







Intro
ViT 模型是一种将 Transformer 结构应用于图片领域,生成图片表征的分类任务。类比文本的tokens处理方式,图片被切割为patches并被线形embed后以序列的形式输入transformer。
Method
Vision transformer
标准的Transformer的输入是 1D sequence 的 token embeddings,图片数据集
x
∈
R
(
H
∗
W
∗
C
)
x \in R^{(H∗W∗C)}
x∈R(H∗W∗C)
变形为
R
N
∗
(
P
2
⋅
C
)
R^N∗(P^2 ⋅C)
RN∗(P2⋅C),本质是一系列被切割的小图片展平,所以这个序列一共包含
N
=
H
W
/
P
2
N=HW/P^2
N=HW/P2
个小图像,每个小图像的维度是
P
2
∗
C
P^2 ∗C
P2∗C。其中,P是图像的维度,C是通道数量,N是sequence长度。这样就处理了 transformer 的维度问题。
再者,transformer用的是固定长度的向量D,因此图片需要再用 trainable linear projection 映射到 D 维度。此外,也可以用 CNN 得到的 feature map 代替 flatten 方法得到图片的sequence表示。
Bert 里 [CLS] 加入sentence embedding 的作用是这个符号学到的表征能够表示文本的语义信息,类似的,图片处理中也加入 [CLS]
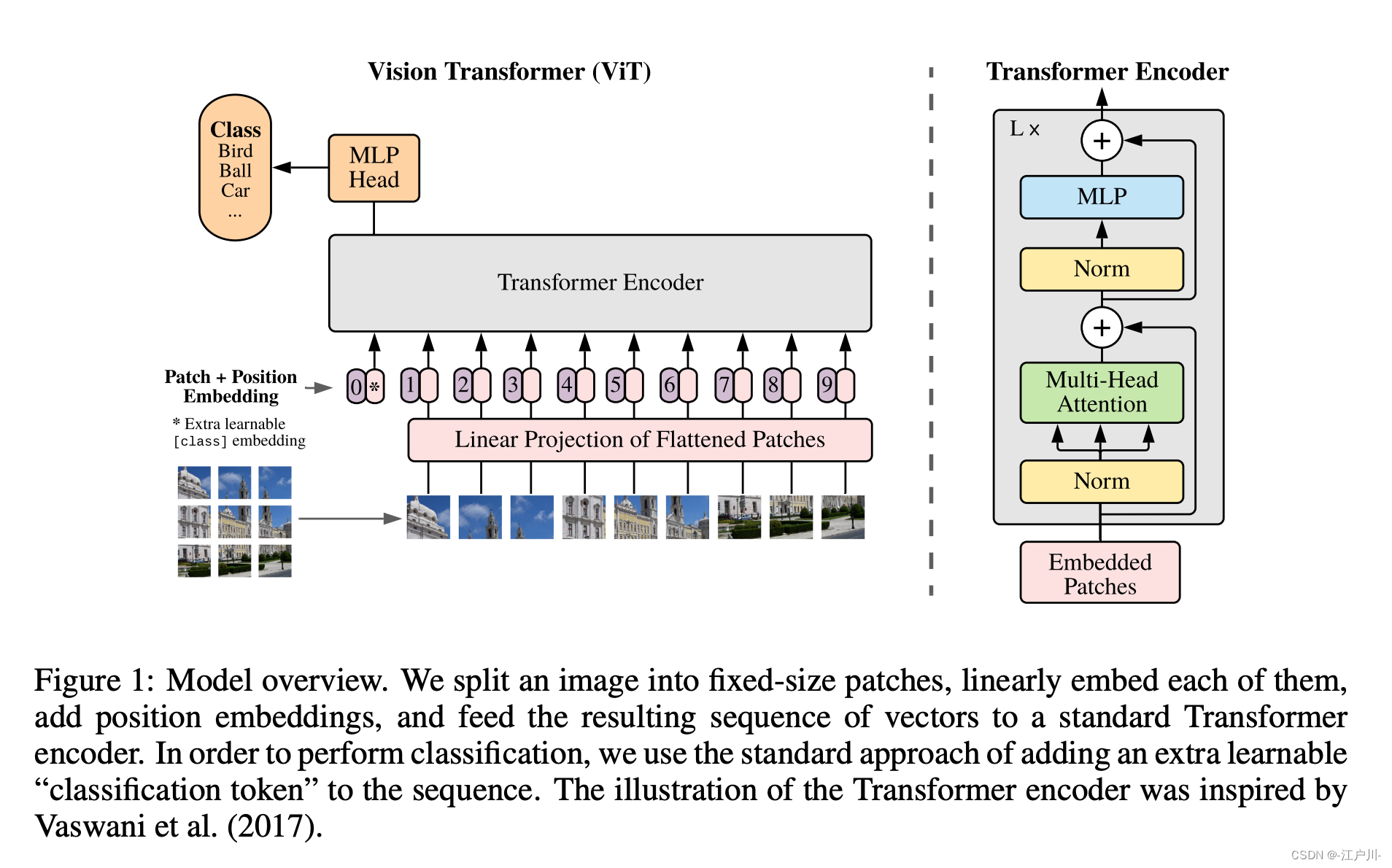
左图的过程可以通过如下公式表示:
-
input 需要 flatten -> linear projection到D维 -> 加入 [CLS] token -> 加入 position 信息
-
做 LN -> multi-head self attention + shortcut
-
做 LN -> MLP
-
做 LN 再输出
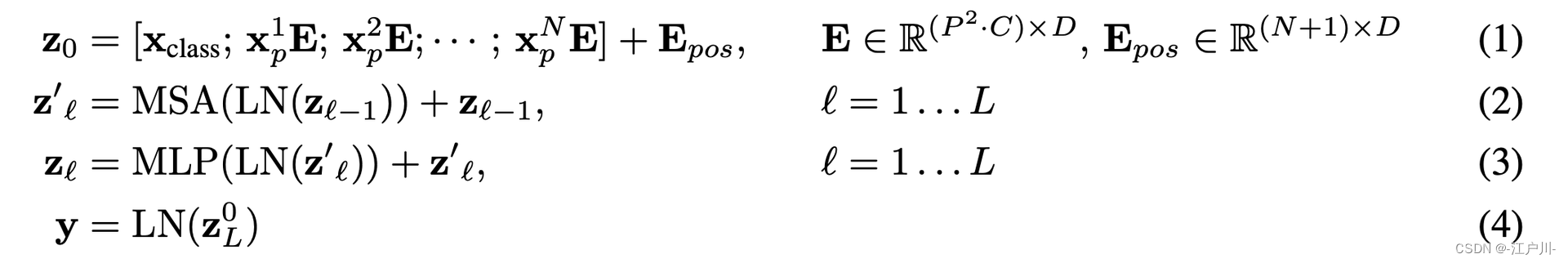
Finetune and higher resolution
在使用 ViT在超大数据集上 pretrain 的模型进行下游任务(小数据集)时,通常会移除 pretrained prediction head 换上一个 zero-initialized D*K 前向传播层, K是下游分类的数量。
对有更高解析度的下游任务图片使用2D interpolation:下游任务具有更高的 resolution 时候通常表现更好,而ViT保持与pretrained model相同大小的 patch size 时,sequence len肯定会变长,那么pos embedding失效,需要做2D 插入.















 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









