







此帖用于本人课程学习报告的支撑材料。
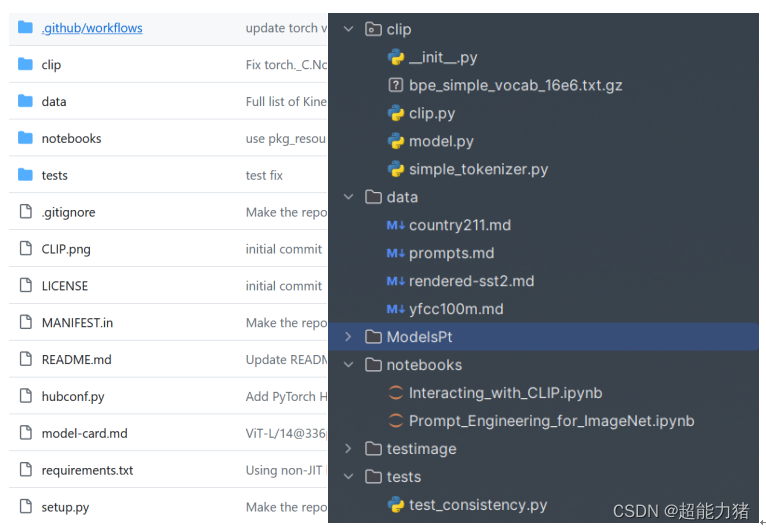
CLIP在github上的代码目录如下图 (左)所示,目录的展开图如下图 (右)所示,CLIP代码的模型部分在/clip文件夹下的model.py文件中,这个文件是后面重点剖析对象。/date文件夹下面为一些说明文件,/notebooks文件夹下是一些关于如何测试CLIP的教程。/ModelPt文件夹下是作者预训练的一些模型,是本地部署的时候下载加入的,在github上的代码没有这部分。
from collections import OrderedDict
from typing import Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
#----------------------------------------------#
# ModifiedResNet50中标准残差结构--Bottleneck的定义
#----------------------------------------------#
class Bottleneck(nn.Module):
'''
Bottleneck,一种特殊的残差结构,下面这个使用的是1x1——3x3——1x1的卷积层的组合,
一般在深度较高的网络(如resnet101)中使用。
主要目的是为了减少参数的数量,从而减少计算量,
且在降维之后可以更加有效、直观地进行数据的训练和特征提取。
'''
expansion = 4
def __init__(self, inplanes, planes, stride=1):
super().__init__()
# ---------------------------------------------------#
# 所有的卷积层的步长均为1,但是当步长大于1时,在第二次卷积之后
# 将会有一个平均池化层
# ---------------------------------------------------#
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.relu2 = nn.ReLU(inplace=True)
#---------------------------------#
# 当步长大于1时,将会通过一个平均池化层,
# 否则将会直接对其跳过
#---------------------------------#
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu3 = nn.ReLU(inplace=True)
self.downsample = None
self.stride = stride
# --------------------------------------#
# 执行该if语句时,"downsample layer"
# 将会由二维平均池化,卷积以及BatchNorm2d组成
# --------------------------------------#
if stride > 1 or inplanes != planes * Bottleneck.expansion:
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
self.downsample = nn.Sequential(OrderedDict([
("-1", nn.AvgPool2d(stride)),
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
("1", nn.BatchNorm2d(planes * self.expansion))
]))
def forward(self, x: torch.Tensor):
'''
Bottleneck的结构
'''
identity = x
out = self.relu1(self.bn1(self.conv1(x)))
out = self.relu2(self.bn2(self.conv2(out)))
out = self.avgpool(out)
out = self.bn3(self.conv3(out))
# ------------------------------------------#
# 当downsample层不为空时,其将会对原始的输入张量
# 执行三个序列操作
# ------------------------------------------#
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu3(out)
return out
#-----------------------------------#
# 对于AttentionPool2d这个类的定义
# 在ModifiedResNet50中被使用
#-----------------------------------#
class AttentionPool2d(nn.Module):
'''
Reference: https://blog.csdn.net/qq_41174671/article/details/131617114
注意力池化操作,从特征图中提取关键信息,将输入特征图通过位置嵌入、注意力处理和卷积操作,生成一个具有全局信息的向量表示。
'''
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
super().__init__()
# --------------------------------------------------#
# nn.Parameter()的作用为作为nn.Module中的可训练参数使用
# --------------------------------------------------#
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
#-------------------------------#
# 通过全连接层来获取以下四个映射量
#-------------------------------#
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
self.num_heads = num_heads
def forward(self, x):
# ---------------------------------------------------------------#
# 首先进行张量shape的转变,由 batch_size,c,h,w -> (h*w),batch_size,c
# ---------------------------------------------------------------#
x = x.flatten(start_dim=2).permute(2, 0, 1) # NCHW -> (HW)NC
# -------------------------------------------#
# (h*w),batch_size,c -> (h*w+1),batch_size,c
# -------------------------------------------#
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
# --------------------------------------------------------------------#
# tensor的shape以及type均不发生改变,所做的只是将位置信息嵌入至原先的tensor中
# shape:(h*w+1),batch_size,c
# --------------------------------------------------------------------#
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
#---------------------------------------#
# 将输入的张量pass through 多头注意力机制模块
#---------------------------------------#
x, _ = F.multi_head_attention_forward(
query=x[:1], key=x, value=x,
embed_dim_to_check=x.shape[-1],
num_heads=self.num_heads,
q_proj_weight=self.q_proj.weight,
k_proj_weight=self.k_proj.weight,
v_proj_weight=self.v_proj.weight,
in_proj_weight=None,
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
bias_k=None,
bias_v=None,
add_zero_attn=False,
dropout_p=0,
out_proj_weight=self.c_proj.weight,
out_proj_bias=self.c_proj.bias,
