素变得至关重要,这样可以提取相关特征进行分析。因此,通过对元素进行正确的排序和定位,为后续步骤排列信息成为一个重要的阶段。我们把这个阶段称为元素排列步骤。 表型或分类标签的识别或分类可以通过三个步骤得到改进:元素排列、特征提取和开发合适的分类器。
传统的机器学习(ML)技术用于分类或检测问题,需要一个特征向量形式的样本(即,大小为p×1的列向量)。 从特征提取技术得到的特征向量经过处理后被分类到一个定义的组中。这种向量形式的特征通常被ML技术认为是相互独立的(特别是在外观顺序上)。因此,改变特征的顺序对分类或表型检测没有直接影响,这使得元素排列步骤对于许多最先进的ML分类器(如随机森林1,2和决策树3)来说是多余的。
另一方面,来自深度神经网络的卷积神经网络(CNN)架构接受样本作为图像(即大小为m×n的矩阵),并通过隐藏层(如卷积层、RELU层、最大池化层)进行特征提取和分类。它不需要额外的特征提取技术,因为它会自动从原始元素中提取特征。 第二个优点是它可以找到图像的高阶统计量和非线性相关性。
第三,卷积神经元对其接受域或受限子区域的数据进行处理,从而减少了对大输入尺寸的大量神经元的需求,从而使网络能够以更少的参数深度得多。 CNN的另一个显著属性是权重共享;例如,许多接受域共享相同的权重和偏差(或过滤器),与传统神经网络相比,可以减少内存占用。 CNN架构允许有效地处理图像,并成为工业应用(如无人驾驶汽车)精度的承诺。图像由局部区域的空间相干像素组成;也就是说,彼此靠近的像素共享相似的信息。 随后,各个像素的定位如果随意排列,会对CNN架构的特征提取和分类性能产生不利影响。因此,CNN利用的图像中相邻像素的顺序不再像ML技术那样独立。当CNN采用一组相邻像素时,额外的信息被捕获,而不是ML技术单独使用特征。成功也要归功于GPU等硬件的进步,这使得非常复杂的模型能够以更快、更实惠的方式进行训练。此外,新的深度学习架构和库的发展使模型能够快速构建和学习。幸运的是,对于CNN来说,捕获的图像通常是对物理对象的描述,不需要重新排列像素,因为相机镜头将相应的物体阴影正确地放置在像素上。
基因组学、转录组学、甲基化、突变、文本、口语、金融和银行等许多数据都是非图像形式的(也称为表格数据或者整齐数据),ML技术在这些领域占有主导地位。 此外,CNN不能使用,因为它需要图像作为输入。但是,如果我们可以将非图像数据转换为组织良好的图像形式,那么CNN就可以获得更高的分类性能。为此,我们需要开发一种能够有效执行元素排列的方法。 为了提高检测率,我们在提出的DeepInsight方法中整合了元素排列、特征提取和分类这三个步骤。 DeepInsight通过将相似的元素或特征放在一起,将不相似的元素或特征分开,从而可以集体使用相邻元素来构建图像。这种元素排列的集体方法在揭示隐藏机制(例如路径)或理解一组特征(例如文本,元音)之间的关系时非常有用。因此,通过插入相似的特征(或原始元素)作为聚类来转换图像比处理单个特征(忽略邻域信息)更有意义和鲁棒性,因为可以集成重要信息(来自弱元素)。这有可能探索特征对目标或结果的相对重要性。元素排列是打开关键信息的钥匙。考虑从给定数据集中检索更多信息的策略是相关的。 此外,DeepInsight可以利用CNN进行特征提取和分类。 这将增加CNN的通用性,将其开放给非图像情况,从而提供CNN的广义结果。 我们在论文中表明,DeepInsight对基因表达、元音、文本和人工数据等各种数据都很有用。(所以可以将其试着使用在室内定位中。)
