









【ML】逻辑回归(LogisticRegression)实践(基于sklearn)
原理介绍
逻辑回归不是回归问题,而是分类问题,最常用来解决二分类问题。
逻辑回归最核心的便是激活函数,而最常用的便是sigmoid函数:
P
(
x
)
=
1
1
+
e
−
x
P(x)=\frac{1}{1+e^{-x} }
P(x)=1+e−x1
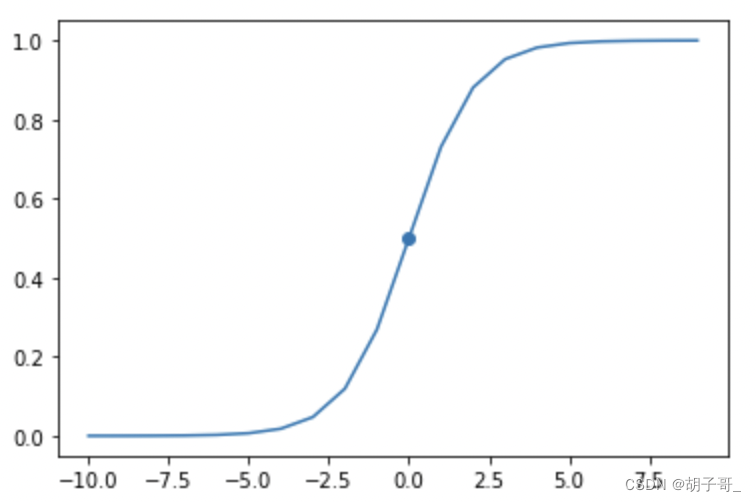
sigmoid函数有一个很好的性质,他的值域在[0,1]之间。对于任意值域的函数g(x)都可以通过sigmoid函数压缩到[0,1]之间。
如上图,sigmoid函数在x=0点的值为0.5。而对于分类问题,一组数据
(
x
i
1
,
.
.
.
y
i
1
)
,
(
x
i
2
,
.
.
.
y
i
2
)
,
(
x
i
3
,
.
.
.
y
i
3
)
,
.
.
.
.
{(x_{i1},...y_{i1}),(x_{i2},...y_{i2}),(x_{i3},...y_{i3}),....}
(xi1,...yi1),(xi2,...yi2),(xi3,...yi3),....,y的值为离散值{1,0}。
所以我们不妨建立模型:
g
(
x
)
=
p
0
+
p
1
X
1
+
p
2
X
2
g(x) = p_0+p_1X_1+p_2X_2
g(x)=p0+p1X1+p2X2(根据实际情况可以调整为更复杂的形式)。用g(x)替换sigmoid函数中的x.当用实际数据代入g(x)时,得到的g(x)值为一个区间在(-∞,∞)的值,代入sigmoid函数便获得一个[0,1]区间内的值,假设当sigmoid函数值大于0.5我们认为值为1,小于0.5我们认为值为0,那么我们只需要调整
p
0
,
p
1
,
p
2
p_0,p_1,p_2
p0,p1,p2的值,使得g(x)在所有数据上都能尽量呈现此特性即可。此时g(x)便是我们想要的模型。而为了模型尽可能的准确,我们希望sigmoid函数在训练数据集上,每组正例数据计算出的值尽量逼近1. 每组反例数据计算出的值尽量逼近0.
