







![]()
Bilibili:CV缝合救

🌈 小伙伴们看过来~
写推文真的不容易,每一行字、每一张图都倾注了我们的心血💦 如果你觉得这篇内容对你有帮助、有启发,别忘了顺手点个赞、转发一下、或者点个“在看” 支持我们一下哈~✨
你的一点鼓励🌟,对我们来说就是超大的动力!
👀 小声提醒:用电脑打开阅读更舒服哟,排版清晰、体验更棒!谢谢大家~我们会继续努力产出优质内容,陪你一起进步呀✌️❤️
01论文信息




论文题目:DFormerv2: Geometry Self-Attention for RGBD Semantic Segmentation (CVPR 2025)中文题目:DFormerv2:用于 RGBD 语义分割的几何自注意力即插即用模块:Geometry Self Attention | 几何自注意力
02 论文概要

Highlight
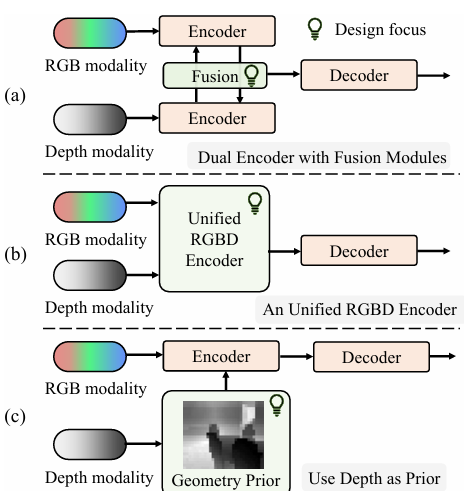
图 1. 主流 RGBD 分割流程与我们的方法之间的比较。(a) 使用双编码器分别对 RGB 和深度进行编码,并设计融合模块将它们融合 [28, 61];(b) 采用统一的 RGBD 编码器来提取和融合 RGBD 特征 [1, 59];(c) 我们的 DFormerv2 利用深度形成场景的几何先验,然后增强视觉特征。

图 2. 几何自注意力(GSA)与其他注意力机制的比较,这些机制即普通注意力 [10]、窗口注意力 [9, 35] 和局部注意力 [52, 57] 。“星号” 表示当前查询的位置。在几何自注意力中,颜色越接近红色表示衰减率越小,而离红色越远的颜色表示衰减率越大。在其他注意力机制中,亮色表示感受野。
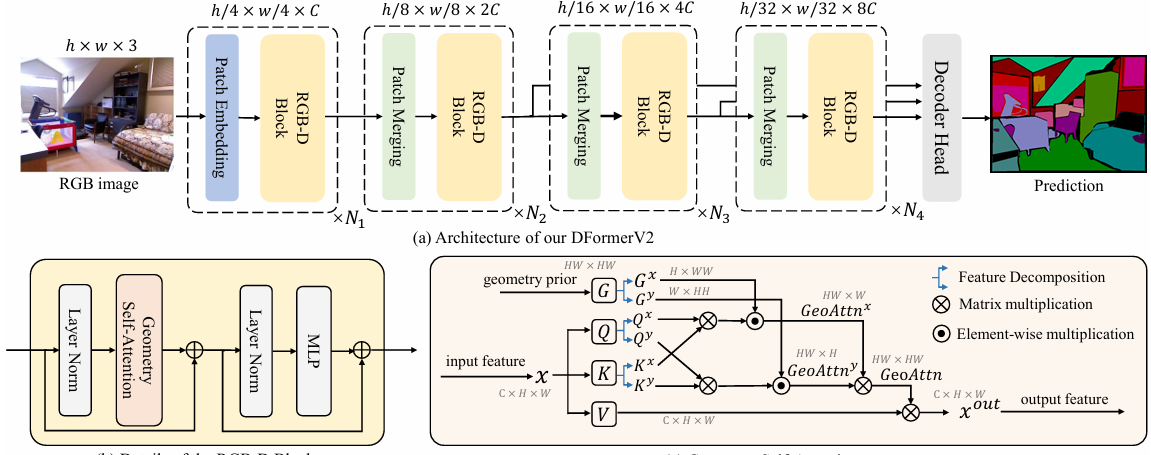
图 3. 我们的 DFormerv2 示意图。(a) 我们的 DFormerv2 的整体架构,其包含一个具有金字塔结构的编码器,以及一个接收来自最后三个阶段特征输入的解码器头部。(b) 基本构建模块的详细结构。(c) 所提出的几何自注意力机制的详细说明。
03研究背景

