







今天,为大家深入浅出地讲明白上亚运的经典 IP《梦三国 2》,到底应用了哪些来自网易数智的 AI 黑科技。看完你就会觉得:原来做 AI,我也行!
方案概述
游戏作为 AI 落地最佳的试验田,近年来已经产生了多个极具影响力的案例,如《星际争霸 2》中的 AlphaStar、《Dota2》中的 OpenAI Five 等,各大游戏厂商更是早早开始了 AI 实验室的布局。但与之相对的,国内还没有跑出特别标杆的游戏 AI 应用实践。随着 AI + 游戏落地案例越来越多,AI 在游戏中的商业价值亦成为海内外各大厂商的共识。
基于自研的分布式强化学习训练框架,为超大型 MOBA 游戏《梦三国 2》训练出高水平游戏 AI 智能体,满足游戏中迫切的陪玩、对决需求。
游戏环境的开发
为了训练强化学习 AI 机器人,首先需要将游戏接入训练框架中,因此游戏本身需要开发一些额外的功能。
我们将需要开发的游戏环境称为 GameCore,其基本定义为:在游戏客户端基础上,添加了与 AI 服务器通信交互功能。通过 GameCore 将游戏状态发送给 AI,AI 收到状态后做出一次决策,决策返回至 GameCore 中并得到执行,如此往复。
由于训练阶段需要同时开启多个 GameCore,为满足大量 GameCore 同时训练的需求,必须使用大规模分布式训练框架。
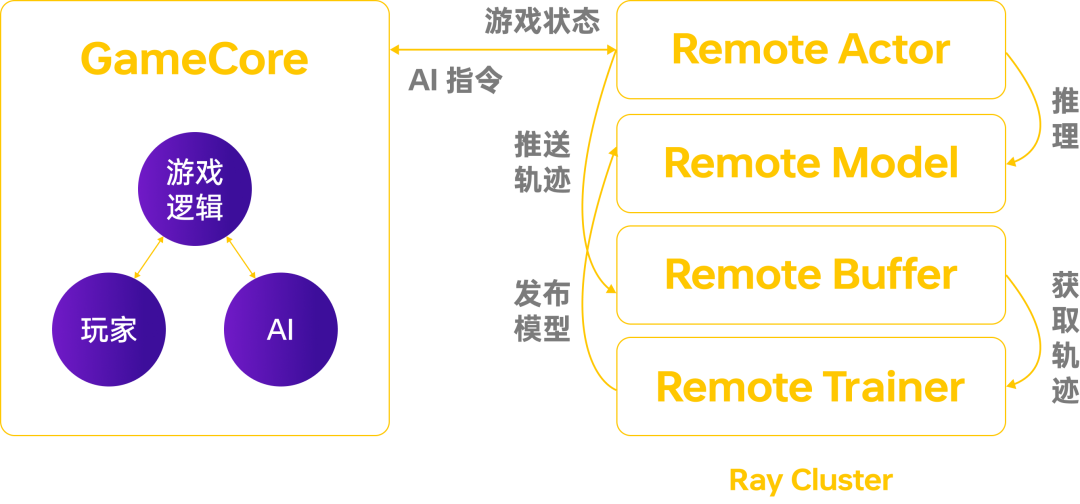
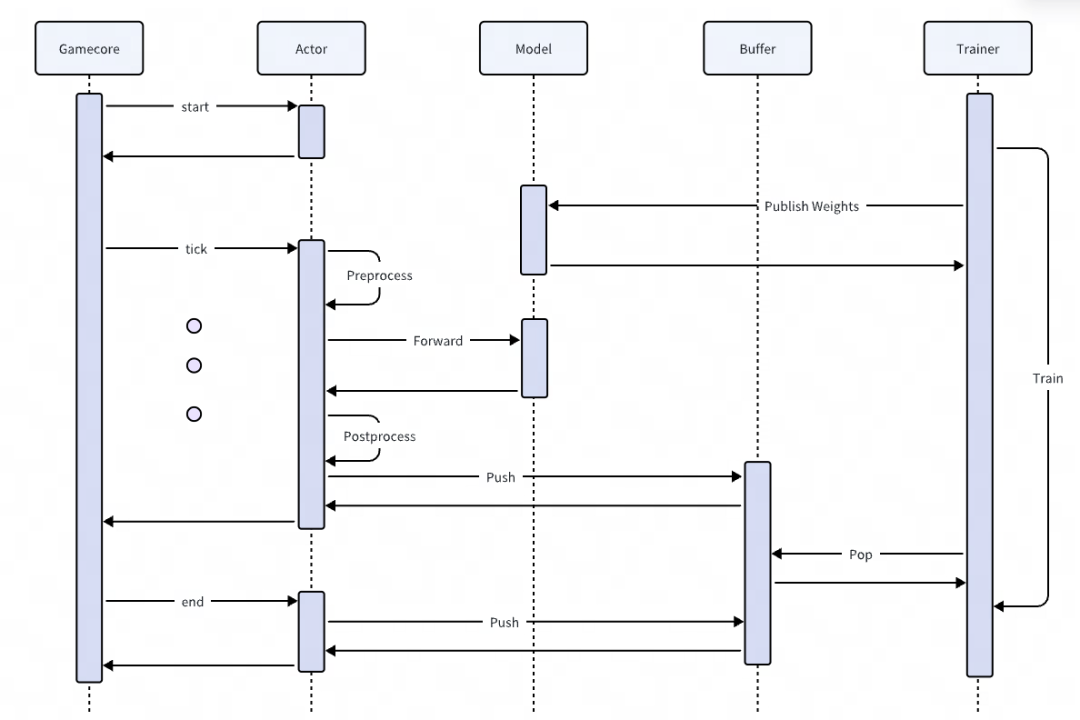
训练框架的接入
游戏 AI 的训练离不开模仿学习和强化学习,而这些都依赖于海量的数据、算力,以及高效的训练算法。分布式强化学习框架就是要提供这样一个高效的训练平台,支持游戏仿真环境并行采样,支持流水线式数据处理,支持高吞吐低延迟的模型预测以及支持多机多卡并行训练。
现有的开源强化学习框架比如 Ray(RLlib)、OpenAI Baselines、PyMARL 等,更多的是实验和研究性质,满足了强化学习算法探索、效果对齐等需求,特点是通用性强,算法可拓展性高,但面对真实的游戏场景往往不够实用。
为了解决以上问题,数智自研了分布式强化学习训推一体化框架 Bray。Bray 面向真实的游戏 AI 落地进行优化,在算法侧做减法,保证框架的简单易于上手,同时用模块化设计理念保证了框架的高可用。具体地,Bray 解决了以下几个痛点问题:
1. 统一训练和推理框架
游戏 AI 的研发上线往往经过训练和部署两个阶段,部署阶段的特征处理和模型推理逻辑是训练的子集,二者的代码可以复用。为了进一步降低训练到部署的迁移成本,保证迁移的正确性,Bray 在框架层面支持了训练到部署的无缝迁移
2. 规范化游戏 AI 的接入流程
一个游戏 AI 的接入涉及到游戏开发、算法对接、性能优化等,通过规范接入过程的流程和接口,Bray 实现了各个模块的并行接入、测试和验证,缩短了游戏 AI 的接入周期
3. 模块化设计和简单易用的 API
Bray 中明确定义了 Actor、Model、Buffer、Trainer 等概念,对应到 Python 中的类和模块,模块间充分解耦,让游戏接入、算法调优和性能优化可以独立进行。此外模块化设计保证了框架的高可拓展性,快速支持 SelfPlay 和 League 等多智能体训练
