







 阿里举办预训练模型泛化能力挑战赛,关注模型的深度理解和构建。Baseline在导入tensorflow时遇到问题,解决方案是使用tf.compat.v1.logging替换tf.logging,但仍有报错。参赛者需在有限时间内解决兼容性问题,继续模型训练和评估。
阿里举办预训练模型泛化能力挑战赛,关注模型的深度理解和构建。Baseline在导入tensorflow时遇到问题,解决方案是使用tf.compat.v1.logging替换tf.logging,但仍有报错。参赛者需在有限时间内解决兼容性问题,继续模型训练和评估。
阿里中文预训练模型泛化能力挑战赛 Task 1
背景
赛题以自然语言处理为背景,要求选手通过算法实现泛化能力强的中文预训练模型。通过这道赛题可以引导大家更好地理解预训练模型的运作机制,探索深层次的模型构建和模型训练,而不仅仅是针对特定任务进行简单微调。
Baseline报错整理
首先来看import这块的报错
import sys
import os
import tensorflow as tf
from easytransfer import base_model, Config, FLAGS
from easytransfer import layers
from easytransfer import model_zoo
from easytransfer import preprocessors
from easytransfer.datasets import TFRecordReader
from easytransfer.losses import softmax_cross_entropy
from sklearn.metrics import classification_report
import numpy as np
首先注意这里需要额外导入的package包括以下两个
pip install tensorflow-gpu --user ##这样不容易爆权限错误
pip install easytransfer
输出结果如下:
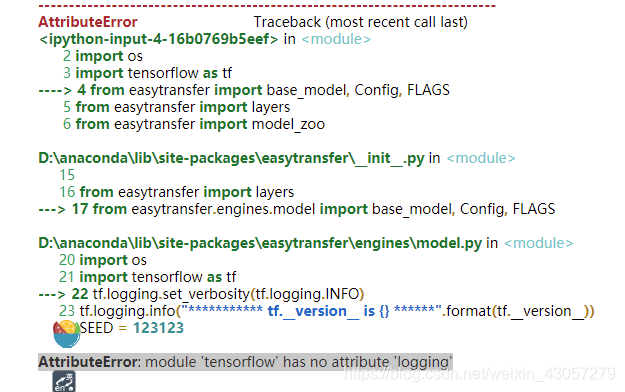
这个是因为tensorflow2.1已经没有tf.logging了
逛坛子得知解决方法如下:
将tf.logging替换成tf.compat.v1.logging
但还是报错 所以这里我还是老老实实根据环境配置的tips
- tensorflow-gpu 1.12.3
- easytransfer 0.1.2
实际情况是没有得到解决
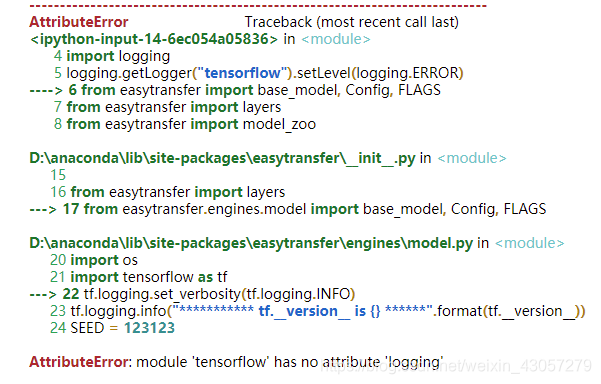
然后在群里看到水哥说baseline有用tf2的tf1.4的有用pytorch的
时间有限这里没有cover
class Application(base_model):
def __init__(self, **kwargs):
super(Application, self).__init__(**kwargs)
self.user_defined_config = kwargs["user_defined_config"]
def build_logits(self, features, mode=None):
preprocessor = preprocessors.get_preprocessor(self.pretrain_model_name_or_path,
user_defined_config=self.user_defined_config)
model = model_zoo.get_pretrained_model(self.pretrain_model_name_or_path)
global_step = tf.train.get_or_create_global_step()
tnews_dense = layers.Dense(15,
kernel_initializer=layers.get_initializer(0.02),
name='tnews_dense')
ocemotion_dense = layers.Dense(7,
kernel_initializer=layers.get_initializer(0.02),
name='ocemotion_dense')
ocnli_dense = layers.Dense(3,
kernel_initializer=layers.get_initializer(0.02),
name='ocnli_dense')
input_ids, input_mask, segment_ids, label_ids = preprocessor(features)
outputs =< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