近年来,语义分割作为计算机视觉中的核心任务,在自动驾驶、智能机器人等领域展现出重要应用价值。然而,基于RGB图像的传统方法在复杂场景中(如低光照、遮挡或纹理缺失)存在明显性能瓶颈。
1. 现有RGB-D建模方式存在结构与效率瓶颈:
现有RGB-D语义分割方法通常采用双分支编码器对RGB和深度模态分别建模,并通过融合模块进行特征交互;或者使用统一编码器直接对RGB-D对齐输入进行处理。这些方法虽然取得了不错的性能,但普遍存在两个问题:一是引入额外的计算开销;二是未能充分挖掘深度图的几何属性,仅将其视为一种附加的图像模态,缺乏结构上的差异建模能力。
2. 深度图几何特性利用不足:
深度图天然蕴含场景的三维空间结构信息,能提供与RGB图像互补的几何感知能力。然而主流方法普遍将深度图送入标准卷积或Transformer模块处理,忽视了其作为几何先验信息的独特价值。这种粗暴融合策略不仅增加了冗余计算,也限制了模型对空间关系的理解能力。
为了解决上述问题,本文提出了一种新颖的思路:不再显式编码深度图特征,而是利用其构造图像patch之间的几何关系矩阵,引导注意力权重的空间分配。 通过构建一个融合空间位置与深度差异的几何先验,并引入至自注意力机制中,模型可以自动聚焦于几何相关区域,从而在不引入额外复杂度的前提下,显著提升RGB-D语义理解能力。该方法兼顾性能与效率,为RGB-D语义分割提供了全新的研究范式。
04 模块原理解读

📌 模块解析 | GSA 模块原理详解:几何先验引导与轴向注意力融合
(轻量插拔式子模块 | 加强结构建模能力)
在RGB-D语义分割中,深度图蕴含丰富的几何结构信息,但现有方法常将其作为图像模态直接编码,未能显式利用几何关系。本文提出的几何自注意力模块(Geometry Self-Attention, GSA)通过引入可学习的几何先验矩阵,以结构化方式调整注意力分布,使模型更加关注几何邻近区域,从而提升空间关系建模能力。
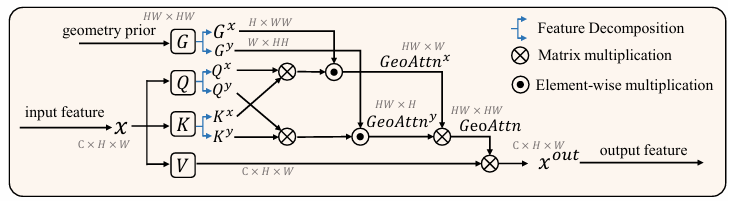
图 4. 几何自注意力模块(Geometry Self-Attention, GSA)
🔹 1. 构建深度引导的几何先验矩阵
GSA模块结合图像patch间的空间距离与深度差异,生成几何关系矩阵G,作为引导因子调节自注意力权重。
-
以每个patch的平均深度值构建全局深度差矩阵;
-
引入曼哈顿距离编码空间结构信息;
-
通过可学习权重融合深度差与空间位置,形成最终几何先验。
✅ 优势:引入结构感知机制,引导注意力关注3D几何上相关区域,显著提升分割连贯性与鲁棒性。
🔹 2. 几何感知注意力机制设计
将几何关系矩阵作为抑制因子,调制原始注意力得分,实现结构相关性增强与冗余干扰抑制。
-
将几何矩阵G通过指数衰减转化为注意力掩码(β^G);
-
与标准QK注意力图逐元素相乘,弱化远距离patch之间的权重;
-
保留传统Transformer表达能力的同时,加入空间结构感知能力。
✅ 关键点:动态重构注意力空间分布,避免语义混淆,提升目标边界清晰度与小物体识别能力。
🔹 3. 高效实现:轴向注意力分解策略
为降低全局注意力计算成本,GSA采用水平-垂直轴向分解方式,将二维注意力转化为两个一维注意力过程。
-
分别沿H轴和W轴计算注意力权重,计算量从O(n²)降低至O(2n√n);
-
保持空间解析能力,兼顾计算效率;
-
可灵活插入各层Transformer编码器,适应不同尺度特征。
✅ 亮点:结构引导 + 高效分解,实现精准建模与快速推理的协同提升。
05 创新思路

