







随着模型参数规模与训练数据量的持续增长,大语言模型涌现出上下文学习(In-Context Learning,ICL)能力。该能力,使语言模型无需再针对某个任务特定训练一个模型或者在预训练模型上微调,而是通过上下文,快速适应下游任务。
这种通过页面或者 API 能够及其快速适应下游任务的模式,也被称为“语言模型即服务(LLM as Service)”。
定义
上下文学习(ICL),是一种通过构造特定的 Prompt,使得语言模型理解并学习下游任务的范式。
这个特定的 Prompt,一般包含三部分内容:任务目标、相关演示实例与输出格式,而上下文学习的关键点,也就自然落在了:“如何设计有效的 Prompt,以快速准确的引导模型理解下游任务并生成符合要求的输出”。
可以说,基于以上优点,上下文学习成为提示词工程(Prompt Engineering)中最重要的一环之一,且广泛应用于大模型的各垂类任务中。
分类
在上下文学习中,一个重要的部分就是相关演示实例。如下示例所示 (图3.5 上下文学习示例),通过将示例、目标和格式的结合,形成提示词(Prompt)输入给大模型。
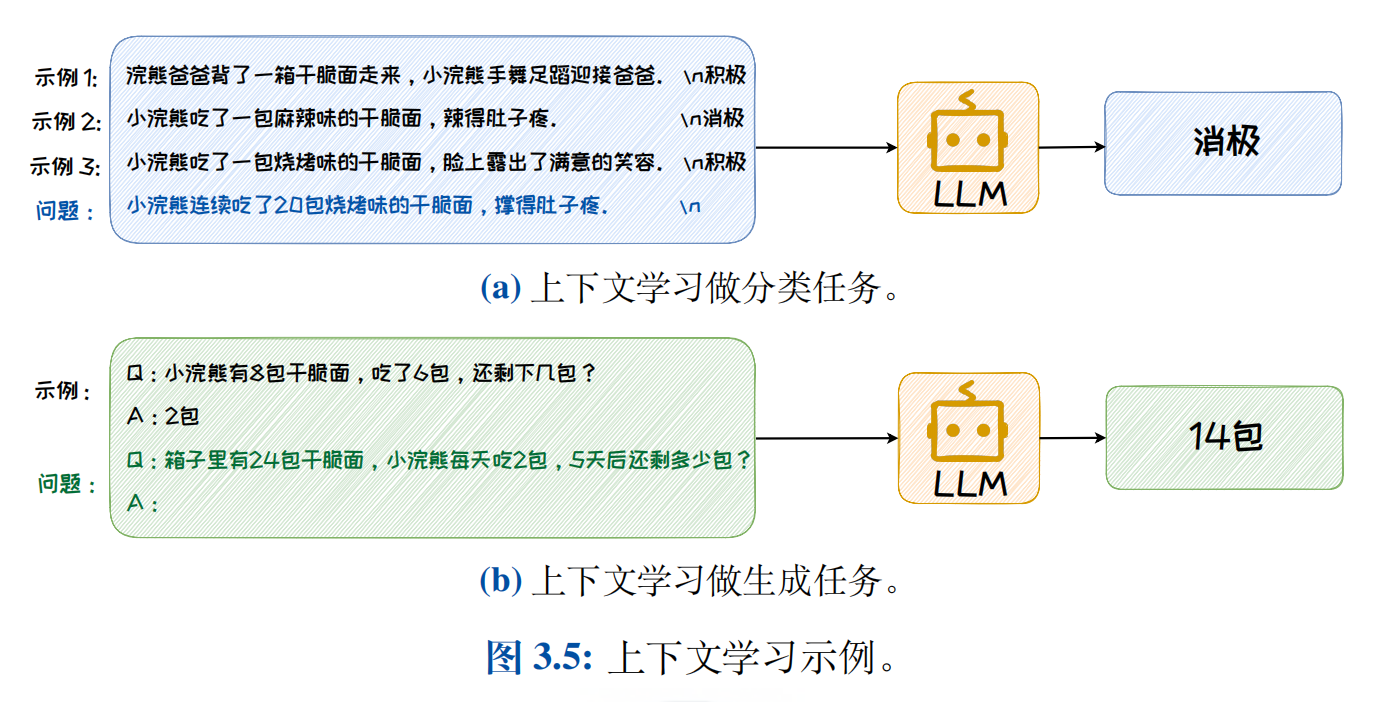
- (a)示例中,使用模型通过情感分析进行分类任务
- (b)示例中,通过数学运算能力,提供示例使用模型进行生成任务
在演示实例这个维度中,按照实例的数量,可以将上下文学习分为多种形式:零样本(Zero-Shot)、**单样本(One-Shot) 以及少样本(Few-Shot)**上下文学习。
零样本上下文学习
又称 Zero-Shot,在该形式中,仅需在提示词中提供 “任务目标” 和 “输出格式”,无需提供任何 “相关示例”。零样本学习完全依赖于大语言模型能力,但经验来看,在处理复杂任务时一般效果不理想。

