









【ML】线性回归 [多因子](LinearRegression)实践(基于sklearn)
数据准备
使用数据:USA_Housing.csv
读取数据
import pandas as pd
import numpy as np
# 读取数据
origin_data = pd.read_csv('USA_Housing.csv')
print(type(origin_data))
# 删除无用的列
data = origin_data.drop(columns=['Address'])
data.head()
输出:
<class 'pandas.core.frame.DataFrame'>
| Avg. Area Income | Avg. Area House Age | Avg. Area | Number of Rooms | Avg. Area Number of Bedrooms | Area Population Price | |
|---|---|---|---|---|---|---|
| 0 | 79545.45857 | 5.682861 | 7.009188 | 4.09 | 23086.80050 | 1.059034e+06 |
| 1 | 79248.64245 | 6.002900 | 6.730821 | 3.09 | 40173.07217 | 1.505891e+06 |
| 2 | 61287.06718 | 5.865890 | 8.512727 | 5.13 | 36882.15940 | 1.058988e+06 |
| 3 | 63345.24005 | 7.188236 | 5.586729 | 3.26 | 34310.24283 | 1.260617e+06 |
| 4 | 59982.19723 | 5.040555 | 7.839388 | 4.23 | 26354.10947 | 6.309435e+05 |
绘制图表(观察数据规律)
# 观察数据
from matplotlib import pyplot as plt
plt.subplot(231)
plt.scatter(data.loc[:,'Avg. Area Income'], data.loc[:,'Price'])
plt.title('Income')
plt.subplot(232)
plt.scatter(data.loc[:,'Avg. Area House Age'], data.loc[:,'Price'])
plt.title('Age')
plt.subplot(233)
plt.scatter(data.loc[:,'Avg. Area Number of Rooms'], data.loc[:,'Price'])
plt.title('Rooms')
plt.subplot(234)
plt.scatter(data.loc[:,'Avg. Area Number of Bedrooms'], data.loc[:,'Price'])
plt.title('Bedrooms')
plt.subplot(235)
plt.scatter(data.loc[:,'Area Population'], data.loc[:,'Price'])
plt.title('Population')

单因子训练(为了做对比)
# rooms单因子测试
from sklearn.linear_model import LinearRegression
x_1 = data.loc[:,'Avg. Area Number of Rooms']
x_1 = np.array(x_1).reshape(-1,1);
y = data.loc[:,'Price']
lr_1 = LinearRegression()
lr_1.fit(x_1, y)
预测+评估(单因子)
# 预测+评估
y_predict_1 = lr_1.predict(x_1)
# 评估 MSE,r2
from sklearn.metrics import mean_squared_error, r2_score
MSE_1 = mean_squared_error(y,y_predict_1)
r2_score_1 = r2_score(y,y_predict_1)
print(MSE_1, r2_score_1)
输出:
110620797457.445 0.11267062524906302
显然,r2_score只有0.11效果很差
多因子训练
#使用多因子方式
lr_mutil = LinearRegression()
x_mutil = data.drop(['Price'], axis=1)
lr_mutil.fit(x_mutil, y)
预测+评估(多因子)
# 预测
y_mutil_predict = lr_mutil.predict(x_mutil)
# 评估 MSE,r2
MSE_mutil = mean_squared_error(y,y_mutil_predict)
r2_mutil_score = r2_score(y,y_mutil_predict)
print(MSE_mutil, r2_mutil_score)
输出
10219734313.031612 0.9180238195119546
r2_score达到了0.918效果提升明显
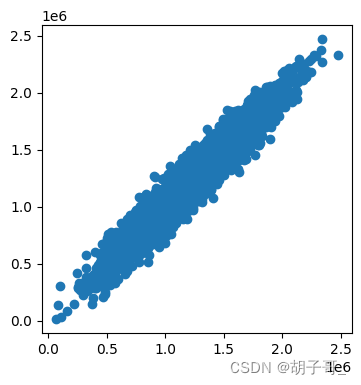
图形展示
查看y和y_mutil_predict的聚合程度,聚合度越高越好
# 图形展示
plt.figure(figsize=(4,4))
plt.scatter(y_mutil_predict,y)















 3554
3554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