已经提出了不同版本的cnn来有效地处理图像5-16。例如,He等人8提出了一种残差网络架构,使训练非常深度的网络变得更容易。他们在ImageNet数据集上使用了152层深度残差。Singh等人17开发了基于CNN的技术,使用组蛋白修饰数据作为输入对基因表达进行分类。 Liu et al. 18以肿瘤基因表达样本为列载体,采用一维CNN进行分类。他们没有将样本转换成图像。Zeng等19利用CNN从原位杂交基因表达模式中提取特征。输入样本为自然图像。Gao等人20使用DNA序列并将其转换为四维二进制代码。这些二进制代码按照DNA序列排列,然后应用于CNN来预测聚腺苷化位点。 Xu等人21将CNN应用于文本哈希,将文本转换成二进制编码,然后送入一维卷积;也就是说,这些特征在卷积层中不再被视为图像。 Zhang等人22将文本视为原始信号,并应用一维CNN进行分类。
Lyu和Haque23最近将CNN应用于RNA-seq数据,首先进行基因选择,然后基于染色体定位构建图像。该方法可能是第一个将基因表达转化为图像样本并应用CNN进行分类的方法。由于该方法需要染色体位置信息,因此不可能将其用于其他类型的数据集。
上面讨论的大多数方法要么是将图像作为CNN的输入,要么是使用一维CNN。因此,将非图像样本普遍转化为图像用于CNN应用的文献很少。
2 Results
2.1 Experimental setup
我们使用了四种不同类型的数据集来测试DeepInsight方法,并将其获得的结果与最先进的分类器进行了比较。有1个基因表达数据集、1个文本数据集、1个元音数据集和2个人工数据集。主要目标是通过实现DeepInsight方法,利用CNN架构可以处理非图像数据。
本研究考虑的数据集首先分别以80:10:10的比例细分为训练集、验证集和测试集。在训练集上对模型进行拟合,在验证集上对模型的适应度进行评价。选择验证误差最小的超参数。该测试集从未用于训练或模型校正步骤。在测试集中计算分类精度,以提供对最终模型的无偏评估,其中分类精度定义为从测试集中正确分类的样本数量的百分比。
2.2 Comparison and classification performance.
为了进行比较,使用了现有的最先进的分类器,如随机森林、决策树和ada-boost。采用网格搜索优化方法对竞争方法的超参数进行优化。如第4.3节和补充文件1所讨论的,DeepInsight方法采用两种类型的归一化(norm-1和norm-2),并且对这两种规范评估验证误差。给出最低验证错误的规范用于进一步处理。像素帧大小固定为120 × 120。然而,对于RNA-seq数据集,由于元素或特征的数量非常大(60483),与本工作中研究的其他数据集相比,导致有损压缩(如补充文件2所述),因此分析是在200 × 200像素大小上进行的。在执行DeepInsight后,所有数据集的两种规范的验证错误都在补充文件3中描述。验证集上的最佳拟合模型用于评估单独测试集上的性能。
这种比较的目的是表明DeepInsight也可以在不同类型的数据集上产生具有竞争力的性能。分类精度方面的性能如表2所示(有关代码的简要讨论,请参阅补充文件4)。

DeepInsight在RNA-seq数据测试集上产生99%的分类准确率,比最先进的随机森林方法高出3%。对于元音数据集,DeepInsight的分类准确率为97%,而随机森林的分类准确率为90%。这种改善比本研究中表现最好的现有方法提高了约7%。接下来,在文本数据上,DeepInsight获得了92%的准确率,而随机森林方法的准确率为90%。同样的趋势也可以在人工数据集中发现:Madelon和环ringnorm。在Madelon上,DeepInsight获得了88%,在ringnorm上获得了98%。与第二好的技术相比,分别提高了23%和4%。计算了5个数据集的平均分类精度。Ada-boost方法的平均分类准确率为73%,决策树分类准确率为80%,优于Ada-boost方法。随机森林达到了86%,是现有研究技术中最好的,而DeepInsight的平均分类准确率为95%,明显优于第二好的方法。