CV缝合救星原创模块
视频讲解 CV任务通用模块|2025(CVPR)|GSA几何自注意力|一文搞定轴注意力|原创魔改即插即用|1个创新点,适用于图像分类、目标检测、分割等所有CV任务_哔哩哔哩_bilibili
🧠 模块升级 | GSA-SC:结构对比增强的几何自注意力模块(Geometry Self-Attention with Structural Contrast)
一、创新点一:引入结构对比增强机制
-
在构建几何关系矩阵G时,不仅考虑patch间的空间距离与深度差异,还引入相邻块之间的结构梯度变化(如局部深度/纹理对比)。
-
将结构对比度作为附加调制因子,引导模型更关注结构边界清晰、语义过渡明显的区域。
✅ 优势:有效增强对边缘、轮廓等结构关键区域的建模能力,改善目标边界模糊、细节缺失的问题。
二、创新点二:设计对比感知几何注意力权重
-
原始注意力计算中,将G作为直接mask进行加权。
-
GSA-SC中将几何矩阵G与结构对比矩阵C联合,生成组合权重 β^(G+C),进一步压制结构一致区域间的注意力传播。
-
通过结构选择性增强(Structure-aware Softmax),提升模型对不同空间块间几何边界的分辨能力。
✅ 优势:避免跨结构区域的信息干扰,提升语义一致性和区域内表达稳定性。
三、创新点三:轻量融合策略
-
模块仅增加一组对比图提取卷积(如3×3局部差分)、一条线性融合路径。
-
保持整体计算复杂度几乎不变,同时具备即插即用性。
✅ 亮点:在保持Full-GSA架构不变的基础上,增强了空间结构建模的表现力,兼容多尺度编码器、Transformer骨干网络。
✨ 总结:GSA-SC通过结构差异感知 + 对比抑制增强双路径机制,推动几何自注意力向结构敏感、信息稀疏、高效传播方向演进,是适用于分割、ReID等任务的实用型创新模块。
06 模块适用任务

🧠 GSA模块适用任务
GSA(Geometry Self-Attention)模块是一种结合空间位置与深度感知的结构引导型注意力机制,旨在提升模型对结构边界与空间布局的理解能力,适配各类需要几何感知能力的视觉任务。
1. 空间结构敏感任务(语义/实例分割)
-
在图像中提取结构清晰、边界准确的区域特征,提升分割结果的一致性与边界对齐性;
-
尤其适合处理含有复杂空间关系的场景图像。
🎯 优势:强化结构连续性建模,优化边界预测质量。
2. 多视角建模任务(3D感知 / 立体匹配)
-
适用于深度估计、视差预测等任务中,感知patch之间的空间几何关系;
-
融合位置信息与深度信息,提升跨视角语义对齐能力。
🎯 优势:提升模型对空间结构一致性的感知与利用能力。
3. 弱纹理区域建模(光滑区域目标识别)
-
对于纹理不明显但几何边界显著的区域,通过G矩阵引导注意力聚焦在空间结构上;
-
有效弥补传统注意力在无明显特征区域中的失效问题。
🎯 优势:在低纹理场景中提供显著的几何结构增强能力。
🧠 GSA-SC模块适用任务
GSA-SC(Geometry Self-Attention with Structural Contrast)在GSA基础上引入结构对比增强,突出区域间结构边界与语义分割的能力,是一种针对结构突变区域优化的几何感知模块。
1. 目标边界清晰任务(边缘检测 / 分割细化)
-
可用于边缘检测任务中加强轮廓感知能力;
-
在语义分割中提升小物体检测与边界细化表现。
🎯 优势:增强边缘敏感性,解决语义边界模糊问题。
2. 小样本目标检测 / 异常检测
-
借助结构对比强化目标与背景的结构差异,帮助模型快速聚焦于语义跳变区域;
-
适合小目标或稀疏目标的建模需求。
🎯 优势:通过结构突变点增强局部特征辨识能力。
3. 异构结构建模任务(跨模态匹配 / VI-ReID)
-
可在模态之间建立基于结构一致性的注意力关系,提升跨模态对齐的鲁棒性;
-
特别适用于视觉-红外、RGB-深度等异构匹配任务。
🎯 优势:实现结构对齐导向的注意力传播,增强跨模态语义理解。
07 运行结果与即插即用代码

