







 本文详细介绍了决策树学习中的特征选择,重点关注信息增益和信息增益比作为选择准则。讨论了ID3、C4.5和CART算法,以及决策树的生成与剪枝,以防止过拟合并提高泛化能力。
本文详细介绍了决策树学习中的特征选择,重点关注信息增益和信息增益比作为选择准则。讨论了ID3、C4.5和CART算法,以及决策树的生成与剪枝,以防止过拟合并提高泛化能力。
文章目录
5.2 特征选择
5.2.1 特征选择问题
如前述所讲,特征选择在于选取对训练数据具有分类能力的特征。
如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。(这个定义…)
故扔掉没有分类能力的该类特征对决策树学习的精度影响不大。
特征选择的准则是信息增益或信息增益比。
例 5.1
说明:数据是一个由15个样本组成的贷款申请训练数据,数据包括贷款申请人的4个特征(属性)。
特征和属性是不一样的,
一个特征(属性)有三个特征值,但总共有四个特征。
注意区别:特征(属性)与特征值。(有助于理解信息增益的算法)
目的: 希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
重点: 特征选择是决定用哪个特征来划分特征空间。
我们从表5.1数据学习到的两个可能的决策树,分别由两个不同特征(年龄和有工作)的根结点构成。两个决策树都可以从此延续下去。
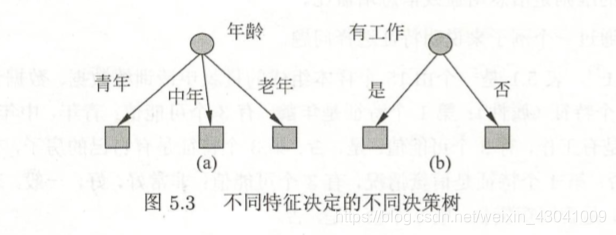
问题是:究竟选择哪个特征更好些?这需要确定选择特征的准则。
信息增益(information gain)即表示这一直观的准则。
5.2.2 信息增益
(1)熵
为了便于说明,先给出熵与条件熵的定义。
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设 X X X是一个取有限个值得离散随机变量,其概率分布为:
P ( X = x i ) = p i , i = 1 , 2 , . . . , n P(X=x_i)=p_i,i=1,2,...,n P(X=xi)=pi,i=1,2,...,n
则随机变量 X X X的熵的定义为:
H ( X ) = − ∑ i = 1 n p i l o g p i (5.1) H(X)=-\sum_{i=1}^{n}p_ilogp_i\tag {5.1} H(X)=−i=1∑npilogpi(5.1)
在式(5.1)中,若 p i = 0 p_i=0 pi=0,则定义0log0=0.通常,式(5.1)中的对数以2为底或以e为底(自然对数),这时熵的单位分别称作比特(bit)或者纳特(nat)。由定义可知,熵只依赖于 X X X的分布,而与 X X X的取值无关,所以也可将 X X X的熵记作 H ( p ) H(p) H(p),即
H ( p ) = − ∑ i = 1 n p i l o g p i (5.2) H(p)=-\sum_{i=1}^{n}p_{i}logp_i\tag{5.2} H(p)=−i=1∑npilogpi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