3 Discussion
正如预期的那样,提出的DeepInsight方法产生了非常有希望的结果。获得的结果使我们能够将CNN架构用于各种非图像数据集。这增加了利用深度学习网络的可能性。人们可以设想将这种算法应用于各种各样的应用的巨大可能性。
在这项工作中,我们能够通过DeepInsight方法的初始化来整合CNN对非图像样本的许多属性。一个非图像样本,以向量的形式变换成有意义的图像进行CNN处理。这一策略并不能解决基因组数据的所有问题,但它在整合CNN的优点方面向前迈进了一步。深度神经网络架构包含许多优点:特征提取、降维,从稀疏和超维数据中寻找隐藏结构,数据增强和上采样,标记/非标记样本的半监督学习,以及时间序列数据的最佳行动选择29。因此,在更广泛的背景下,深度神经网络架构有潜力为从DNA序列到蛋白质序列(可被视为时间序列数据)到RNA-seq或组学数据等各种输入样本的基因组分析提供解决方案。
DeepInsight方法增加了CNN架构的通用性。CNN的特点,如自动特征提取,减少对神经元的需求,从而能够更深入地训练模型,权值共享能力,以减轻内存需求,邻域信息的利用(即一次处理像素帧的子区域),以及GPU的利用,使CNN成为分类和分析的有力工具。该技术将CNN的这些属性用于非图像情况。此外,我们已经在几种数据集上展示了DeepInsight的有效性,并获得了非常有希望的结果。对于RNA-seq数据,DeepInsight实现的最大分类准确率为99%。对于元音、文本、马德隆和环模,准确率分别为97%、92%、88%和98%。
可以考虑对当前版本的算法进行进一步扩展。目前的技术采用灰度或单层(即二维矩阵)进行分类。它可以扩展到包含多个层,因此也可以应用于解决与多组学数据相关的问题(例如,基因表达、甲基化、突变)。此外,不同类型的数据(如临床和非临床)可以归一化为单层(如果由于计算资源而禁止多层)进行分析和分类。这种技术对于数据不是图像形式的许多应用程序都很有用。
4 Method
4.1 DeepInsight method
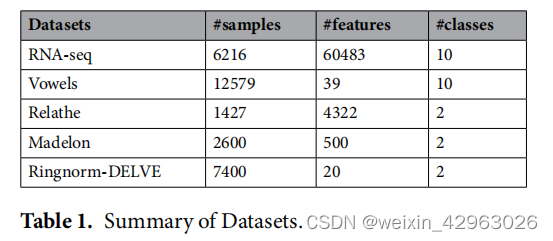
DeepInsight的概念是首先将非图像样本转换为图像形式,然后将其提供给CNN架构以进行预测或分类。图1a给出了一个简单的例子,其中由基因表达值组成的特征向量x通过变换t转换为特征矩阵M。特征在笛卡尔坐标中的位置取决于特征的相似性。例如,图1a中特征g1、g3、g6和gd之间的距离更近。一旦在特征矩阵中确定了每个特征的位置,则表达式值或特征值被映射。这将为每个样本(或特征向量)生成一个唯一的图像。d个特征的N个样本将提供m×n特征矩阵的N个样本。这个二维矩阵形式会有所有的d个特征。然后,将这组N个特征矩阵处理到CNN架构中学习模型并提供预测。
如果由于硬件的限制,数据维数非常大,难以处理,那么在应用DeepInsight之前可以考虑使用降维技术(Dimensionality Reduction Technique,DRT)。DRT可以是特征选择的形式,也可以是特征提取的形式,这取决于问题的性质。DRT的应用将提供一个小的特征集,这将有助于更快的处理,但是,可能会影响分类性能。另一方面,如果去除噪声或冗余特征,则有助于获得更高的处理速度和更高的精度。由于DRT的应用依赖于案例,我们在不应用DRT的情况下描述了DeepInsight。
4.2 DeepInsight pipeline
图1b描述了这种转换的总体概况。训练集用于寻找特征的位置。