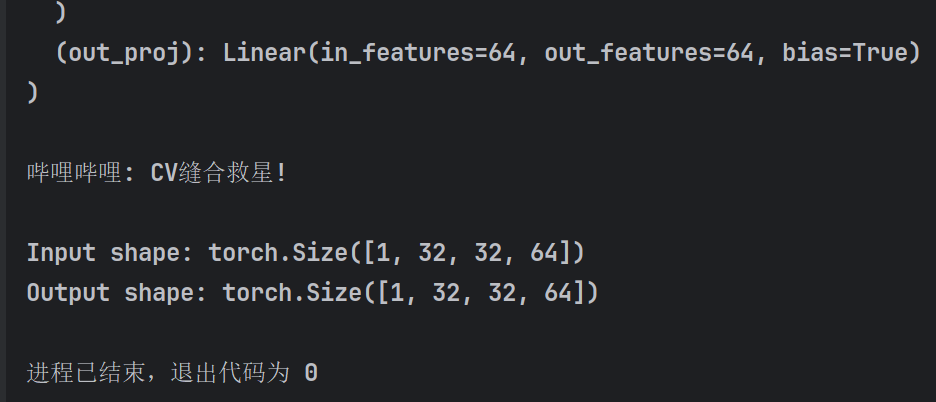
运行结果
GSA模块
GSA-SC模块
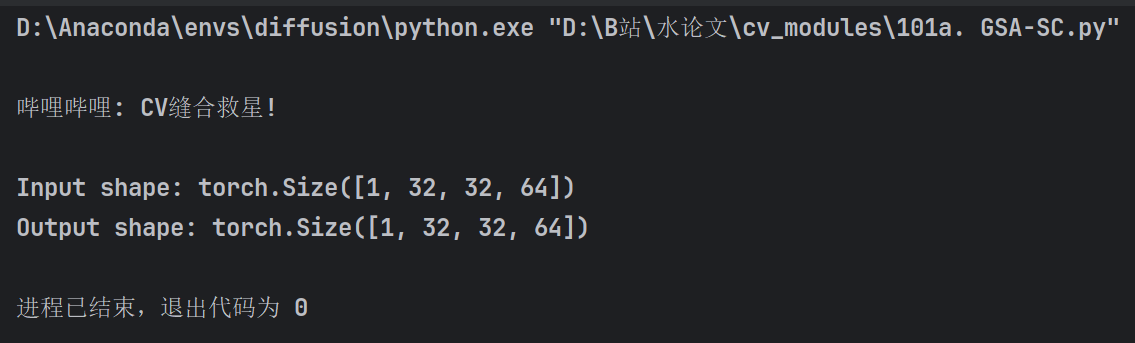
本文代码获取
立即加星标

即插即用模块获取链接:
各位朋友,感谢你一直以来对我们内容的关注与认可!
我们在整理每篇精选推文的过程中,都会查阅大量论文资料,调试优化数十上百段代码,力求将最实用、最清晰的思路呈现给大家。
不管是历史文复盘,还是后台留言反馈,很多读者已经通过这些内容提升了技能,推动了项目落地,甚至在课程、竞赛、工程中取得了实际成果。
🔶 目前我们已整理并更新 200+ 套模块化代码,涵盖:
✅ 原始论文结构复现(精准还原,快速理解)
✅ 原创思路改进版本(结构创新,性能提升)
🧠 适配实际项目场景(合理拓展用模块)
包括图像分类、目标检测、遥感分析、医学图像、小样本识别、工业检测等多个方向。
❤️ 如果你希望获得本文所对应的完整可运行代码 + 模块化魔改版本,以及更多 2025 年持续更新的深度学习实用资料。

















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