由于《梦三国 2》游戏环境在强化学习中属于经典的稀疏奖励问题(sparse reward), 即在一个完整的 episode 中,绝大部分 step 的 reward 为 0,这导致智能体(下称“agent”)从 init state(初始状态)开始的随机探索效率非常低,极大降低了训练效率。
我们首先使用状态完全随机初始化,如对于一个打野英雄,它可能会被直接传送到一个残血的野怪附近;从而极大提升有效样本在前期探索中的比例。
但这种方法无法解决的问题是,随着训练的迭代,agent 对某些初始状态的探索已足够充分,我们需要更加关注 agent 探索不够充分的状态,比如对于打野英雄,它很快就会学会刷野,但却要花费非常多的时间来学会如何 gank 及反野,因此我们进一步引入了加权随机初始化,具体地:
我们设计了一个打分函数,用于给每个初始状态打分,agent 对该状态的收敛度越高,分数便越低,该初始状态及分数会被存储在一个特殊的 buffer 中;在环境每次 reset 时,我们都会以一定的概率从 buffer 中以分值为权重采样出一个初始状态,由此,agent 可以更加专注于探索不充分的状态,训练效率得到极大提升。
风格多样性的微调
在过去的方法中,如果我们想让 agent 学会一种新的策略(风格),往往通过设计一套新的奖励函数来实现,并且过程中还需要根据 agent 实际表现对奖励函数的权重进行不断微调重新训练。
据此,我们采用了一种新的方法来避免耗费过多的时间在调整权重上,具体地:
我们为奖励函数的组成部分中,所有会影响策略风格的实体添加一个系数,比如推掉外层一塔便是一个实体;在每个 episode 开始时,我们为每一个 player 重置一套新的风格系数,并将风格系数添加至神经网络的输入中,由此让神经网络拟合风格系数与策略表现之间的映射关系,在模型收敛后,我们便可以通过观察每一组风格系数对应的策略来找到多组风格迥异的模型。
为了满足不同段位玩家的体验,我们对 agent 的能力进行了难度分级,具体地:
我们希望不同难度 agent 的区分度主要表现在 agent 对游戏的理解能力及操作能力,即大局观和微操。
据此,我们首先对神经网络的输入加入了层次噪声,来使得 agent 对局势判断出现误差,从而模拟不同段位玩家的大局观;进一步地,我们对神经网络的输出加入了分层延迟及扰动,从而模拟不同段位玩家的手速及微操能力。
最后,我们多组难度的模型投放到线上与真实玩家对战,选取天梯分稳定在某个段位的模型作为该段位的分级模型。
强化学习方案优势
-
通过让游戏 AI 智能体在每局比赛中都“精彩地输掉”,解决公平竞技游戏中“双方都想赢那谁来输”的问题
-
为玩家分配更加贴近其真实水平的智能体,让玩家获得更真实的对抗体验,酣畅淋漓地获胜!
-
通过优化训练方案,极大降低训练智能体需要的机器成本
戳我即可收获《网易数智年度技术精选》
《 2023 中国移动游戏私域运营指南 · 启动篇》
《网易数智游戏AI实践指南》更多干货内容,可以✉✉~~

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