use_separate_proj_weight=True,
training=self.training,
need_weights=False
)
return x.squeeze(0)
#-------------------------------------#
# CLIP中所使用到的ModifiedResNet50的定义
#-------------------------------------#
class ModifiedResNet(nn.Module):
"""
A ResNet class that is similar to torchvision's but contains the following changes:
类似于 torchvision 的 ResNet 类,但包含以下更改:
- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool
- 现在有 3 个 "干 "卷积(而不是 1 个),平均池而不是最大池。
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
- 执行抗锯齿的跨距卷积,在跨距大于 1 的卷积中预置 avgpool。
- The final pooling layer is a QKV attention instead of an average pool
- 最后的池化层是 QKV 注意,而不是平均池。
"""
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
super().__init__()
self.output_dim = output_dim
self.input_resolution = input_resolution
# the 3-layer stem
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(width // 2)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(width // 2)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(width)
self.relu3 = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(2)
# ------------------------------------#
# residual layers in ModifiedResNet50
# 共计四层
# ------------------------------------#
# residual layers
self._inplanes = width # this is a *mutable* variable used during construction
self.layer1 = self._make_layer(width, layers[0])
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
embed_dim = width * 32 # the ResNet feature dimension
# --------------------------------------------------#
# 对于最后的平均池化层我们使用一个QKV注意力池化层来进行替代,前面定义的AttentionPool2d在这里掉用
# --------------------------------------------------#
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
# ----------------------------------------#
# ModifiedResNet50中的残差层的定义
# 其中的blocks即为标准的残差结构--Bottleneck
# ----------------------------------------#
def _make_layer(self, planes, blocks, stride=1):
layers = [Bottleneck(self._inplanes, planes, stride)]
self._inplanes = planes * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(self._inplanes, planes))
return nn.Sequential(*layers)
#-------------------------------#
# ModifiedResNet50的前向传播函数
#-------------------------------#
def forward(self, x):
# -----------------------------------------#
# As to the 3-"stem" convolution layers
# 在这里我们将三个卷积层集成到一个函数中使用
# 每一层均为 conv->bn->relu
# -----------------------------------------#
def stem(x):
x = self.relu1(self.bn1(self.conv1(x)))
x = self.relu2(self.bn2(self.conv2(x)))
x = self.relu3(self.bn3(self.conv3(x)))
x = self.avgpool(x)
return x
#------------------------------------------#
# 这行code的作用在于对输入的张量进行一个type的转换
#------------------------------------------#
x = x.type(self.conv1.weight.dtype)
#---------------------#
# 三个卷积层
#---------------------#
x = stem(x)
#----------------------------------#
# ModifiedResNet50中的残差结构,共4层
#----------------------------------#
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.attnpool(x)
# --------------------------------------------------#
# 对于最后的平均池化层我们使用一个QKV注意力池化层来进行替代
# --------------------------------------------------#
return x
#-----------------------------------#
# transformer模块中所使用到的LayerNorm层
#-----------------------------------#
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
def forward(self, x: torch.Tensor):
orig_type = x.dtype
ret = super().forward(x.type(torch.float32))
return ret.type(orig_type)
#--------------------------------#
# QuickGELU激活函数的定义
# 在transformer结构中的MLP层中被使用
#--------------------------------#
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
return x * torch.sigmoid(1.702 * x)
#-------------------------------------------------#
# transformer模块的定义,将会在transformer结构中被使用
# 1.多头注意力层
# 2.LayerNorm层
# 3.MLP层
#-------------------------------------------------#
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
#----------------------#
# 多头注意力机制
#----------------------#
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
# -------------------------------------------------------------------#
# 在MLP层中首先是进行一次全连接,之后是过QuickGELU激活函数,最后是通过投影进行映射
# -------------------------------------------------------------------#
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