单样本上下文学习
又称 One-Shot,在该形式中,示例中仅需提供一个 “相关示例”,贴合举一反三的人类学习模式,结合 “任务目标” 和 “输出格式”,构成提示词,引导模型生成内容。但单样本学习强依赖于示例相对于任务的代表性,带有主观偏见。

少样本上下文学习
又称 Few-Shot,在该形式中,提供少量的 “相关示例”(通常几个到几十个),结合 “任务目标” 和 “输出格式”,显著提升模型在特定任务上的表现。但是,随着示例内容的增加,tokens 的增大,会显著增大大语言模型推理成本,示例的代表性与多样性也会影响最终的生成效果。

可以说,上下文学习技术(ICL)的分类,主要依据提供的 “相关示例” 数量。
原因
上下文学习(ICL)技术为何奏效?
斯坦福大学团队于ICLR 2022发表的研究《An Explanation of In-context Learning as Implicit Bayesian Inference》提出了一种上下文学习(ICL)核心机制的想法:该技术本质是通过隐式贝叶斯推理实现的概率建模过程。其有效性源于大语言模型在预训练阶段已从海量文本中内化了丰富的潜在概念,当提供包含示例的上下文提示时,模型能够通过示例间的统计关联快速锚定与当前任务最相关的知识结构,从而将预训练阶段习得的抽象概念转化为具体推理能力,最终实现对目标问题的概率预测与内容生成。
e . g . e.g. e.g. 举例来说,图 3.5 (a) 之所以可以根据内容进行情感分析并完成分类任务,是因为模型在预训练时已接触到充足的情感内容、抽象出了情感概念。而当模型推理时,借助提供的提示词,锚定了情感的相关概念,并基于这些概念,生成问题答案。
选择
那么,如果我们要使用上下文学习方法,提供 “演示示例” 作为提示词内容部分之一,怎样有效提升引导模型的质量,规避示例的主观性带来的偏向以及多样性缺乏带来的影响?
总结来说,“演示示例” 的选择,主要依靠相似性和多样化。
相似性
相似性指挑选出与待解决问题最相关的示例。相似可以从多个维度与层面度量,比如语言层面(关键词匹配、语义相似度),结构的相似性等等。通过选取相似的示例,提供最佳参照,引导模型更精准生成内容。
多样化
多样化要求模型所选示例尽量涵盖广泛的内容以及结果的所有可能。多样化的示例能够帮助模型从不同的角度理解任务,增强模型对某领域的广泛认知,增强解决多种类别结果的能力。