有以下损失函数(注意损失函数前有负号,奈何数学水平有限,详细的推导大家看这里:https://zhuanlan.zhihu.com/p/44591359):
−
∑
n
=
1
N
(
y
n
ln
(
p
)
+
(
1
−
y
n
)
ln
(
1
−
p
)
)
-\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right)
−n=1∑N(ynln(p)+(1−yn)ln(1−p))
其中
y
n
y_{n}
yn即每组数据的真实值{0,1},p即sigmoid函数(将x换位g(x)后的),我们知道sigmoid函数值域为[0,1],而
−
l
n
(
x
)
-ln(x)
−ln(x)在[0,1]区间内是单调减函数,所以要取得最小值,要求x越接近1越好。所以有:
- 当 y n = 1 y_{n}=1 yn=1时,损失函数只有前半段。即 l n ( p ) ln (p) ln(p),要使损失函数最小,则p越接近1越好。
- 当 y n = 0 y_{n}=0 yn=0时,损失函数只有后半段。即 l n ( 1 − p ) ln(1-p) ln(1−p)。同理,p越接近0越好(即1-p越接近1)。
与我们希望的正例尽量接近1,反例尽量接近0一致。后面就是函数求导,梯度下降求最小值了。这里求解过程大家感兴趣可以查看上面给的公式推导链接。
实践
数据集
下载:https://www.kaggle.com/datasets/yuanheqiuye/exam-data
读取数据
import pandas as pd
import numpy as np
data = pd.read_csv('/kaggle/input/exam-data/exam_data.csv')
data.head()
输出:
| Exam1 | Exam2 | Pass | |
|---|---|---|---|
| 0 | 34.623660 | 78.024693 | 0 |
| 1 | 30.286711 | 43.894998 | 0 |
| 2 | 35.847409 | 72.902198 | 0 |
| 3 | 60.182599 | 86.308552 | 1 |
| 4 | 79.032736 | 75.344376 | 1 |
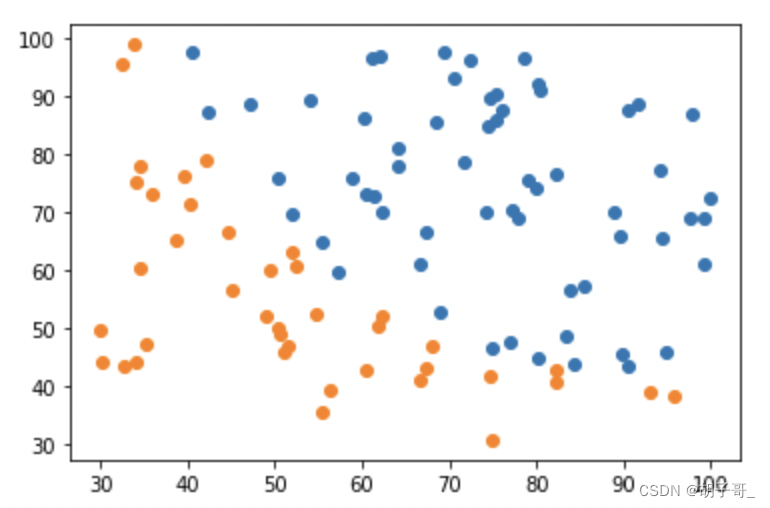
观察数据
from matplotlib import pyplot as plt
plt.figure()
mask=data.loc[:,'Pass'] > 0
plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
模型训练(一次形式)
训练
定义边界函数:p0+p1X1+p2X2=0
# 准备数据
X = data.drop(columns=['Pass'])
y = data.loc[:,'Pass']
# 训练数据
from sklearn.linear_model import LogisticRegression
LR1 = LogisticRegression()
LR1.fit(X,y)
p1,p2 = LR1.coef_[0][0],LR1.coef_[0][1]
p0 = LR1.intercept_
print(p0,p1,p2)
输出:
[-25.05219314] 0.20535491217790386 0.20058380395469053
预测+评估(一次)
#预测
y_predict = LR1.predict(X)
#评估
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
输出:
0.89
通过图形观察
# 根据定义的模型计算分割线
X2_new = -(p1*X1+p0)/p2
plt.figure()
mask=data.loc[:,'Pass'] > 0
plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.plot(X1,X2_new)
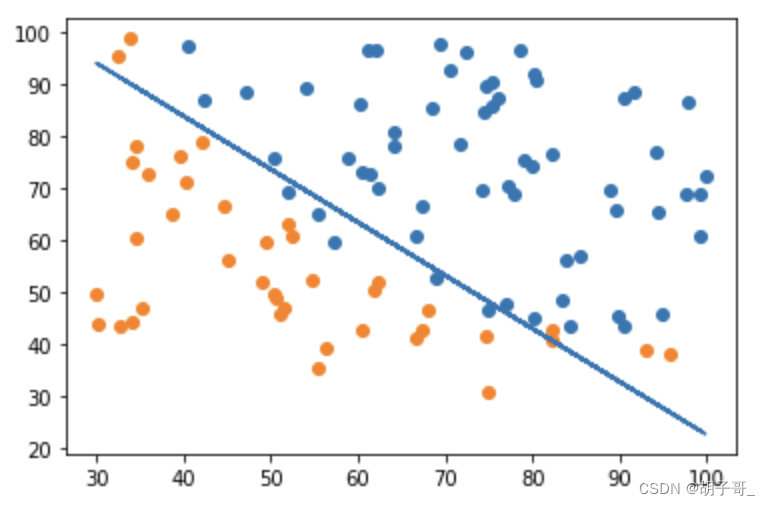
从图可以看出,效果不是很好。
模型训练(二次形式)
使用二次建模,定义边界函数:q0+q1X1+q2X2+q3X1X1+q4X2X2+q5X1X2=0
数据处理
X1 = data.loc[:,'Exam1']
X2 = data.loc[:,'Exam2']
X1_2=X1*X1
X2_2=X2*X2
X1_X2=X1*X2
data_new = pd.DataFrame({"X1":X1,'X2':X2,'X1_2':X1_2,'X2_2':X2_2,'X1_X2':X1_X2})
训练
#训练模型
LR_2 = LogisticRegression()
LR_2.fit(data_new,y)
预测+评估(二次)
#预测
y_predict_new = LR_2.predict(data_new)
print(y_predict_new)
# 查看准确率
accuracy_new = accuracy_score(y, y_predict_new)
print(accuracy_new)
输出:
1.0
效果非常好
通过图形观察效果
# 绘制函数图形q0+q1X1+q2X2+q3X1^2+q4X2^2+q5X1X2=0
q0=LR_2.intercept_
q1,q2,q3,q4,q5=LR_2.coef_[0][0],LR_2.coef_[0][1],LR_2.coef_[0][2],LR_2.coef_[0][3],LR_2.coef_[0][4]
#排序,为了绘图
X1_new = X1.sort_values()
#已知X1,求X2,即一元二次方程aX^2+bx+c=0
c=q0+q1*X1_new+q3*X1_new*X1_new
b=(q2+q5*X1_new)
a=q4
#根据方程通解,取正数(得分肯定是正的)
X2_new2 = (-b+np.sqrt(b*b-4*a*c))/(2*a)
# 绘制图形
plt.figure()
mask=data.loc[:,'Pass'] > 0
plt.scatter(data.loc[:,'Exam1'][mask],data.loc[:,'Exam2'][mask])
plt.scatter(data.loc[:,'Exam1'][~mask],data.loc[:,'Exam2'][~mask])
plt.plot(X1_new,X2_new2)
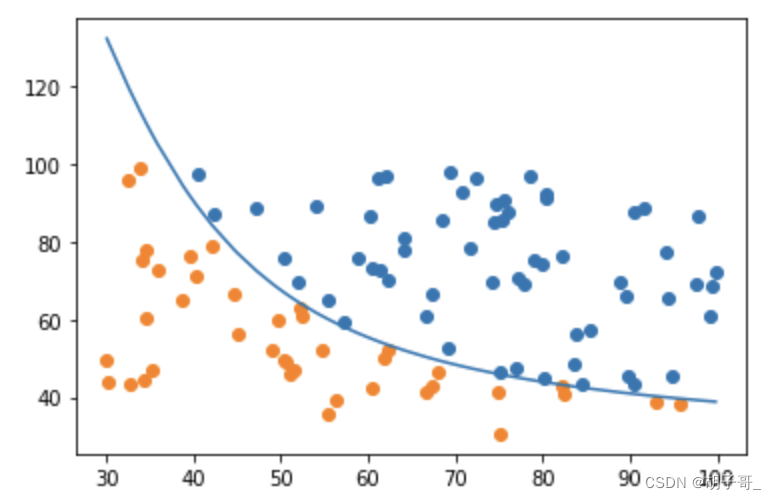
从图可以看出,分类的非常好。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