#-------------------------------------#
# 该函数的作用是对输入的张量使用多头注意力机制
#-------------------------------------#
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
# ---------------------------------------------------------------#
# 在这个前向传播函数中,对于transformer模块进行了定义以及说明
# ---------------------------------------------------------------#
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
#-------------------------------------#
# transformer结构的定义
# 即为多个transformer模块按照顺序进行堆叠
#-------------------------------------#
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
#---------------------------------#
# VisionTransformer结构的定义
# 输入图片的通道数为3
#---------------------------------#
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
# ------------------------------------------#
# 在这里我们可以用nn.Parameter()来将这
# 个随机初始化的Tensor注册为可学习的参数Parameter
# ------------------------------------------#
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
# -----------------------------------------------------------------------------------------#
# 此处的卷积可以将张量的shape转变为batch_size,width,grid,grid(grid=input_resolution/patch_size)
# --------------------------------------------------------------------------
x = self.conv1(x) # shape = [*, width, grid, grid]
# ---------------------------------------------#
# reshape之后,shape=batch_size,width,grid ** 2
# ---------------------------------------------#
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
#----------------------------#
# 转置之后,shape为
# batch_size,grid ** 2,width
#----------------------------#
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
# ------------------------------------------------------#
# pass这条语句之后,shape=batch_size,grid ** 2 + 1,width
# ------------------------------------------------------#
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
# --------------------------------------------#
# 加上其位置编码信息,并且pass through LayerNorm层
# --------------------------------------------#
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
# -----------------------------------------------#
# shape先转变为grid ** 2 + 1,batch_size,width
# 之后经由transformer结构编码
# 最后再进行转置,恢复为batch_size,grid ** 2 + 1,width
# 再pass through LayerNorm层
# -----------------------------------------------#
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_post(x[:, 0, :])
#-------------------------#
# 若成立则将会进行矩阵乘法运算
#-------------------------#
if self.proj is not None:
x = x @ self.proj
return x
#------------------------#
# CLIP模型的定义
#------------------------#
class CLIP(nn.Module):
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
#------------------------#
# 定义文本的长度
#------------------------#
self.context_length = context_length
# --------------------------------------------#
# image encoder
# 对于image部分,可以使用ModifiedResNet50或者ViT
# --------------------------------------------#
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
# ---------------------------------------#
# text encoder
# 对于文字部分则直接使用Text Transformer即可
# ---------------------------------------#
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
# ----------------------------------------------#
# token嵌入以及位置嵌入还有对于LayerNorm的进一步的定义
# ----------------------------------------------#
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
# --------------------------------------------------------------------------#
# 在这里我们可以用nn.Parameter()来将这个随机初始化的Tensor注册为可学习的参数Parameter
# torch.empty用于返回一个未初始化的tensor
# torch.zeros用于将tensor中元素值全置为0
# torch.ones用于将tensor中元素值全置为1
# logit_scale与 cosine similarities有关
# --------------------------------------------------------------------------#
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
#-------------------#
# 定义了此类中的一个函数
#-------------------#
self.initialize_parameters()
#---------------------------#
# 部分权值的初始化操作
#---------------------------#
def initialize_parameters(self):
nn.init.normal_(self.token_embedding.weight, std=0.02)
nn.init.normal_(self.positional_embedding, std=0.01)
if isinstance(self.visual, ModifiedResNet):
if self.visual.attnpool is not None:
std = self.visual.attnpool.c_proj.in_features ** -0.5
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