如果由n个样本组成的训练集定义为 χ={x1, x2, …, xn},其中一个特征向量有d个特征 ,那么我们也可以定义一个基因或特征集G={g1, g2,…,gd},即,一个特征gj有n个训练样本。
基本上,G可以通过x的转置得到。我们使用这个特征集G,并应用相似度测量技术或降维技术如t-SNE30或核主成分分析(kPCA)获得二维平面(t-SNE和核主成分分析详见补充文件5)。这些都是非线性降维技术。一些线性降维技术也存在,但没有在本工作中实现(31 - 34)。
这个笛卡尔平面上的点是特征或基因。这些点只定义特征的位置,而不是特征本身或表达式值。一旦特征的位置被定义,凸包算法被用来寻找包含所有点的最小矩形。由于对于CNN架构,图像应该以水平或垂直形式进行构建,因此执行旋转。然后,将笛卡尔坐标转换为像素。由于图像大小有像素限制,从笛卡尔坐标到像素帧的转换是通过平均一些特征来完成的。因此,像素帧将由样本xj(对于j= 1,2,…,n)的特征(或基因)位置组成。一旦确定了位置,下一步就是将特征(或基因表达)值映射到这些像素位置。如果多个特征在像素帧中获得相同的位置,则在特征映射期间,将各自的特征平均并放置在相同的位置。
因此,如果图像的分辨率或网格大小非常小(与给定的特征数量相比),那么许多特征相互重叠,图像表示可能不是很准确。应该根据硬件容量和需要处理的特性数量选择适当的分辨率。或者,可以先验地应用降维。有关程序的详情载于补充文件6。
4.3 Feature normalization
图像的单层有256个阴影,在[0,1]的范围内归一化。因此,在进行图像变换之前,需要对特征值进行归一化处理。
在这项工作中,我们进行了两种类型的归一化:(1)假设每个特征是独立的,因此通过其最小值和最大值进行归一化;(2)通过使用整个训练集中的一个最大值进行归一化,在一定程度上保留了相互特征的拓扑结构。这些规范化在补充文件1中有详细的解释。DeepInsight在两种归一化类型上评估验证集的性能,并接受验证错误最低的那一种。
4.4 CNN architecture
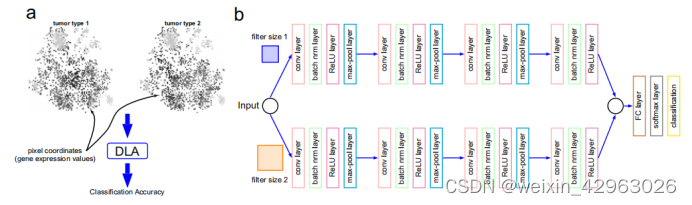
图2 DeepInsight网络:一个例子。使用DeepInsight方法的图像变换方法对两种类型的肿瘤进行说明。两种类型之间的差异可以在不同的点上可视化。将这些图像样本进一步处理为深度学习架构(DLA);即同图b部分所示的平行CNN。(b) DeepInsight中使用的并行CNN架构。该架构由两个并行的CNN架构组成,每个架构由四个卷积层组成。参数使用贝叶斯优化技术进行调优。
我们开发了一个并行的CNN架构,以便不同的过滤器大小可以有效地用于训练模型。我们的CNN架构如图2b所示。在这个架构中,我们有四个并行层,其中每一层由一个2D卷积层、一个批处理规范化层、一个ReLU激活层和一个最大池化层组成。批处理归一化用于防止训练过程中的过滤波,最大池化层用于对每层的图像大小进行降采样。第四个卷积层的输出(在并行架构中)被组合并馈送到一个完全连接的层。最后,使用SofMax层将输出作为类标签。
DeepInsight的CNN架构有各种超参数,如卷积层、滤波器大小、学习率等。我们通过对所有试验应用贝叶斯优化技术来调整这些超参数。我们获得了一组在验证集上提供最佳性能的超参数。在补充文件2和补充文件3中讨论了训练阶段的参数细节和验证误差。一旦使用最优超参数训练CNN模型,那么任何新样本都可以被识别到其中一个类别或类中。















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