相似性和多样性就类似准确率和查全率,一个要求垂类关联性强,另一个要求覆盖领域内容广。
方案
示例选择的具体方案,有如下三个方案供参考:
- 直接检索
- 聚类检索
- 迭代检索
直接检索
直接检索依据候选示例与待解决问题间的相似性对候选示例进行排序,然后选取排名靠前的 K 个示例。直接检索的代表性方法如 KATE,其主要步骤如下:
- 利用 RoBERTa 对待解决问题和候选示例进行编码
- 然后通过计算待解决问题编码和候选示例编码间的余弦相似度计算二者相似度
- 基于评分选择最高的 K 个示例作为上下文学习的演示实例
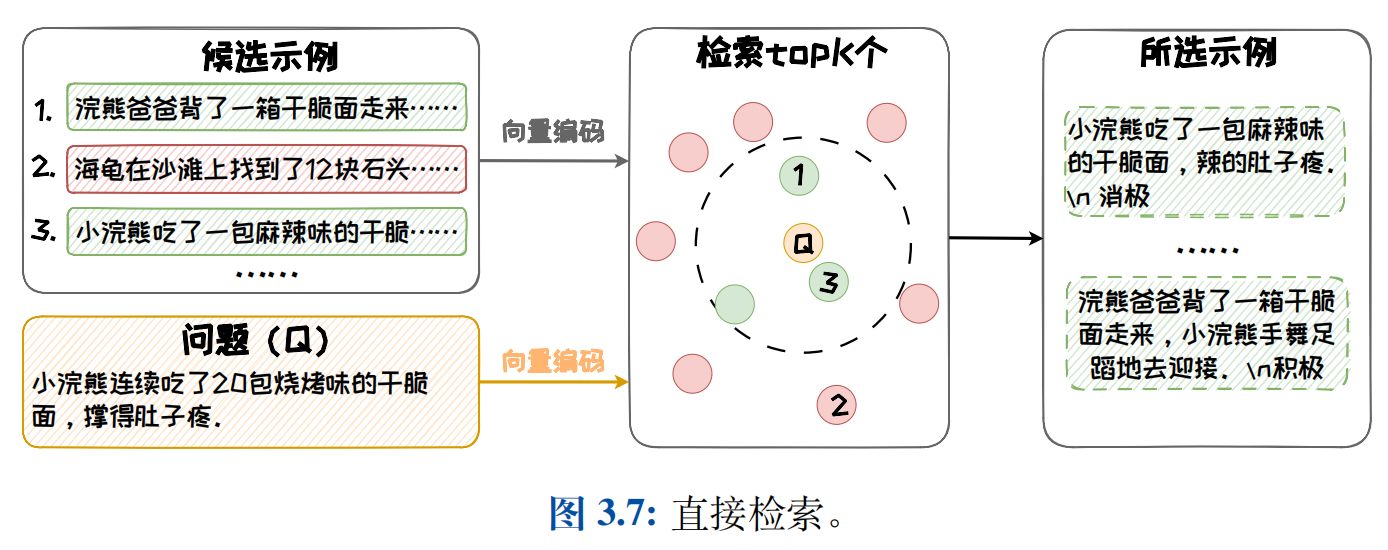
直接检索方法优点在于简单易操作,但是其未对示例的多样性进行考虑,选择出的示例趋向同质化缺乏多样性。
聚类检索
聚类检索方法通过先聚类后检索的整体方案,来缓解直接检索存在的 “缺乏多样性” 的问题。具体步骤首先会把所有候选示例划分为 K 个簇,然后从每个簇中选取最相似的一个示例。Self-Prompting 是其中的代表性方法,其具体步骤如下:
- 首先将候选示例和待解决问题编码成向量形式
- 运用 K-Means 算法把示例集合聚为 K 个簇
- 依照问题与示例之间的余弦相似度,从每个簇中选取与问题最相似的示例,由此得到 K 个示例
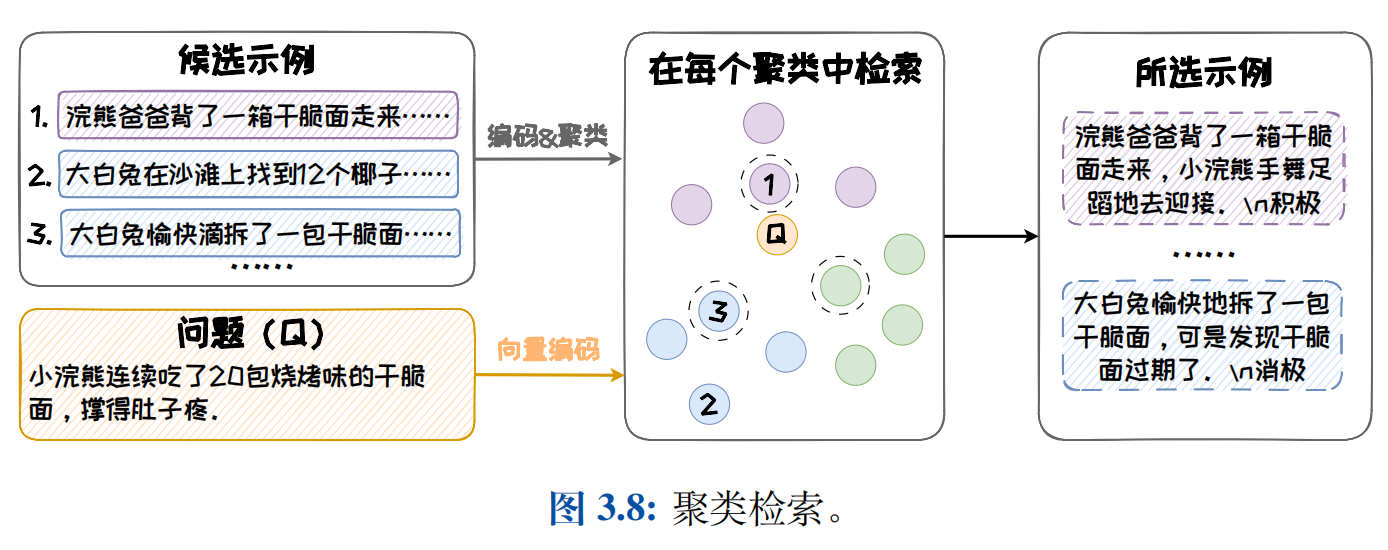
聚类检索方法大大改善了直接检索方法存在的缺乏多样性的问题,但势必有一些簇与问题并不相似,由此会侧面影响模型生成内容的准确性。
迭代检索
直接检索和聚类检索在相似性和多样性之间往往顾此失彼。所以为了兼容直接检索的专一和聚类检索的多样,迭代检索应运而生。迭代检索首先挑选与问题高度相似的示例,随后在迭代过程中,结合当前问题和已选示例,动态选择下一个示例,从而确保所选示例的相似性和多样性。RetICL 是迭代检索的代表性方法,具体步骤如下:
- RetICL首先根据当前问题初始化基于 LSTM 检索器的内部状态


















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