for name, param in resnet_block.named_parameters():
if name.endswith("bn3.weight"):
nn.init.zeros_(param)
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
attn_std = self.transformer.width ** -0.5
fc_std = (2 * self.transformer.width) ** -0.5
for block in self.transformer.resblocks:
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
if self.text_projection is not None:
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
def build_attention_mask(self):
# lazily create causal attention mask, with full attention between the vision tokens
# pytorch uses additive attention mask; fill with -inf
mask = torch.empty(self.context_length, self.context_length)
mask.fill_(float("-inf"))
mask.triu_(1) # zero out the lower diagonal
return mask
@property
def dtype(self):
return self.visual.conv1.weight.dtype
#-------------------#
# image encoder函数
#-------------------#
def encode_image(self, image):
return self.visual(image.type(self.dtype))
#------------------------------------#
# text encoder函数
# 这里为一个单纯的 Text transformer结构
#------------------------------------#
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
# --------------------------------------------------------------#
# CLIP这个类的前向传播函数的定义
# 即为CLIP整体模型的定义
# --------------------------------------------------------------#
def forward(self, image, text):
# ---------------------------------------------#
# 使用ModifiedResNet50或者ViT来完成图像信息的编码
# 使用Text transformer来完成文本信息的编码
# ---------------------------------------------#
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# ---------------------------------#
# joint multimodal embedding
# normalized features
# ---------------------------------#
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
#--------------------------------#
# 计算图像以及文本的相似度
# cosine similarity as logits
#--------------------------------#
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# -------------------------------------------------#
# 所返回的张量的shape为
# shape = [global_batch_size, global_batch_size]
# -------------------------------------------------#
return logits_per_image, logits_per_text
#-----------------------------#
# 为了训练加速使用到了混合精度运算
#-----------------------------#
def convert_weights(model: nn.Module):
"""Convert applicable model parameters to fp16"""
def _convert_weights_to_fp16(l):
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
l.weight.data = l.weight.data.half()
if l.bias is not None:
l.bias.data = l.bias.data.half()
if isinstance(l, nn.MultiheadAttention):
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
tensor = getattr(l, attr)
if tensor is not None:
tensor.data = tensor.data.half()
for name in ["text_projection", "proj"]:
if hasattr(l, name):
attr = getattr(l, name)
if attr is not None:
attr.data = attr.data.half()
model.apply(_convert_weights_to_fp16)
#-----------------------------------------------#
# CLIP模型的创建
#-----------------------------------------------#
def build_model(state_dict: dict):
vit = "visual.proj" in state_dict
if vit:
vision_width = state_dict["visual.conv1.weight"].shape[0]
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
image_resolution = vision_patch_size * grid_size
else:
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
vision_layers = tuple(counts)
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
vision_patch_size = None
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
image_resolution = output_width * 32
embed_dim = state_dict["text_projection"].shape[1]
context_length = state_dict["positional_embedding"].shape[0]
vocab_size = state_dict["token_embedding.weight"].shape[0]
transformer_width = state_dict["ln_final.weight"].shape[0]
transformer_heads = transformer_width // 64
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith("transformer.resblocks")))
model = CLIP(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
)
for key in ["input_resolution", "context_length", "vocab_size"]:
if key in state_dict:
del state_dict[key]
convert_weights(model)
model.load_state_dict(state_dict)
return model.eval()

















 3043
3043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









